java解析XML方式
2018-02-24 14:40
330 查看
package com;
/*
* XML:指可扩展标记语言,是独立于软件和硬件的信息工具
* XML应用于web开发的许多方面,常用于简化数据的存储和共享。
* XML简化数据共享。
* XML简化数据传输。
* XML简化平台的变更。
*/
import java.io.FileInputStream;
import java.util.ArrayList;
import java.util.List;
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
/*
* XML解析方式:
* 1:SAX解析方式:它是一行一行的读的
* 优点:解析可以立即开始,速度快,占有内存资源少
* 缺点:不能对节点做修改
*
*
* 2:DOM解析方式:是W3C组织推荐的处理xml的一种方式。
* 它是一上来就把XML整个结构都读完了,然后把读到的东西放到内存中去,如果xml的东西多,那么存内存的东西就多
* 占用内存。
* 优点:把xml文件在内存中构造树形结构,可以遍历和修改节点
* 缺点:如果文件比较大,内存有压力,解析的时间会比较长。(耗时,耗资源)
*/
/*
* 使用DOM解析xml文档,使用的是SAXReader对象
*/
public class ParseXmlDemo {
public static void main(String[] args) {
/*
* 解析empList.xml文档,将所有的员工信息读取出来并转换为若干Emp实例,存入一个List集合中。
*
* 解析XML的流程:
* 1:创建SAXReader。
* 2:使用SAXReader读取XML文档并返回Document对象,这一步就是DOM解析耗时耗资源的体现,
* 因为DOM会将XML文档全部读取并以一个Document对象用于描述解析的XML文档内容。
* 3:根据Document对象获取根元素。
* 4:按照xml的结构从根元素中开始逐级获取子元素以达到遍历xml的目的。
*/
try {
//1
SAXReader reader=new SAXReader();
//2 empList.xml在项目的根目录下,所以这里可以直接写,不用写路径
Document doc=reader.read(new FileInputStream("empList.xml"));
/*
* 3获取根元素
* Element的每一个实例用于表示xml文档中的一个元素(一对标签),
* 这里获取的相当于是empList.xml文档中的<empList>标签。
*/
Element root=doc.getRootElement();
/*
* Element提供了获取元素的相关方法:
*
* List elements():获取当前标签下的所有子标签
* List elements(String name):获取当前标签下所有同名子标签(如果子标签有多种,想获取指定的子标签就用这种)
* Element element(String name):获取指定名字的子标签
* Attribute attribute(String name):获取指定名字的属性
* String getTest():获取当前标签中的文本(前标签和后标签中间的文本信息,前提是确实为文本而不是子标签)
*/
List<Emp> empList=new ArrayList<Emp>();
//获取根标签<empList>下面的所有子标签<dept>,这里elements实例实际上就是每一个<dept>标签。
List<Element> deptElement=root.elements(); //root.elements("dept") 意思是获取所有子标签是dept的的子标签。
/*
* 遍历所有<dept>标签并解析出该员工相关信息并以一个Emp实例保存,然后将其存入empList集合中
*/
for(Element depEle:deptElement) {
//获取标签<dept>下面的所有子标签<emp>,这里elements实例实际上就是每一个<emp>标签。
List<Element> empElement=depEle.elements(); //root.elements("emp") 意思是获取所有子标签是emp的的子标签。
for(Element empEle:empElement) {
//获取到<name>这个标签
Element nameEle=empEle.element("name");
String name=nameEle.getText();//nameEle.getTextTrim() 这样是去除内容前后的空格
//获取年龄
