基于Gensim的维基百科语料库中文词向量训练
2018-02-24 23:06
316 查看
环境: Win10 +Anaconda(自带Python3.6) IDE: Pycharm (其Interperter使用的是Anaconda自带的Python3.6)
安装Gensim库:在Anaconda Prompt中输入:pip install gensim 等待其显示安装完毕即可
1.首先获取维基百科语料库资源https://dumps.wikimedia.org/zhwiki/20171220/我是在其中下载的当时最新的压缩文件注:文件名在网站中的结尾为xml.bz2
2.将wiki的xml文件处理成正常的txt文件需要用特殊的脚本处理而不能直接压缩(与维基百科保存格式有关)github中有更为全面的WikiExtractor有兴趣可以去研究一下此处直接使用普通压缩文件to txt处理脚本即可代码如下:
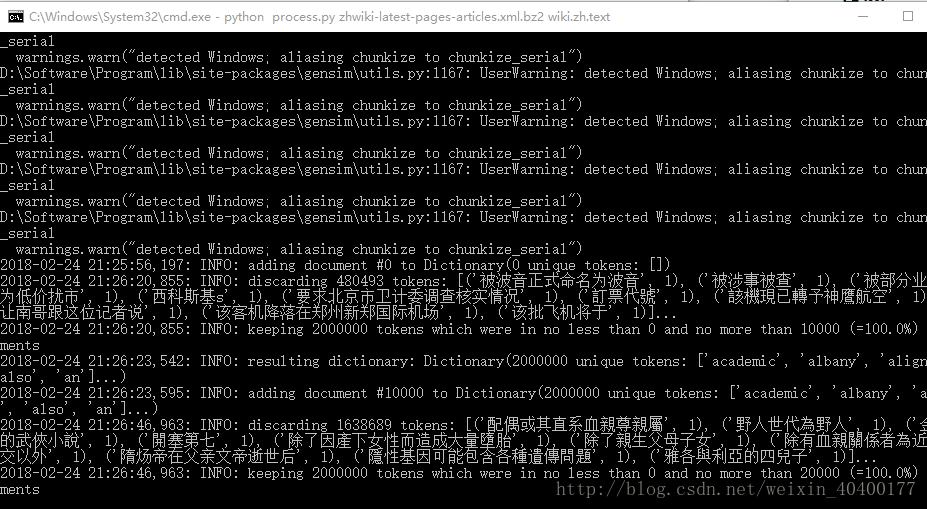
就可以看到正在解压的过程了,过程还是需要不少时间的部分生成结果:

需要注意文件可能过大而无法打开
3.使用opencc将繁体txt转换为简体txt下载地址:https://bintray.com/package/files/byvoid/opencc/OpenCC无需安装,解压即可使用将我们前面生成的wiki.zh.text拖动至opencc-1.0.1-win64文件夹中,打开cmd并在当前文件夹中输入如下指令:opencc -i wiki.zh.text -o wiki.zh.jian.text -c t2s.json这一步骤非常快,我只用了1分钟不到然后可以看到目录中生成了wiki.zh.jian.text文件打开后可以查看其中内容

可以看到已经成功全部转化为了简体字但是做词向量训练之前仍缺少最后一步,就是分词
4.分词英文中空格就已经将其句子分词完毕而中文就相对复杂,但我们可以借助jieba库来分词在Testjieba.py中分词打开wiki.zh.jian.text,从该文件中一行行读取简体字并进行分词,分词结果放在zh.jian.wiki.seg.txt中代码如下:
每一行读入后进行每一行的分词直接运行该py文件即可(注意将 在opencc文件夹中生成的wiki.zh.jian.text放入Testjieba.py所在文件夹)查看分词结果如下:

