linux内核数据结构之kfifo
1、前言
最近项目中用到一个环形缓冲区(ring buffer),代码是由linux内核的kfifo改过来的。缓冲区在文件系统中经常用到,通过缓冲区缓解cpu读写内存和读写磁盘的速度。例如一个进程A产生数据发给另外一个进程B,进程B需要对进程A传的数据进行处理并写入文件,如果B没有处理完,则A要延迟发送。为了保证进程A减少等待时间,可以在A和B之间采用一个缓冲区,A每次将数据存放在缓冲区中,B每次冲缓冲区中取。这是典型的生产者和消费者模型,缓冲区中数据满足FIFO特性,因此可以采用队列进行实现。Linux内核的kfifo正好是一个环形队列,可以用来当作环形缓冲区。生产者与消费者使用缓冲区如下图所示:
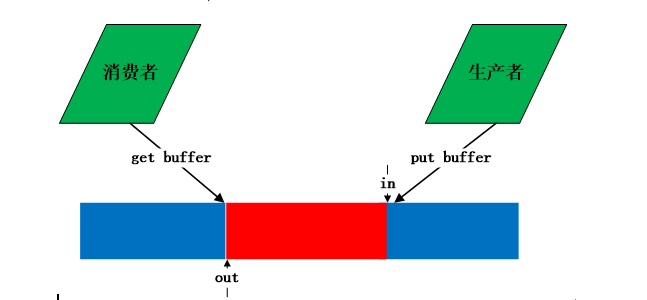
环形缓冲区的详细介绍及实现方法可以参考http://en.wikipedia.org/wiki/Circular_buffer,介绍的非常详细,列举了实现环形队列的几种方法。环形队列的不便之处在于如何判断队列是空还是满。维基百科上给三种实现方法。
2、linux 内核kfifo
kfifo设计的非常巧妙,代码很精简,对于入队和出对处理的出人意料。首先看一下kfifo的数据结构:
struct kfifo {
unsigned char *buffer; /* the buffer holding the data */
unsigned int size; /* the size of the allocated buffer */
unsigned int in; /* data is added at offset (in % size) */
unsigned int out; /* data is extracted from off. (out % size) */
spinlock_t *lock; /* protects concurrent modifications */
};
kfifo提供的方法有:
1 //根据给定buffer创建一个kfifo 2 struct kfifo *kfifo_init(unsigned char *buffer, unsigned int size, 3 gfp_t gfp_mask, spinlock_t *lock); 4 //给定size分配buffer和kfifo 5 struct kfifo *kfifo_alloc(unsigned int size, gfp_t gfp_mask, 6 spinlock_t *lock); 7 //释放kfifo空间 8 void kfifo_free(struct kfifo *fifo) 9 //向kfifo中添加数据 10 unsigned int kfifo_put(struct kfifo *fifo, 11 const unsigned char *buffer, unsigned int len) 12 //从kfifo中取数据 13 unsigned int kfifo_put(struct kfifo *fifo, 14 const unsigned char *buffer, unsigned int len) 15 //获取kfifo中有数据的buffer大小 16 unsigned int kfifo_len(struct kfifo *fifo)
定义自旋锁的目的为了防止多进程/线程并发使用kfifo。因为in和out在每次get和out时,发生改变。初始化和创建kfifo的源代码如下:
1 struct kfifo *kfifo_init(unsigned char *buffer, unsigned int size,
2 gfp_t gfp_mask, spinlock_t *lock)
3 {
4 struct kfifo *fifo;
6 /* size must be a power of 2 */
7 BUG_ON(!is_power_of_2(size));
9 fifo = kmalloc(sizeof(struct kfifo), gfp_mask);
10 if (!fifo)
11 return ERR_PTR(-ENOMEM);
13 fifo->buffer = buffer;
14 fifo->size = size;
15 fifo->in = fifo->out = 0;
16 fifo->lock = lock;
17
18 return fifo;
19 }
20 struct kfifo *kfifo_alloc(unsigned int size, gfp_t gfp_mask, spinlock_t *lock)
21 {
22 unsigned char *buffer;
23 struct kfifo *ret;
29 if (!is_power_of_2(size)) {
30 BUG_ON(size > 0x80000000);
31 size = roundup_pow_of_two(size);
32 }
34 buffer = kmalloc(size, gfp_mask);
35 if (!buffer)
36 return ERR_PTR(-ENOMEM);
38 ret = kfifo_init(buffer, size, gfp_mask, lock);
39
40 if (IS_ERR(ret))
41 kfree(buffer);
43 return ret;
44 }
