《TensorFlow学习笔记》对图片数据的预处理一、-编码解码调整大小色彩亮度
2018-02-22 19:42
411 查看
IDE:pycharm
Python: Python3.6
OS: win10
tf: 1.5.0
答案是 为了降低其他无关因素对最后的识别结果的影响,比如说一幅图片在不同亮度或是对比度等指标下呈现的效果可能差别特别大,但是这些对于我们来说,不要影响到最后的识别结果,所以这就是预处理最想解决的东西,其次通过预处理方式也可以让数据集更加多样化,随机化,可以让model更加健壮。
Kyrie_Irving.jpg

有详细的讲解注释
对没有错你会发现运行之后出error
这个错误的出现在jpeg编码位置,意思是进行jpeg编码需要的类型矩阵是uint8类型,而这里我把这个类型转换为了float32,所以先不管这个先去掉归一化操作之后的话我再用这个来操作。
输出:
三维矩阵
plt显示的图片

写入编码之后的文件

打开的时候选择image
显示
2.存储jpg图片的时候需要把图片转换成uint8类型
所以一般来讲图片的尺寸是大小不一的,但是神经网络的输入节点的个数是固定的,所以在图片预处理阶段应该需要对图片统一大小的操作
结果

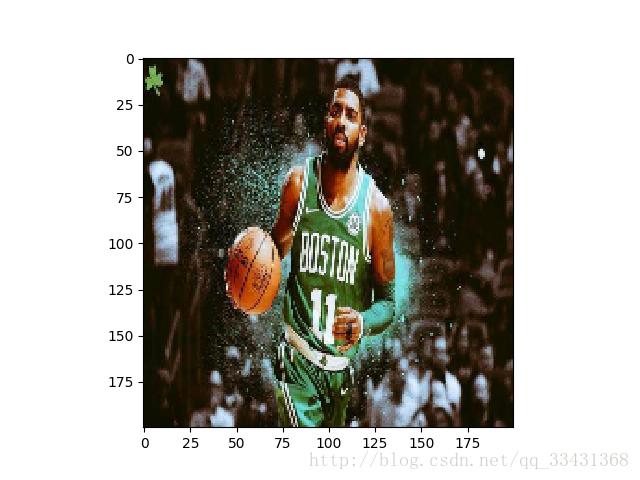
大致程序在[b]***********[/b]两行这个之间
但是其实最主要的就是两句话
如果这里不对图片进行重新编码并且存储的话也不需要再把三维矩阵的值转换为uint8了
在以下的程序中我就省略这么完整的程序了,直接讲图片处理的函数
比如这里的
method如上图所示,如果你学过数字图像处理,你应该不陌生,但这里不多讲了
crop:

pad:
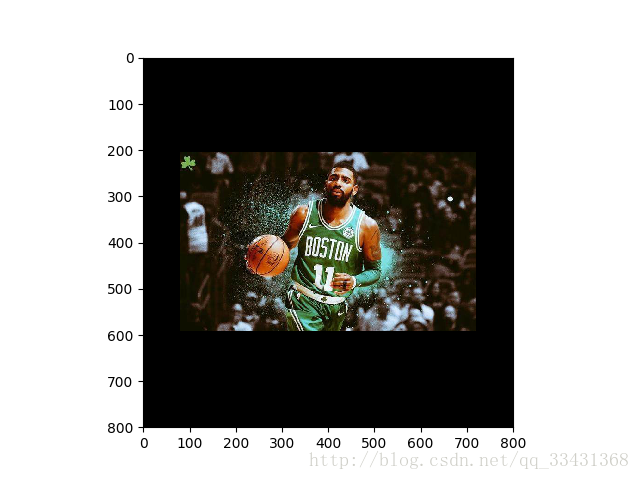
可以看出来如果尺寸大于原图的话周围都自动被填充成黑色
还可以通过比例进行调整图像的大小
第二个参数为比例大小0-1之间的数字
结果为

从代码函数的意思也很容易就理解
updown:

leftright :

