吴恩达Coursera深度学习(3-1)机器学习策略(1)
2018-02-26 14:06
633 查看
转载博客:http://blog.csdn.net/Koala_Tree
Week 1机器学习策略1
目录
1正交化
2单一数字评估指标
3满足和优化指标
4训练开发测试集
5改变开发测试集和评估指标
6与人类表现做比较
7改善模型的表现
正交化或正交性是一种系统设计属性,其确保修改算法的指令或部分不会对系统的其他部分产生或传播副作用。 相互独立地验证使得算法变得更简单,减少了测试和开发的时间。



训练、开发、测试集的设置会对产品带来非常大的影响;
在选择开发集和测试集时要使二者来自同一分布,且从所有数据中随机选取;
所选择的开发集和测试集中的数据,要与未来想要或者能够得到的数据类似,即模型数据和未来数据要具有相似性;
设置的测试集只要足够大,使其能够在过拟合的系统中给出高方差的结果就可以,也许10000左右的数目足够;
设置开发集只要足够使其能够检测不同算法、不同模型之间的优劣差异就可以,百万大数据中1%的大小就足够;


但实际情况是对,我们一直使用的是网上下载的高质量的图片进行训练;而当部署到手机上时,由于图片的清晰度及拍照水平的原因,当实际测试算法时,会发现算法B的表现其实更好。
如果在训练开发测试的过程中得到的模型效果比较好,但是在实际应用中自己所真正关心的问题效果却不好的时候,就需要改变开发、测试集或者评估指标。
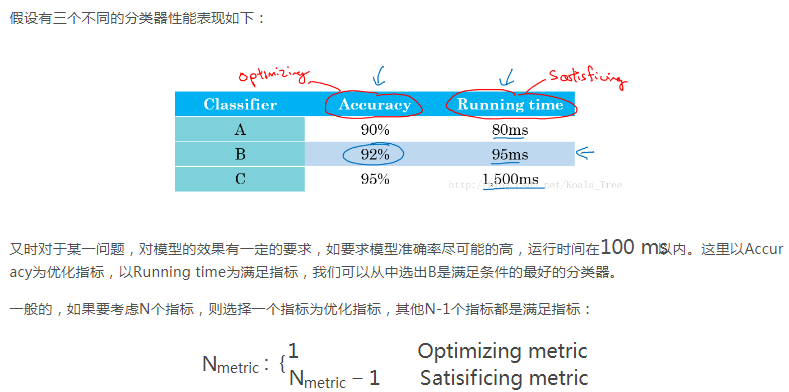
Guideline:
1.定义正确的评估指标来更好的给分类器的好坏进行排序;
2.优化评估指标。
假设针对两个问题分别具有相同的训练误差和交叉验证误差,如下所示:
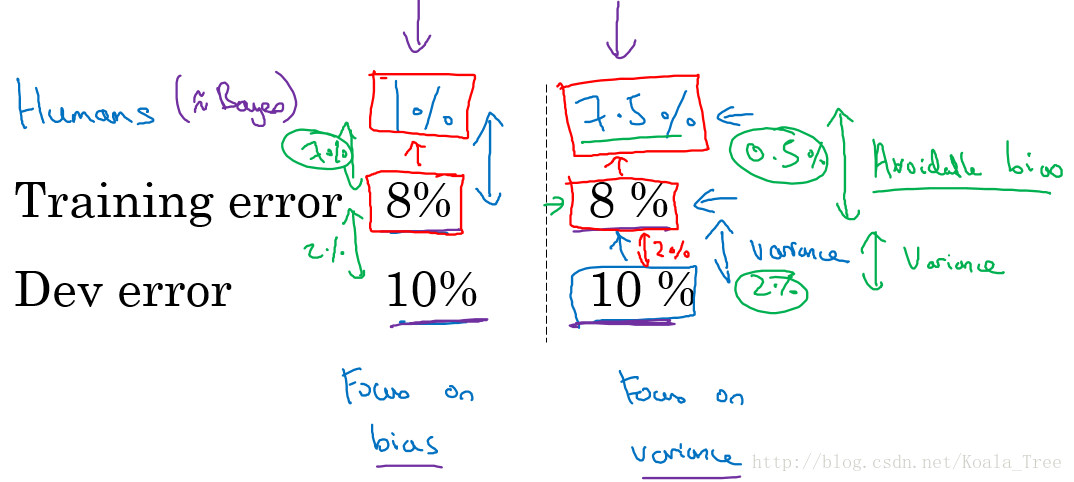