在kfifo_init和kfifo_calloc中,kfifo->size的值总是在调用者传进来的size参数的基础上向2的幂扩展,这是内核一贯的做法。这样的好处不言而喻--对kfifo->size取模运算可以转化为与运算,如:kfifo->in % kfifo->size 可以转化为 kfifo->in & (kfifo->size – 1)
kfifo的巧妙之处在于in和out定义为无符号类型,在put和get时,in和out都是增加,当达到最大值时,产生溢出,使得从0开始,进行循环使用。put和get代码如下所示:
1 static inline unsigned int kfifo_put(struct kfifo *fifo,
2 const unsigned char *buffer, unsigned int len)
3 {
4 unsigned long flags;
5 unsigned int ret;
6 spin_lock_irqsave(fifo->lock, flags);
7 ret = __kfifo_put(fifo, buffer, len);
8 spin_unlock_irqrestore(fifo->lock, flags);
9 return ret;
10 }
11
12 static inline unsigned int kfifo_get(struct kfifo *fifo,
13 unsigned char *buffer, unsigned int len)
14 {
15 unsigned long flags;
16 unsigned int ret;
17 spin_lock_irqsave(fifo->lock, flags);
18 ret = __kfifo_get(fifo, buffer, len);
19 //当fifo->in == fifo->out时,buufer为空
20 if (fifo->in == fifo->out)
21 fifo->in = fifo->out = 0;
22 spin_unlock_irqrestore(fifo->lock, flags);
23 return ret;
24 }
25
26
27 unsigned int __kfifo_put(struct kfifo *fifo,
28 const unsigned char *buffer, unsigned int len)
29 {
30 unsigned int l;
31 //buffer中空的长度
32 len = min(len, fifo->size - fifo->in + fifo->out);
34 /*
35 * Ensure that we sample the fifo->out index -before- we
36 * start putting bytes into the kfifo.
37 */
39 smp_mb();
41 /* first put the data starting from fifo->in to buffer end */
42 l = min(len, fifo->size - (fifo->in & (fifo->size - 1)));
43 memcpy(fifo->buffer + (fifo->in & (fifo->size - 1)), buffer, l);
45 /* then put the rest (if any) at the beginning of the buffer */
46 memcpy(fifo->buffer, buffer + l, len - l);
47
48 /*
49 * Ensure that we add the bytes to the kfifo -before-
50 * we update the fifo->in index.
51 */
53 smp_wmb();
55 fifo->in += len; //每次累加,到达最大值后溢出,自动转为0
57 return len;
58 }
59
60 unsigned int __kfifo_get(struct kfifo *fifo,
61 unsigned char *buffer, unsigned int len)
62 {
63 unsigned int l;
64 //有数据的缓冲区的长度
65 len = min(len, fifo->in - fifo->out);
67 /*
68 * Ensure that we sample the fifo->in index -before- we
69 * start removing bytes from the kfifo.
70 */
72 smp_rmb();
74 /* first get the data from fifo->out until the end of the buffer */
75 l = min(len, fifo->size - (fifo->out & (fifo->size - 1)));
76 memcpy(buffer, fifo->buffer + (fifo->out & (fifo->size - 1)), l);
78 /* then get the rest (if any) from the beginning of the buffer */
79 memcpy(buffer + l, fifo->buffer, len - l);
81 /*
82 * Ensure that we remove the bytes from the kfifo -before-
83 * we update the fifo->out index.
