用正则表达式匹配url网址
2018-02-26 09:50
441 查看
<div class="b_cont">
<p>
最新录制的<a href='' target='_blank'>《VN线波段系统》</a>已经制作完毕上传<a href='' target='_blank'>唯奥学院</a>了,这套系统我做出来有5年多了,这还是首次在网络上授课,一个波段的方向和体系,其实都代表着内在的核心,已经预订的同学可以观看,订阅完毕之后没有时间限制,没有次数限制,观看地址:
</p>
</div>
<script src="js/jquery-1.8.3.min.js"></script>
<script>
$(document).ready(function(){
$(".b_cont").find("p").each(function(){
var con = $(this).html();
// 去掉无用的空格
con = con.replace(/ /ig, "");
$(this).attr("style"," 'line-height': '2!important', 'font-size': '18px!important', 'color': '#000000!important', 'font-family': 'Microsoft Yahei,'微软雅黑',sans-serif!important");
// 判断是否是公司的网址 不是不进行添加a
if(con.indexOf("想要匹配的网址")>=0)
{
if(con.indexOf("html")>=0){
var hre ;
// 匹配url的正则网址
var reg = /((ht|f)tps?:)\/\/[-A-Za-z0-9+&@#/%?=~_|!:,.;]+[-A-Za-z0-9+&@#/%=~_|]/g;
// 配出正确的url
hre = con.match(reg);
// 把正确的url替换成“”
con =con.replace(reg,"");
if($(this).find("a").attr('href')==hre[0]){
if($(this).find("a").html().indexOf("http://www.wevall.com")>=0){
}else{
// 添加a标签
var val="<a>"+hre[0]+"</a>";
$(this).html(con+val)
$(this).find("a").attr('href',hre[0]);
}
}else{
var val="<a>"+hre[0]+"</a>";
$(this).html(con+val)
$(this).find("a").attr('href',hre[0]);
}
}else{
var hre1;
var reg1 = /http:.+?com/;
hre1 = con.match(reg1);
con = con.replace(reg1,"");
if($(this).find("a").attr('href')==hre1[0]){
if($(this).find("a").html().indexOf("http://www.wevall.com")>=0){
}else{
var val1="<a>"+hre1[0]+"</a>";
$(this).html(con+val1)
$(this).find("a").attr('href',hre1[0]);
}
}else{
var val1="<a>"+hre1[0]+"</a>";
$(this).html(con+val1)
$(this).find("a").attr('href',hre1[0]);
}
}
}
});
})网上流传着多种匹配URL的正则表达式版本,但我经过试验,最好用的还是从stackoverflow上查到的:(https?|ftp|file)://[-A-Za-z0-9+&@#/%?=~_|!:,.;]+[-A-Za-z0-9+&@#/%=~_|]IP地址、前后有汉字、带参数的,都是OK的。另外几个有问题的版本:
摘自微软MSDN:
(ht|f)tp(s?)\:\/\/[0-9a-zA-Z]([-.\w]*[0-9a-zA-Z])*(:(0-9)*)*(\/?)([a-zA-Z0-9\-\.\?\,\'\/\\\+&%\$#_]*)?带参数的匹配有问题。
百度知道中有人回答的:
http://([\w-]+\.)+[\w-]+(/[\w- ./?%&=]*)?有严重的汉字问题。
另外,如果只是想匹配URL中的域名部分,则可以用这个:
((([A-Za-z]{3,9}:(?:\/\/)?)(?:[-;:&=\+\$,\w]+@)?[A-Za-z0-9.-]+(:[0-9]+)?|(?:www.|[-;:&=\+\$,\w]+@)[A-Za-z0-9.-]+)((?:\/[\+~%\/.\w-_]*)?\??(?:[-\+=&;%@.\w_]*)#?(?:[\w]*))?)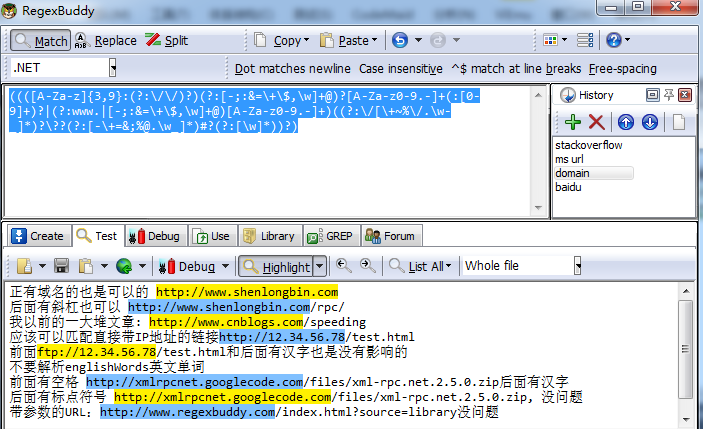
转载地址:https://www.cnblogs.com/speeding/p/5097790.html

相关文章推荐
- asp.net中匹配URL网址的正则表达式
- JS 正则表达式(学习笔记2)匹配网址url参数
- 正则表达式,匹配中文字符、手机号、Email地址、网址URL、HTML标记、国内电...
- 正则表达式 匹配URL或者网址
- 正则表达式匹配域名、网址、url
- 使用正则表达式来匹配URL或者网址
- 正则表达式匹配URL或者网址
- js最强的匹配网址-url的正则表达式:匹配www,http开头的一切网址
- js匹配网址url的正则表达式集合
- JS 正则表达式(学习笔记2)匹配网址url参数
- 正则表达式匹配URL或者网址
- asp.net中匹配URL网址的正则表达式
- js正则表达式匹配斜杠 网址 url等
- 正则表达式匹配URL或者网址
- 用正则表达式匹配url网址
- JS正则表达式匹配域名、网址、url
- 正则表达式,匹配中文字符、手机号、Email地址、网址URL、HTML标记、国内电...
- 正则表达式匹配URL或者网址
- 正则表达式匹配url