浅谈 SQL 中的锁(七)如何生成自定义的自增 ID
2018-02-23 14:13
267 查看
在 SQL 表设计中,自增 ID 的使用很广泛。因为有些数据的属性并不具有唯一性,所以要给它加上一个生成的主键。生成主键最方便的方式,就是采用 SQL 产品提供的自增 ID 功能。可能自增 ID 的使用太过方便了,现在大有泛滥的趋势,甚至有资深的工程师说:所有的表都应该有一个自增的主键。不过 SQL 产品的自增 ID 功能,一般都只使用简单的自增整型,就是第一行记录的 ID 是 1,第二行记录的 ID 是 2,如此类推。有时候我们会希望 ID 带有除序号之外额外的信息,比如希望用户的 ID 带有其部门简写:人事部的员工以 HR 做前缀;信息部的员工以 IT 做前缀:
面对这样的需求,一般的处理逻辑是:先找出对应部门的最大 ID,把这个 ID 的序号部分加 1,作为新用户的 ID 添加到用户表中:
很明显,上面的代码在并发的时候会出现问题,因为计算新的 ID 和插入记录是两个独立的事务,在这两个事务之间,新的 ID 可能会被占用了。加入延时的代码,在两个连接中执行同样的语句:
可以看到后执行的连接插入记录失败:
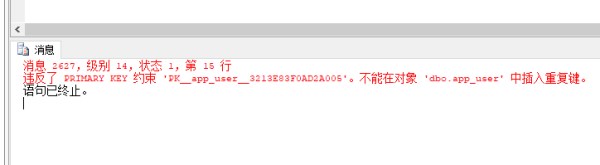
原因就是 ID 已经被先执行的连接占用了。实际上,解决这个问题方法,和之前写的重复用户问题的解决方法是一样的:浅谈 SQL 中的锁(三)重复用户问题
浅谈 SQL 中的锁(四)如何检查重复用户关键就是在生成 ID 的时候加上范围锁:
上面的代码做了两处改动,第一是把计算新的 ID 和插入记录合并为一个事务,并使用 serializable 隔离级别,对事务中操作的数据使用范围锁;第二是在查询存在的最大 ID 时使用 updlock 更新锁,这样两个并发的操作才能互斥。这样,就完成自定义自增 ID 的编写了。实际上,用 SQL 生成 ID并不是最适合的方法,因为 SQL 并不是一门标准的编程语言,而是一门查询数据的领域语言,使用 .NET 的 ODBC 或 Java 的 JDBC 编写生成自定义自增 ID 的逻辑会更简单,更好读。知道了生成自定义自增 ID 的方法,可以再思考数据库自带的自增 ID 的功能。从逻辑上来说,生成自增 ID 就必须要使用范围锁,这会增加性能消耗。另外,自增 ID 一般会作为主键,其实很多数据本身的属性就有唯一性的,比如电话号码,电子邮箱等等,这样的数据还添加自增 ID 作为主键是多余的,增加了性能和存储空间的消耗,程序也会更啰嗦!所以,我是反对“所有的表都应该有一个自增的主键”这种迂腐的说法的。
原因就是 ID 已经被先执行的连接占用了。实际上,解决这个问题方法,和之前写的重复用户问题的解决方法是一样的:浅谈 SQL 中的锁(三)重复用户问题
浅谈 SQL 中的锁(四)如何检查重复用户关键就是在生成 ID 的时候加上范围锁:

相关文章推荐
- 高并发 sql 生成不重复编号 (订单号) & 如何在高并发分布式系统中生成全局唯一Id
- 10031---高并发 sql 生成不重复编号 (订单号) & 如何在高并发分布式系统中生成全局唯一Id
- 高并发 sql 生成不重复编号 (订单号) & 如何在高并发分布式系统中生成全局唯一Id
- 高并发 sql 生成不重复编号 (订单号) & 如何在高并发分布式系统中生成全局唯一Id
- sql 2005 中如何自动生成不重复的,长度相同字符串作为一个数据表的id
- Oracle如何根据SQL_TEXT生成SQL_ID
- 如何自定义destoon的地址生成规则
- 【转】Oracle中如何用一条SQL快速生成10万条测试数据
- sql如何取各组中ID最大值-2
- 浅谈MVC中如何自定义HtmlHelper的过程
- 自定义ORMapping—动态生成SQL语句
- sql循环生成id和delphi生成最大编号
- shiro学习随笔【五】自定义生成会话ID--SessionIdGenerator
- 浅谈SQL SERVER数据库口令的脆弱性&SQL登录密码对照表&MsSQLServer是如何加密口令的 未公开的加密函数
- sql如何根据父级Id得到所有下级的记录
- 如何使用 Sqldumper.exe 为 Windows 应用程序生成转储文件
- 如何将sqlserver表中的数据导出sql语句或生成insert into语句
- powerdesign,如何解决PDM生成sql脚本的过程中,无法生成外键约束
- sencha touch使用WebSQL如何手动设置id
- SQL Server中如何生成GUID C#.NET中如何生成和使用GUID