84 */
86 smp_mb();
88 fifo->out += len; //每次累加,到达最大值后溢出,自动转为0
90 return len;
91 }
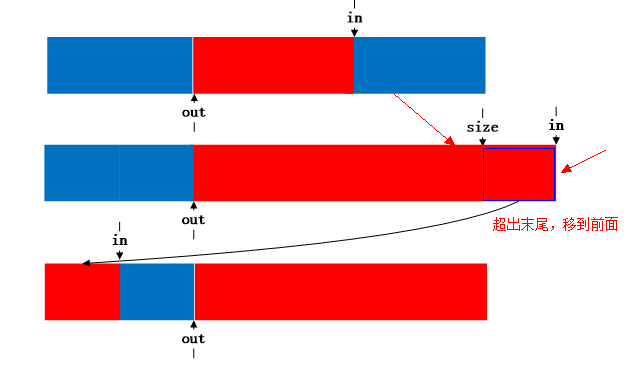
put和get在调用__put和__get过程都进行加锁,防止并发。从代码中可以看出put和get都调用两次memcpy,这针对的是边界条件。例如下图:蓝色表示空闲,红色表示占用。
(1)空的kfifo,
(2)put一个buffer后

(3)get一个buffer后

(4)当此时put的buffer长度超出in到末尾长度时,则将剩下的移到头部去
3、测试程序
仿照kfifo编写一个ring_buffer,现有线程互斥量进行并发控制。设计的ring_buffer如下所示:
1 /**@brief 仿照linux kfifo写的ring buffer
2 *@atuher Anker date:2013-12-18
3 * ring_buffer.h
4 * */
5
6 #ifndef KFIFO_HEADER_H
7 #define KFIFO_HEADER_H
8
9 #include <inttypes.h>
10 #include <string.h>
11 #include <stdlib.h>
12 #include <stdio.h>
13 #include <errno.h>
14 #include <assert.h>
15
16 //判断x是否是2的次方
17 #define is_power_of_2(x) ((x) != 0 && (((x) & ((x) - 1)) == 0))
18 //取a和b中最小值
19 #define min(a, b) (((a) < (b)) ? (a) : (b))
20
21 struct ring_buffer
22 {
23 void *buffer; //缓冲区
24 uint32_t size; //大小
25 uint32_t in; //入口位置
26 uint32_t out; //出口位置
27 pthread_mutex_t *f_lock; //互斥锁
28 };
29 //初始化缓冲区
30 struct ring_buffer* ring_buffer_init(void *buffer, uint32_t size, pthread_mutex_t *f_lock)
31 {
32 assert(buffer);
33 struct ring_buffer *ring_buf = NULL;
34 if (!is_power_of_2(size))
35 {
36 fprintf(stderr,"size must be power of 2.\n");
37 return ring_buf;
38 }
39 ring_buf = (struct ring_buffer *)malloc(sizeof(struct ring_buffer));
40 if (!ring_buf)
41 {
42 fprintf(stderr,"Failed to malloc memory,errno:%u,reason:%s",
43 errno, strerror(errno));
44 return ring_buf;
45 }
46 memset(ring_buf, 0, sizeof(struct ring_buffer));
47 ring_buf->buffer = buffer;
48 ring_buf->size = size;
49 ring_buf->in = 0;
50 ring_buf->out = 0;
51 ring_buf->f_lock = f_lock;
52 return ring_buf;
53 }
54 //释放缓冲区
55 void ring_buffer_free(struct ring_buffer *ring_buf)
56 {
57 if (ring_buf)
58 {
59 if (ring_buf->buffer)
60 {
61 free(ring_buf->buffer);
62 ring_buf->buffer = NULL;
63 }
64 free(ring_buf);
65 ring_buf = NULL;
66 }
67 }
68
69 //缓冲区的长度
70 uint32_t __ring_buffer_len(const struct ring_buffer *ring_buf)
71 {
72 return (ring_buf->in - ring_buf->out);
73 }
74
75 //从缓冲区中取数据
76 uint32_t __ring_buffer_get(struct ring_buffer *ring_buf, void * buffer, uint32_t size)
77 {
78 assert(ring_buf || buffer);
79 uint32_t len = 0;
80 size = min(size, ring_buf->in - ring_buf->out);
81 /* first get the data from fifo->out until the end of the buffer */
82 len = min(size, ring_buf->size - (ring_buf->out & (ring_buf->size - 1)));
83 memcpy(buffer, ring_buf->buffer + (ring_buf->out & (ring_buf->size - 1)), len);
84 /* then get the rest (if any) from the beginning of the buffer */