在减小误诊率的背景下,人类水平误差在这种情形下应定义为:0.5% error;
如果在为了部署系统或者做研究分析的背景下,也许超过一名普通医生即可,即人类水平误差在这种情形下应定义为:1% error;
总结:
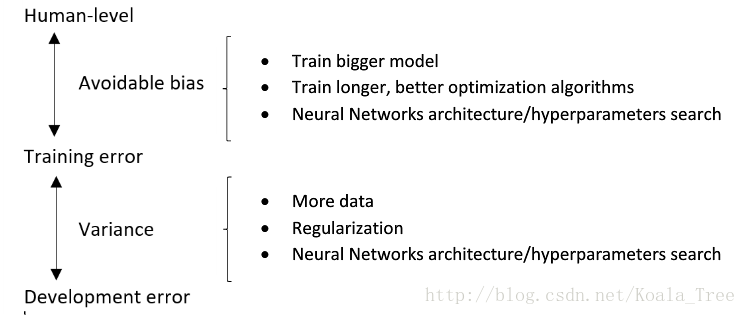
对人类水平误差有一个大概的估计,可以让我们去估计贝叶斯误差,这样可以让我们更快的做出决定:减少偏差还是减少方差。
而这个决策技巧通常都很有效果,直到系统的性能开始超越人类,那么我们对贝叶斯误差的估计就不再准确了,再从减少偏差和减少方差方面提升系统性能就会比较困难了。


Class 3:结构化机器学习项目
Week 1:机器学习策略(1)
目录
Class 3结构化机器学习项目Week 1机器学习策略1
目录
1正交化
2单一数字评估指标
3满足和优化指标
4训练开发测试集
5改变开发测试集和评估指标
6与人类表现做比较
7改善模型的表现
1、正交化
表示在机器学习模型建立的整个流程中,我们需要根据不同部分反映的问题,去做相应的调整,从而更加容易地判断出是在哪一个部分出现了问题,并做相应的解决措施。正交化或正交性是一种系统设计属性,其确保修改算法的指令或部分不会对系统的其他部分产生或传播副作用。 相互独立地验证使得算法变得更简单,减少了测试和开发的时间。
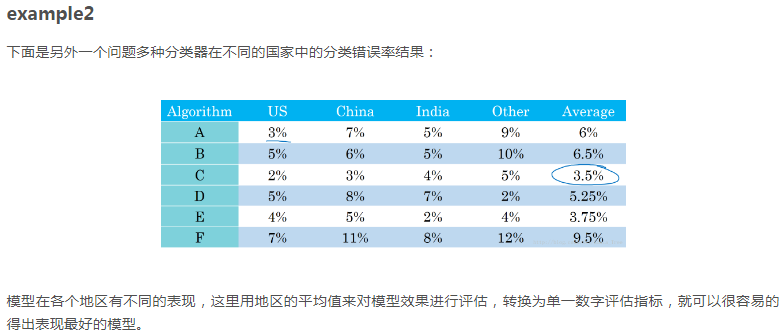
2、单一数字评估指标
在训练机器学习模型的时候,无论是调整超参数,还是尝试更好的优化算法,为问题设置一个单一数字评估指标,可以更好更快的评估模型。3、满足和优化指标
4、训练、开发、测试集
训练、开发、测试集选择设置的一些规则和意见:训练、开发、测试集的设置会对产品带来非常大的影响;
在选择开发集和测试集时要使二者来自同一分布,且从所有数据中随机选取;
所选择的开发集和测试集中的数据,要与未来想要或者能够得到的数据类似,即模型数据和未来数据要具有相似性;
设置的测试集只要足够大,使其能够在过拟合的系统中给出高方差的结果就可以,也许10000左右的数目足够;
设置开发集只要足够使其能够检测不同算法、不同模型之间的优劣差异就可以,百万大数据中1%的大小就足够;
5、改变开发、测试集和评估指标
在针对某一问题我们设置开发集和评估指标后,这就像把目标定在某个位置,后面的过程就聚焦在该位置上。但有时候在这个项目的过程中,可能会发现目标的位置设置错了,所以要移动改变我们的目标。但实际情况是对,我们一直使用的是网上下载的高质量的图片进行训练;而当部署到手机上时,由于图片的清晰度及拍照水平的原因,当实际测试算法时,会发现算法B的表现其实更好。
如果在训练开发测试的过程中得到的模型效果比较好,但是在实际应用中自己所真正关心的问题效果却不好的时候,就需要改变开发、测试集或者评估指标。
Guideline:
1.定义正确的评估指标来更好的给分类器的好坏进行排序;
2.优化评估指标。
6、与人类表现做比较
可避免偏差假设针对两个问题分别具有相同的训练误差和交叉验证误差,如下所示:
在减小误诊率的背景下,人类水平误差在这种情形下应定义为:0.5% error;
如果在为了部署系统或者做研究分析的背景下,也许超过一名普通医生即可,即人类水平误差在这种情形下应定义为:1% error;
总结:
对人类水平误差有一个大概的估计,可以让我们去估计贝叶斯误差,这样可以让我们更快的做出决定:减少偏差还是减少方差。
而这个决策技巧通常都很有效果,直到系统的性能开始超越人类,那么我们对贝叶斯误差的估计就不再准确了,再从减少偏差和减少方差方面提升系统性能就会比较困难了。
7、改善模型的表现

