简单的方法爬取b站dnf视频封面步骤解释
2018-02-27 23:10
323 查看
这随笔代码链接:http://www.cnblogs.com/yinghualuowu/p/8186375.html
首先我们要知道,一个分区封面显示到底在哪里可以找到。
很明显,查看审查元素并不能找到封面。这个时候应该想到封面是动态加载的。
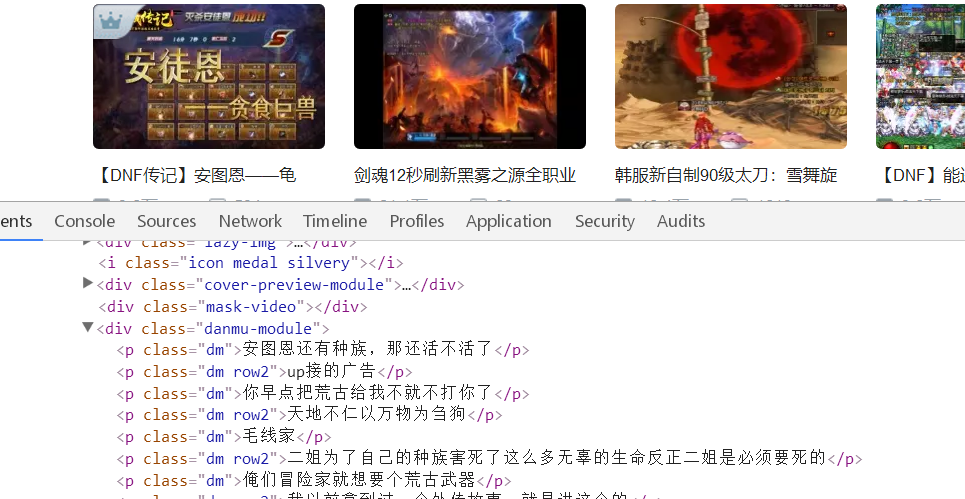
再次去Network寻找,我们发现这样一个JS。这是右侧热门视频封面的内容,点开之后存在pic:正是封面的链接。
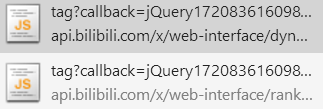

进行json解析之后,判定pic在data>archives结构下。这个时候链接是有了,那么将如何把Json拿出来呢?

让我们观察一下原来的信息,除去JQuery........()这层,里面就是json字符串了,既然如此简单,那么我们就...

查找开头第一个(,然后截取至最后一个),里面不就是了吗?
然后进行翻页判断,我们尝试点开第一页和后面几页,看看不同。pn数字貌似变化很有规律啊。
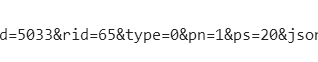
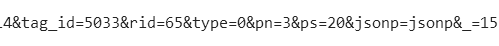
于是...
然后,就没有了。其实要高清大图的话,你需要点进去一个视频,然后审查元素,后面我会写一个输入av号来获取封面的代码
首先我们要知道,一个分区封面显示到底在哪里可以找到。
很明显,查看审查元素并不能找到封面。这个时候应该想到封面是动态加载的。
再次去Network寻找,我们发现这样一个JS。这是右侧热门视频封面的内容,点开之后存在pic:正是封面的链接。
进行json解析之后,判定pic在data>archives结构下。这个时候链接是有了,那么将如何把Json拿出来呢?
让我们观察一下原来的信息,除去JQuery........()这层,里面就是json字符串了,既然如此简单,那么我们就...
查找开头第一个(,然后截取至最后一个),里面不就是了吗?
def instr(keystr):
st=keystr.find('(')+1
strhtml=keystr[st:len(keystr)-1]
return strhtmldef picsave(strJson,number): global cnt strdic=strJson['data']['archives'] num=len(strdic) for i in range(0,num,1): cnt=cnt+1 strdic=strJson['data']['archives'][i] print(strdic['pic']) urllib.request.urlretrieve(strdic['pic'],'E:\图片\dnf\%s.jpg'%(cnt))
然后进行翻页判断,我们尝试点开第一页和后面几页,看看不同。pn数字貌似变化很有规律啊。
于是...
def urlget(num):
for i in range(1,num,1):
url='https://api.bilibili.com/x/tag/ranking/archives?callback=jQuery172014070206081723846_1514982701564&tag_id=5033&rid=65&type=0&pn='+str(i)+'&ps=20&jsonp=jsonp&_=1514982702144'
response=urllib.request.urlopen(url)
html=response.read().decode('utf-8')
html=instr(html)
strJson=eval(html)
picsave(strJson,i)然后,就没有了。其实要高清大图的话,你需要点进去一个视频,然后审查元素,后面我会写一个输入av号来获取封面的代码

相关文章推荐
- Python 简单的方法爬取b站dnf视频封面
- 摄像头、视频采集和摄像设备图像质量判断的几种简单有效目测方法
- 抽象工厂,工厂方法,简单工厂的解释
- eclipse新建maven web项目步骤、出现错误解决方法及maven settings简单配置
- 获取bilibili视频封面的方法
- TCP通信过程中各步骤的状态---(简单解释)
- Android_视频播放的简单使用方法
- JS的call方法的作用解释,简单易懂
- vso downloader怎么安装?安装步骤+视频下载方法【图】
- 8月17日 使用ISE进行FPGA开发的最简单步骤视频的说明
- 制作电子相册(sd卡读取bmp图片显示在tft彩屏上)读取fat32的步骤非常简单的方法
- 基于vue2.0实现音乐/视频播放进度条组件的思路及具体实现方法+代码解释
- A站文章围观量&B站视频播放量的简单爬虫想法
- html制作简单框架网页二 实现自己的影音驿站 操作步骤及源文件下载 (可播放mp4、avi、mpg、asx、swf各种文件的视频播放代码)
- 下载网页视频而不需要通过迅雷等软件 (基于python3 方法简单迅速)
- 让视频也能响应式最简单的方法——Fitvids
- 最简单的软件封面制作方法
- 使用V4L进行简单视频捕捉的基本步骤
- 超级简单的下载今日头条和西瓜视频的方法
- 实现视频长时间播放而显示器不会关闭或者屏保出现的简单方法