85 memcpy(buffer + len, ring_buf->buffer, size - len);
86 ring_buf->out += size;
87 return size;
88 }
89 //向缓冲区中存放数据
90 uint32_t __ring_buffer_put(struct ring_buffer *ring_buf, void *buffer, uint32_t size)
91 {
92 assert(ring_buf || buffer);
93 uint32_t len = 0;
94 size = min(size, ring_buf->size - ring_buf->in + ring_buf->out);
95 /* first put the data starting from fifo->in to buffer end */
96 len = min(size, ring_buf->size - (ring_buf->in & (ring_buf->size - 1)));
97 memcpy(ring_buf->buffer + (ring_buf->in & (ring_buf->size - 1)), buffer, len);
98 /* then put the rest (if any) at the beginning of the buffer */
99 memcpy(ring_buf->buffer, buffer + len, size - len);
100 ring_buf->in += size;
101 return size;
102 }
103
104 uint32_t ring_buffer_len(const struct ring_buffer *ring_buf)
105 {
106 uint32_t len = 0;
107 pthread_mutex_lock(ring_buf->f_lock);
108 len = __ring_buffer_len(ring_buf);
109 pthread_mutex_unlock(ring_buf->f_lock);
110 return len;
111 }
112
113 uint32_t ring_buffer_get(struct ring_buffer *ring_buf, void *buffer, uint32_t size)
114 {
115 uint32_t ret;
116 pthread_mutex_lock(ring_buf->f_lock);
117 ret = __ring_buffer_get(ring_buf, buffer, size);
118 //buffer中没有数据
119 if (ring_buf->in == ring_buf->out)
120 ring_buf->in = ring_buf->out = 0;
121 pthread_mutex_unlock(ring_buf->f_lock);
122 return ret;
123 }
124
125 uint32_t ring_buffer_put(struct ring_buffer *ring_buf, void *buffer, uint32_t size)
126 {
127 uint32_t ret;
128 pthread_mutex_lock(ring_buf->f_lock);
129 ret = __ring_buffer_put(ring_buf, buffer, size);
130 pthread_mutex_unlock(ring_buf->f_lock);
131 return ret;
132 }
133 #endif
采用多线程模拟生产者和消费者编写测试程序,如下所示:
1 /**@brief ring buffer测试程序,创建两个线程,一个生产者,一个消费者。
2 * 生产者每隔1秒向buffer中投入数据,消费者每隔2秒去取数据。
3 *@atuher Anker date:2013-12-18
4 * */
5 #include "ring_buffer.h"
6 #include <pthread.h>
7 #include <time.h>
8
9 #define BUFFER_SIZE 1024 * 1024
10
11 typedef struct student_info
12 {
13 uint64_t stu_id;
14 uint32_t age;
15 uint32_t score;
16 }student_info;
17
18
19 void print_student_info(const student_info *stu_info)
20 {
21 assert(stu_info);
22 printf("id:%lu\t",stu_info->stu_id);
23 printf("age:%u\t",stu_info->age);
24 printf("score:%u\n",stu_info->score);
25 }
26
27 student_info * get_student_info(time_t timer)
28 {
29 student_info *stu_info = (student_info *)malloc(sizeof(student_info));
30 if (!stu_info)
31 {
32 fprintf(stderr, "Failed to malloc memory.\n");
33 return NULL;
34 }
35 srand(timer);
36 stu_info->stu_id = 10000 + rand() % 9999;
37 stu_info->age = rand() % 30;