5.进行词向量训练创建词向量结果模型代码如下:
在命令行中输入python word2vec_model.py zh.jian.wiki.seg.txt wiki.zh.model wiki.zh.text.vector源文件为zh.jian.wiki.seg.txt目标文件为wiki.zh.model
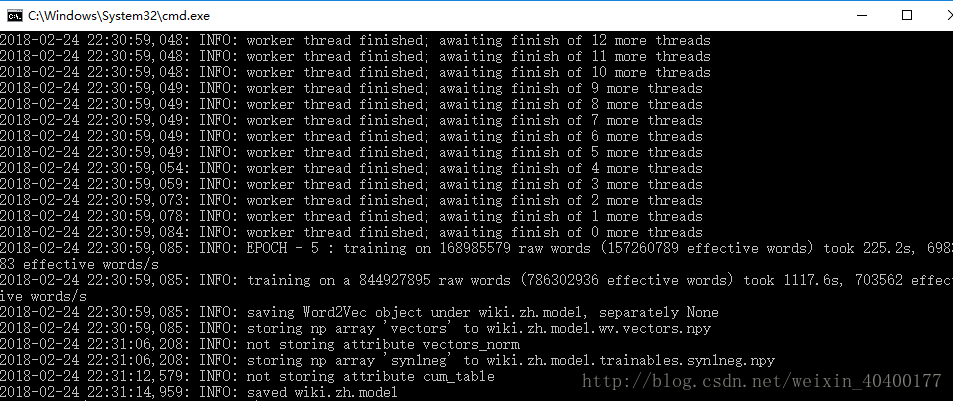
训练时间大致为25分钟(1080Ti训练结果下)
6.测试训练模块成果代码如下
然后使用Word2Vec模块中方法加载模块,之后便可以使用其中的most_similar方法进行词向量寻找并打印结果
测试结果展示:

总结:可以看到还是大部分make sense的但是也有一些词不太相近或者更相近的答案而并非首选。很大一部分原因是因为语料库的不足,因为语料库中资料仅有1.3G,对于中文训练来说是大大不足的。
安装Gensim库:在Anaconda Prompt中输入:pip install gensim 等待其显示安装完毕即可
1.首先获取维基百科语料库资源https://dumps.wikimedia.org/zhwiki/20171220/我是在其中下载的当时最新的压缩文件注:文件名在网站中的结尾为xml.bz2
2.将wiki的xml文件处理成正常的txt文件需要用特殊的脚本处理而不能直接压缩(与维基百科保存格式有关)github中有更为全面的WikiExtractor有兴趣可以去研究一下此处直接使用普通压缩文件to txt处理脚本即可代码如下:
import logging
import os.path
import sys
from gensim.corpora import WikiCorpus
if __name__ == '__main__':
program = os.path.basename(sys.argv[0])
logger = logging.getLogger(program)
logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s')
logging.root.setLevel(level=logging.INFO)
logger.info("running %s" % ' '.join(sys.argv))
# check and process input arguments
if len(sys.argv) < 3:
print(globals()['__doc__'] % locals())
sys.exit(1)
inp, outp = sys.argv[1:3]
space = b' '
i = 0
output = open(outp, 'w',encoding='utf-8')
wiki = WikiCorpus(inp, lemmatize=False, dictionary={})
for text in wiki.get_texts():
s = space.join(text)
s = s.decode('utf8') + "\n"
output.write(s)
i = i + 1
if (i % 10000 == 0):
logger.info("Saved " + str(i) + " articles")
output.close()
logger.info("Finished Saved " + str(i) + " articles")使用process.py脚本(即以上代码) 将维基百科的下载文件转化成text文件在命令行中输入python process.py zhwiki-latest-pages-articles.xml.bz2 wiki.zh.text就可以看到正在解压的过程了,过程还是需要不少时间的部分生成结果:
需要注意文件可能过大而无法打开
3.使用opencc将繁体txt转换为简体txt下载地址:https://bintray.com/package/files/byvoid/opencc/OpenCC无需安装,解压即可使用将我们前面生成的wiki.zh.text拖动至opencc-1.0.1-win64文件夹中,打开cmd并在当前文件夹中输入如下指令:opencc -i wiki.zh.text -o wiki.zh.jian.text -c t2s.json这一步骤非常快,我只用了1分钟不到然后可以看到目录中生成了wiki.zh.jian.text文件打开后可以查看其中内容
可以看到已经成功全部转化为了简体字但是做词向量训练之前仍缺少最后一步,就是分词
4.分词英文中空格就已经将其句子分词完毕而中文就相对复杂,但我们可以借助jieba库来分词在Testjieba.py中分词打开wiki.zh.jian.text,从该文件中一行行读取简体字并进行分词,分词结果放在zh.jian.wiki.seg.txt中代码如下:
import jieba
import jieba.analyse
import jieba.posseg as pseg
import codecs, sys
def cut_words(sentence):
#print sentence
return " ".join(jieba.cut(sentence)).encode('utf-8')
f = codecs.open('wiki.zh.jian.text', 'r', encoding="utf8")
target = codecs.open("zh.jian.wiki.seg.txt", 'w', encoding="utf8")
print('open files')
line_num = 1
line = f.readline()
while line:
print('---- processing ', line_num, ' article----------------')
line_seg = " ".join(jieba.cut(line))
target.writelines(line_seg)
line_num = line_num + 1
line = f.readline()
f.close()
target.close()
exit()
while line:
curr = []
for oneline in line:
#print(oneline)
curr.append(oneline)
after_cut = map(cut_words, curr)
target.writelines(after_cut)
print('saved', line_num, 'articles')
exit()
line = f.readline1()
f.close()
target.close()每一行读入后进行每一行的分词直接运行该py文件即可(注意将 在opencc文件夹中生成的wiki.zh.jian.text放入Testjieba.py所在文件夹)查看分词结果如下:
5.进行词向量训练创建词向量结果模型代码如下:
from __future__ import print_function
import logging
import os
import sys
import multiprocessing
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
if __name__ == '__main__':
program = os.path.basename(sys.argv[0])
logger = logging.getLogger(program)
logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s')
logging.root.setLevel(level=logging.INFO)
logger.info("running %s" % ' '.join(sys.argv))
# check and process input arguments
if len(sys.argv) < 4:
print("Useing: python train_word2vec_model.py input_text "
"output_gensim_model output_word_vector")
sys.exit(1)
inp, outp1, outp2 = sys.argv[1:4]
model = Word2Vec(LineSentence(inp), size=200, window=5, min_count=5,
workers=multiprocessing.cpu_count())
model.save(outp1)
model.wv.save_word2vec_format(outp2, binary=False)其中model = Word2Vec(LineSentence(inp), size=200, window=5, min_count=5, workers=multiprocessing.cpu_count())代码是训练词向量的关键,定义了滑动窗口大小与最小有效词数量并在下方保存word2vec格式的模型在命令行中输入python word2vec_model.py zh.jian.wiki.seg.txt wiki.zh.model wiki.zh.text.vector源文件为zh.jian.wiki.seg.txt目标文件为wiki.zh.model
训练时间大致为25分钟(1080Ti训练结果下)
6.测试训练模块成果代码如下
from gensim.models import Word2Vec
en_wiki_word2vec_model = Word2Vec.load('wiki.zh.model')
testwords = ['孩子', '数学', '学术', '白痴', '篮球']
for i in range(5):
res = en_wiki_word2vec_model.most_similar(testwords[i])
print(testwords[i])
print(res)首先导入gensim.models中的Word2Vec模块然后使用Word2Vec模块中方法加载模块,之后便可以使用其中的most_similar方法进行词向量寻找并打印结果
测试结果展示:
总结:可以看到还是大部分make sense的但是也有一些词不太相近或者更相近的答案而并非首选。很大一部分原因是因为语料库的不足,因为语料库中资料仅有1.3G,对于中文训练来说是大大不足的。