相关文章推荐
- 吴恩达Coursera深度学习课程 DeepLearning.ai 提炼笔记(3-1)-- 机器学习策略(1)(转)
- 吴恩达Coursera深度学习(3-2)机器学习策略(2)
- 吴恩达Coursera深度学习课程 DeepLearning.ai 提炼笔记(3-2)-- 机器学习策略(2)
- 吴恩达Coursera深度学习课程 DeepLearning.ai 提炼笔记(3-2)-- 机器学习策略(2)(转)
- 吴恩达Coursera深度学习课程 DeepLearning.ai 提炼笔记(3-1)-- 机器学习策略(1)
- 吴恩达深度学习笔记 course3 week1 机器学习策略(1)
- 吴恩达《深度学习-结构化机器学习项目》2--机器学习策略(2)
- 吴恩达深度学习笔记 course3 week2 机器学习 策略(2)
- 吴恩达Coursera深度学习课程 DeepLearning.ai 提炼笔记(4-1)-- 卷积神经网络基础
- 吴恩达Coursera深度学习课程 DeepLearning.ai 提炼笔记(2-1)-- 深度学习的实践方面
- 吴恩达Coursera深度学习(4-4) 特殊应用:人脸识别和神经风格迁移
- coursera 吴恩达 -- 第一课 神经网络和深度学习 :第三周课后习题 Planar data classification with a hidden layer
- 吴恩达神经网络和深度学习课程自学笔记(八)之机器学习策略
- 吴恩达Coursera深度学习课程 DeepLearning.ai 提炼笔记(1-2)-- 神经网络基础(转载)
- 吴恩达Coursera深度学习课程 DeepLearning.ai 提炼笔记(4-2)-- 深度卷积模型
- Coursera吴恩达《构建机器学习项目》课程笔记(2)-- 机器学习策略(下)
- 吴恩达Coursera深度学习(4-2)编程练习
- 神经网络与深度学习编程练习(coursera 吴恩达 )(2)
- coursera 吴恩达 -- 第一课 神经网络和深度学习 :第四周课后习题 Deep Neural Network - Application v3
- 吴恩达Coursera深度学习课程 DeepLearning.ai 提炼笔记(4-2)-- 深度卷积模型