38 stu_info->score = rand() % 101;
39 print_student_info(stu_info);
40 return stu_info;
41 }
42
43 void * consumer_proc(void *arg)
44 {
45 struct ring_buffer *ring_buf = (struct ring_buffer *)arg;
46 student_info stu_info;
47 while(1)
48 {
49 sleep(2);
50 printf("------------------------------------------\n");
51 printf("get a student info from ring buffer.\n");
52 ring_buffer_get(ring_buf, (void *)&stu_info, sizeof(student_info));
53 printf("ring buffer length: %u\n", ring_buffer_len(ring_buf));
54 print_student_info(&stu_info);
55 printf("------------------------------------------\n");
56 }
57 return (void *)ring_buf;
58 }
59
60 void * producer_proc(void *arg)
61 {
62 time_t cur_time;
63 struct ring_buffer *ring_buf = (struct ring_buffer *)arg;
64 while(1)
65 {
66 time(&cur_time);
67 srand(cur_time);
68 int seed = rand() % 11111;
69 printf("******************************************\n");
70 student_info *stu_info = get_student_info(cur_time + seed);
71 printf("put a student info to ring buffer.\n");
72 ring_buffer_put(ring_buf, (void *)stu_info, sizeof(student_info));
73 printf("ring buffer length: %u\n", ring_buffer_len(ring_buf));
74 printf("******************************************\n");
75 sleep(1);
76 }
77 return (void *)ring_buf;
78 }
79
80 int consumer_thread(void *arg)
81 {
82 int err;
83 pthread_t tid;
84 err = pthread_create(&tid, NULL, consumer_proc, arg);
85 if (err != 0)
86 {
87 fprintf(stderr, "Failed to create consumer thread.errno:%u, reason:%s\n",
88 errno, strerror(errno));
89 return -1;
90 }
91 return tid;
92 }
93 int producer_thread(void *arg)
94 {
95 int err;
96 pthread_t tid;
97 err = pthread_create(&tid, NULL, producer_proc, arg);
98 if (err != 0)
99 {
100 fprintf(stderr, "Failed to create consumer thread.errno:%u, reason:%s\n",
101 errno, strerror(errno));
102 return -1;
103 }
104 return tid;
105 }
106
107
108 int main()
109 {
110 void * buffer = NULL;
111 uint32_t size = 0;
112 struct ring_buffer *ring_buf = NULL;
113 pthread_t consume_pid, produce_pid;
114
115 pthread_mutex_t *f_lock = (pthread_mutex_t *)malloc(sizeof(pthread_mutex_t));
116 if (pthread_mutex_init(f_lock, NULL) != 0)
117 {
118 fprintf(stderr, "Failed init mutex,errno:%u,reason:%s\n",
119 errno, strerror(errno));
120 return -1;
121 }
122 buffer = (void *)malloc(BUFFER_SIZE);
123 if (!buffer)
124 {
125 fprintf(stderr, "Failed to malloc memory.\n");
126 return -1;
127 }
128 size = BUFFER_SIZE;
129 ring_buf = ring_buffer_init(buffer, size, f_lock);
130 if (!ring_buf)
131 {