int age=Integer.parseInt(empEle.elementTextTrim("age"));
//获取性别
String gender=empEle.elementTextTrim("gender");
//获取工资
Double salary=Double.parseDouble(empEle.elementTextTrim("salary"));
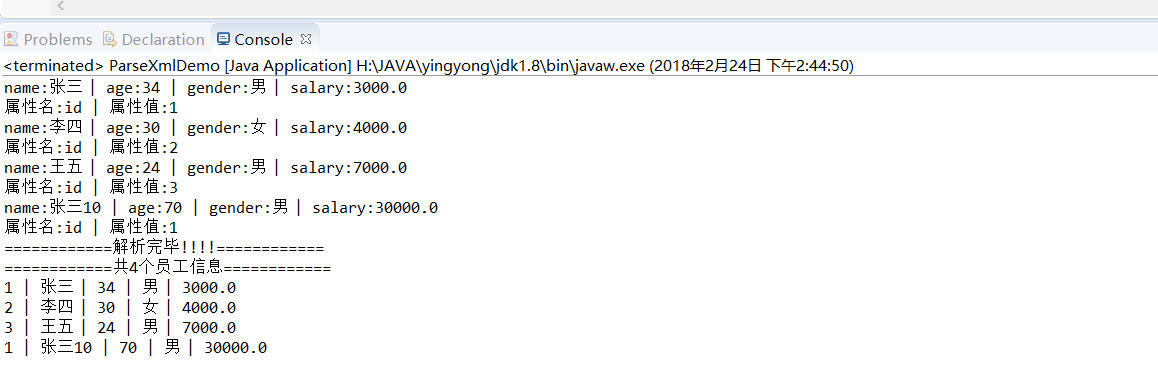
System.out.println("name:"+name+" | age:"+age+" | gender:"+gender+" | salary:"+salary);
/*
* 获取属性,属性是写在标签里面的,如<emp id="1" nn="nn" xx="xx">
* 这里也可以attribute(0)意思是取<emp id="1" nn="nn" xx="xx">里第1个,也就是id="1"
* Attribute实例就是表示标签的属性。
*/
Attribute attr=empEle.attribute("id");
String attrName=attr.getName();
int idValue=Integer.parseInt(attr.getValue());
System.out.println("属性名:"+attrName+" | 属性值:"+idValue);
Emp emp=new Emp(idValue,name,age,gender,salary);
empList.add(emp);
}
}
System.out.println("============解析完毕!!!!============");
System.out.println("============共"+empList.size()+"个员工信息============");
for(Emp emp:empList) {
System.out.println(emp);
}
}catch(Exception e) {
e.printStackTrace();
}
}
}empList.xml内容如下:<?xml version="1.0" encoding="UTF-8"?><empList>
<dept name="IT">
<emp id="1" nn="nn" xx="xx">
<name>张三</name>
<age>34</age>
<gender>男</gender>
<salary>3000</salary>
</emp>
<emp id="2">
<name>李四</name>
<age>30</age>
<gender>女</gender>
<salary>4000</salary>
</emp>
<emp id="3">
<name>王五</name>
<age>24</age>
<gender>男</gender>
<salary>7000</salary>
</emp>
</dept>
<dept name="XIAOSHOU">
<emp id="1">
<name>张三10</name>
<age>70</age>
<gender>男</gender>
<salary>30000</salary>
</emp>
</dept>
</empList>控制台输出结果:
需要的jar包:<dependencies>
<dependency>
<groupId>dom4j</groupId>
<artifactId>dom4j</artifactId>
<version>1.6.1</version>
</dependency>
</dependencies>

相关文章推荐
- java28.XML操作------DOM方式解析XML数据
- java解析xml的几种方式比较
- java解析xml的几种方式
- Java中使用SAX方式解析XML的问题
- JAVA解析XML之DOM方式
- Android/Java XML数据格式解析的两种方式
- java解析XML几种方式小结
- Java解析xml的四种方式
- JAVA两种XML解析方式 SAX和DOM
- java-->dom方式解析xml
- Java眼中的XML--文件读取--2 应用SAX方式解析XML
- JAVA 应用 DOM4J 及 JDOM 方式解析 XML
- Java_xml_Dom解析方式
- java解析xml的几种方式(转)
- java处理XML三种解析方式比较
- Java解析Xml文件—判断Xml文件的节点是否存在子节点_以及对节点下不同子节点的内容解析方式
- JAVA解析XML之SAX方式
- JAVA XML 解析的四种方式
- Java中解析XML文件之SAX方式
- java解析XML几种方式小结