相关文章推荐
- 基于word2vec的中文词向量训练
- 基于python的gensim word2vec训练词向量
- windows以及linux下安装gensim笔记以及用wiki(维基百科数据)训练中文词向量
- 基于gensim进行句向量的训练
- windows环境下使用wiki中文百科及gensim工具库训练词向量
- gensim 中文语料训练 word2vec
- AAAI 2018 论文 | 蚂蚁金服公开最新基于笔画的中文词向量算法
- AAAI 2018 论文 | 蚂蚁金服公开最新基于笔画的中文词向量算法
- 利用 word2vec 训练的字向量进行中文分词
- word2vec词向量训练及中文文本类似度计算
- 利用Gensim在英文Wikipedia训练词向量
- 用Word2vec训练中文wiki,构造词向量并做词聚类
- windows下用Anaconda3做基于维基百科中文word2vec训练
- gensim的word2vector测试_基于中文wiki语料
- 利用 word2vec 训练的字向量进行中文分词
- 一个基于特征向量的近似网页去重算法——term用SVM人工提取训练,基于term的特征向量,倒排索引查询相似文档,同时利用cos计算相似度
- Tensorflow实战学习(十八)【词向量、维基百科语料库训练词向量模型】
- word2vec词向量训练及gensim的使用
- 利用 word2vec 训练的字向量进行中文分词
- [zt]word2vec词向量训练及中文文本相似度计算