132 fprintf(stderr, "Failed to init ring buffer.\n");
133 return -1;
134 }
135 #if 0
136 student_info *stu_info = get_student_info(638946124);
137 ring_buffer_put(ring_buf, (void *)stu_info, sizeof(student_info));
138 stu_info = get_student_info(976686464);
139 ring_buffer_put(ring_buf, (void *)stu_info, sizeof(student_info));
140 ring_buffer_get(ring_buf, (void *)stu_info, sizeof(student_info));
141 print_student_info(stu_info);
142 #endif
143 printf("multi thread test.......\n");
144 produce_pid = producer_thread((void*)ring_buf);
145 consume_pid = consumer_thread((void*)ring_buf);
146 pthread_join(produce_pid, NULL);
147 pthread_join(consume_pid, NULL);
148 ring_buffer_free(ring_buf);
149 free(f_lock);
150 return 0;
151 }
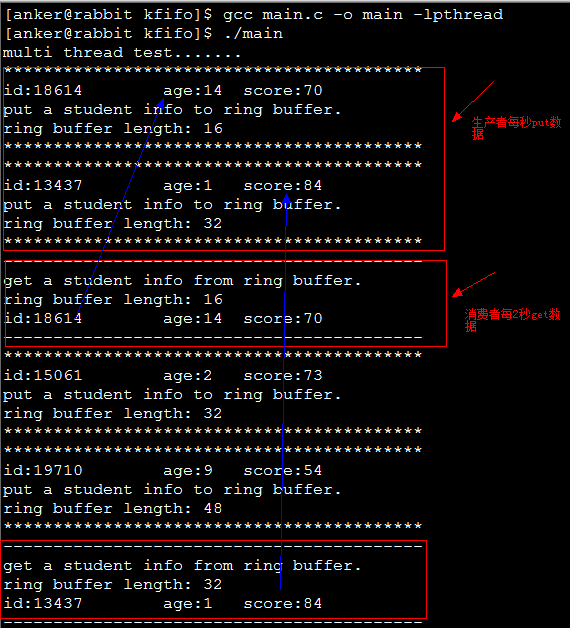
测试结果如下所示:
4、参考资料
https://www.geek-share.com/detail/2491030582.html
http://en.wikipedia.org/wiki/Circular_buffer
巧夺天工的kfifo
Linux kernel里面从来就不缺少简洁,优雅和高效的代码,只是我们缺少发现和品味的眼光。在Linux kernel里面,简洁并不表示代码使用神出鬼没的超然技巧,相反,它使用的不过是大家非常熟悉的基础数据结构,但是kernel开发者能从基础的数据结构中,提炼出优美的特性。
kfifo就是这样的一类优美代码,它十分简洁,绝无多余的一行代码,却非常高效。
关于kfifo信息如下:
本文分析的原代码版本: 2.6.24.4
kfifo的定义文件: kernel/kfifo.c
kfifo的头文件: include/linux/kfifo.h
kfifo概述
kfifo是内核里面的一个First In First
Out数据结构,它采用环形循环队列的数据结构来实现;它提供一个无边界的字节流服务,最重要的一点是,它使用并行无锁编程技术,即当它用于只有一个入队线程和一个出队线程的场情时,两个线程可以并发操作,而不需要任何加锁行为,就可以保证kfifo的线程安全。
kfifo代码既然肩负着这么多特性,那我们先一敝它的代码:
struct kfifo {
unsigned char *buffer; /* the buffer holding the data */
unsigned int size; /* the size of the allocated buffer */
unsigned int in; /* data is added at offset (in % size) */
unsigned int out; /* data is extracted from off. (out % size) */
spinlock_t *lock; /* protects concurrent modifications */
};
这是kfifo的数据结构,kfifo主要提供了两个操作,__kfifo_put(入队操作)和__kfifo_get(出队操作)。 它的各个数据成员如下:
buffer: 用于存放数据的缓存
size: buffer空间的大小,在初化时,将它向上扩展成2的幂
lock: 如果使用不能保证任何时间最多只有一个读线程和写线程,需要使用该lock实施同步。
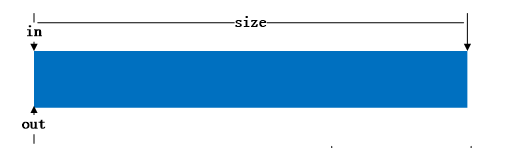
in, out: 和buffer一起构成一个循环队列。 in指向buffer中队头,而且out指向buffer中的队尾,它的结构如示图如下:
+--------------------------------------------------------------+ | |<----------data---------->| | +--------------------------------------------------------------+ ^ ^ ^ | | | out in size
当然,内核开发者使用了一种更好的技术处理了in, out和buffer的关系,我们将在下面进行详细分析。
kfifo功能描述
kfifo提供如下对外功能规格
- 只支持一个读者和一个读者并发操作
- 无阻塞的读写操作,如果空间不够,则返回实际访问空间
kfifo_alloc 分配kfifo内存和初始化工作
struct kfifo *kfifo_alloc(unsigned int size, gfp_t gfp_mask, spinlock_t *lock)
{
unsigned char *buffer;
struct kfifo *ret;
/*
* round up to the next power of 2, since our 'let the indices
* wrap' tachnique works only in this case.
*/
if (size & (size - 1)) {
BUG_ON(size > 0x80000000);
size = roundup_pow_of_two(size);
}
buffer = kmalloc(size, gfp_mask);
if (!buffer)
return ERR_PTR(-ENOMEM);
ret = kfifo_init(buffer, size, gfp_mask, lock);
if (IS_ERR(ret))
kfree(buffer);
return ret;
}
这里值得一提的是,kfifo->size的值总是在调用者传进来的size参数的基础上向2的幂扩展,这是内核一贯的做法。这样的好处不言而喻——对kfifo->size取模运算可以转化为与运算,如下:
kfifo->in % kfifo->size 可以转化为 kfifo->in & (kfifo->size – 1)
在kfifo_alloc函数中,使用size & (size – 1)来判断size 是否为2幂,如果条件为真,则表示size不是2的幂,然后调用roundup_pow_of_two将之向上扩展为2的幂。
这都是常用的技巧,只不过大家没有将它们结合起来使用而已,下面要分析的__kfifo_put和__kfifo_get则是将kfifo->size的特点发挥到了极致。
__kfifo_put和__kfifo_get巧妙的入队和出队
__kfifo_put是入队操作,它先将数据放入buffer里面,最后才修改in参数;__kfifo_get是出队操作,它先将数据从buffer中移走,最后才修改out。你会发现in和out两者各司其职。
下面是__kfifo_put和__kfifo_get的代码
unsigned int __kfifo_put(struct kfifo *fifo,
unsigned char *buffer, unsigned int len)
{
unsigned int l;
len = min(len, fifo->size - fifo->in + fifo->out);
/*
* Ensure that we sample the fifo->out index -before- we
* start putting bytes into the kfifo.
*/
smp_mb();
/* first put the data starting from fifo->in to buffer end */
l = min(len, fifo->size - (fifo->in & (fifo->size - 1)));
memcpy(fifo->buffer + (fifo->in & (fifo->size - 1)), buffer, l);
/* then put the rest (if any) at the beginning of the buffer */
memcpy(fifo->buffer, buffer + l, len - l);
/*
* Ensure that we add the bytes to the kfifo -before-
* we update the fifo->in index.
*/
smp_wmb();
fifo->in += len;
return len;
}
奇怪吗?代码完全是线性结构,没有任何if-else分支来判断是否有足够的空间存放数据。内核在这里的代码非常简洁,没有一行多余的代码。
l = min(len, fifo->size - (fifo->in & (fifo->size - 1)));
这个表达式计算当前写入的空间,换成人可理解的语言就是:
l = kfifo可写空间和预期写入空间的最小值
使用min宏来代if-else分支
__kfifo_get也应用了同样技巧,代码如下:
unsigned int __kfifo_get(struct kfifo *fifo,
unsigned char *buffer, unsigned int len)
{
unsigned int l;
len = min(len, fifo->in - fifo->out);
/*
* Ensure that we sample the fifo->in index -before- we
* start removing bytes from the kfifo.
*/
smp_rmb();
/* first get the data from fifo->out until the end of the buffer */
l = min(len, fifo->size - (fifo->out & (fifo->size - 1)));
memcpy(buffer, fifo->buffer + (fifo->out & (fifo->size - 1)), l);
/* then get the rest (if any) from the beginning of the buffer */
memcpy(buffer + l, fifo->buffer, len - l);
/*
* Ensure that we remove the bytes from the kfifo -before-
* we update the fifo->out index.
*/
smp_mb();
fifo->out += len;
return len;
}
认真读两遍吧,我也读了多次,每次总是有新发现,因为in, out和size的关系太巧妙了,竟然能利用上unsigned int回绕的特性。
原来,kfifo每次入队或出队,kfifo->in或kfifo->out只是简单地kfifo->in/kfifo->out += len,并没有对kfifo->size 进行取模运算。因此kfifo->in和kfifo->out总是一直增大,直到unsigned in最大值时,又会绕回到0这一起始端。但始终满足:
kfifo->in - kfifo->out <= kfifo->size
即使kfifo->in回绕到了0的那一端,这个性质仍然是保持的。
对于给定的kfifo:
数据空间长度为:kfifo->in - kfifo->out
而剩余空间(可写入空间)长度为:kfifo->size - (kfifo->in - kfifo->out)
尽管kfifo->in和kfofo->out一直超过kfifo->size进行增长,但它对应在kfifo->buffer空间的下标却是如下:
kfifo->in % kfifo->size (i.e. kfifo->in & (kfifo->size - 1))
kfifo->out % kfifo->size (i.e. kfifo->out & (kfifo->size - 1))
往kfifo里面写一块数据时,数据空间、写入空间和kfifo->size的关系如果满足:
kfifo->in % size + len > size
那就要做写拆分了,见下图:
kfifo_put(写)空间开始地址 | \_/ |XXXXXXXXXX XXXXXXXX| +--------------------------------------------------------------+ | |<----------data---------->| | +--------------------------------------------------------------+ ^ ^ ^ | | | out%size in%size size ^ | 写空间结束地址
第一块当然是: [kfifo->in % kfifo->size, kfifo->size]
第二块当然是:[0, len - (kfifo->size - kfifo->in % kfifo->size)]
下面是代码,细细体味吧:
/* first put the data starting from fifo->in to buffer end */ l = min(len, fifo->size - (fifo->in & (fifo->size - 1))); memcpy(fifo->buffer + (fifo->in & (fifo->size - 1)), buffer, l); /* then put the rest (if any) at the beginning of the buffer */ memcpy(fifo->buffer, buffer + l, len - l);
对于kfifo_get过程,也是类似的,请各位自行分析。
kfifo_get和kfifo_put无锁并发操作
计算机科学家已经证明,当只有一个读经程和一个写线程并发操作时,不需要任何额外的锁,就可以确保是线程安全的,也即kfifo使用了无锁编程技术,以提高kernel的并发。
kfifo使用in和out两个指针来描述写入和读取游标,对于写入操作,只更新in指针,而读取操作,只更新out指针,可谓井水不犯河水,示意图如下:
|<--写入-->| +--------------------------------------------------------------+ | |<----------data----->| | +--------------------------------------------------------------+ |<--读取-->| ^ ^ ^ | | | out in size
为了避免读者看到写者预计写入,但实际没有写入数据的空间,写者必须保证以下的写入顺序:
- 往[kfifo->in, kfifo->in + len]空间写入数据
- 更新kfifo->in指针为 kfifo->in + len
在操作1完成时,读者是还没有看到写入的信息的,因为kfifo->in没有变化,认为读者还没有开始写操作,只有更新kfifo->in之后,读者才能看到。
那么如何保证1必须在2之前完成,秘密就是使用内存屏障:smp_mb(),smp_rmb(), smp_wmb(),来保证对方观察到的内存操作顺序。
总结
读完kfifo代码,令我想起那首诗“众里寻他千百度,默然回首,那人正在灯火阑珊处”。不知你是否和我一样,总想追求简洁,高质量和可读性的代码,当用尽各种方法,江郞才尽之时,才发现Linux kernel里面的代码就是我们寻找和学习的对象。

- linux内核数据结构之kfifo
- linux内核数据结构之kfifo
- linux内核数据结构之kfifo【转】
- Linux内核数据结构 kfifo
- linux内核数据结构之kfifo
- linux内核数据结构之kfifo
- linux内核数据结构之kfifo
- linux内核数据结构之kfifo
- linux内核数据结构之kfifo
- Linux内核数据结构--kfifo
- linux内核数据结构之kfifo【转】
- linux内核数据结构之kfifo
- linux内核数据结构之kfifo
- linux内核数据结构之kfifo
- 【Linux内核数据结构】最为经典的链表list
- Linux Kernel Development 笔记(五)内核数据结构
- Linux内核数据结构—链表
- 真正理解红黑树,真正的(Linux内核里大量用到的数据结构,且常被二货问到)
- linux内核数据结构-顺序存储链表(1)
- linux内核数据结构之等待队列