transpose :
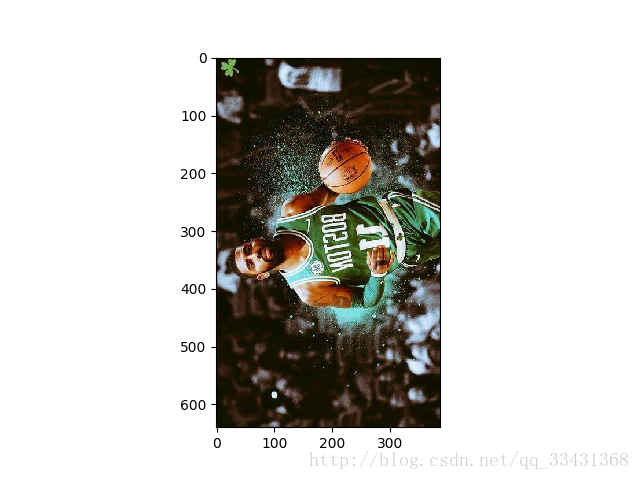
举一个很极端的例子,如果训练样本的目标都在左侧,最后训练出来的model可能就无法很好的识别目标在右侧的图片,所以随机的翻转照片可以性价比很高的在很大程度上缓解这个问题,这一方式也是很常见的。
Python: Python3.6
OS: win10
tf: 1.5.0
图片数据的预处理
所谓,预处理就是对训练图片提前进行一些处理,为什么要这么干呢??答案是 为了降低其他无关因素对最后的识别结果的影响,比如说一幅图片在不同亮度或是对比度等指标下呈现的效果可能差别特别大,但是这些对于我们来说,不要影响到最后的识别结果,所以这就是预处理最想解决的东西,其次通过预处理方式也可以让数据集更加多样化,随机化,可以让model更加健壮。
图像编码处理
彩色图片为RGB三个通道,所以可以看成一个三维矩阵,矩阵中的每一个数表示了图像上不同位置,不同颜色的亮度。然而对于图片的存储,并非直接存储这个矩阵,而是对图片进行编码之后存储的编码解码处理代码
1.首先展示一下我大欧文Kyrie_Irving.jpg
有详细的讲解注释
import matplotlib.pyplot as plt #导入这个包用来显示图片
import tensorflow as tf
#读取图像的原始图像 这里可能会出现decode‘utf-8’的error读用rb就搞定
#读入的为二进制流, ./yangmi.jpg 为当前程序文件夹的图片途径
#tf.gfile.FastGFile为tf自带的读取数据的操作函数
image_raw_data = tf.gfile.FastGFile('./Kyrie_Irving.jpg', 'rb',).read()
with tf.Session() as sess:
#对图片进行解码 二进制文件解码为uint8
img_data = tf.image.decode_jpeg(image_raw_data)
#输出图片数据(三维矩阵) 每个数字都为0-255之间的数字
print(img_data.eval())
#利用matplotlib显示图片
plt.imshow(img_data.eval())
plt.show()
#将图片转换为 float32类型 相当于归一化 矩阵中的数字为0-1之间的数字
#这个操作是对图片的大小调整等操作提供便利
img_data = tf.image.convert_image_dtype(img_data, dtype=tf.float32)
#图片按jpeg格式编码
encode_image = tf.image.encode_jpeg(img_data)
#创建文件并写入
with tf.gfile.GFile('./ouwen', 'wb') as f:
f.write(encode_image.eval())对没有错你会发现运行之后出error
这个错误的出现在jpeg编码位置,意思是进行jpeg编码需要的类型矩阵是uint8类型,而这里我把这个类型转换为了float32,所以先不管这个先去掉归一化操作之后的话我再用这个来操作。
import matplotlib.pyplot as plt
import tensorflow as tf
#读取图像的原始图像 这里可能会出现decode‘utf-8’的error 读用rb就搞定
image_raw_data = tf.gfile.FastGFile('./Kyrie_Irving.jpg', 'rb',).read()
with tf.Session() as sess:
#对图片进行解码 二进制文件解码为uint8
img_data = tf.image.decode_jpeg(image_raw_data)
#输出图片数据(三维矩阵)
print(img_data.eval())
#利用matplotlib显示图片
plt.imshow(img_data.eval())
plt.show()
#图片按jpeg格式编码
encode_image = tf.image.encode_jpeg(img_data)
#创建文件并写入
with tf.gfile.GFile('./ouwen', 'wb') as f:
f.write(encode_image.eval())输出:
三维矩阵
plt显示的图片
写入编码之后的文件
打开的时候选择image
显示
小总结
1.这里是对jpg图片格式的操作,tf中还有png的操作,这个在编写程序导包的时候很容易找到2.存储jpg图片的时候需要把图片转换成uint8类型
对图片预处理操作
图片大小调整
一般数据集都是不整齐的,如果自己准备数据集可能还是通过爬虫搞定的所以一般来讲图片的尺寸是大小不一的,但是神经网络的输入节点的个数是固定的,所以在图片预处理阶段应该需要对图片统一大小的操作
import matplotlib.pyplot as plt
import tensorflow as tf
#读取图像的原始图像 这里可能会出现decode‘utf-8’的error 读用rb就搞定
image_raw_data = tf.gfile.FastGFile('./Kyrie_Irving.jpg', 'rb',).read()
with tf.Session() as sess:
#对图片进行解码 二进制文件解码为uint8
img_data = tf.image.decode_jpeg(image_raw_data)
#利用matplotlib显示图片
plt.imshow(img_data.eval())
plt.show()
################ 主要程序
#将图片转换为 float32类型 相当于归一化
#这样方便对图像数据进行处理
img_data = tf.image.convert_image_dtype(img_data, dtype=tf.float32)
#重新大小 第二个参数和第二个参数都为调整后的图像的大小 method 是调整图像大小的方法
resizd = tf.image.resize_images(img_data, [200, 200], method=0)
plt.imshow(resizd.eval())
plt.show()
img_data = tf.image.convert_image_dtype(resizd, dtype=tf.uint8)
###########################
#图片按jpeg格式编码
encode_image = tf.image.encode_jpeg(img_data)
#创建文件并写入
with tf.gfile.GFile('./ouwen', 'wb') as f:
f.write(encode_image.eval())结果
大致程序在[b]***********[/b]两行这个之间
但是其实最主要的就是两句话
#这样方便对图像数据进行处理 img_data = tf.image.convert_image_dtype(img_data, dtype=tf.float32) #重新大小 第二个参数和第二个参数都为调整后的图像的大小 method 是调整图像大小的方法 resizd = tf.image.resize_images(img_data, [200, 200], method=0)
如果这里不对图片进行重新编码并且存储的话也不需要再把三维矩阵的值转换为uint8了
在以下的程序中我就省略这么完整的程序了,直接讲图片处理的函数
比如这里的
resizd = tf.image.resize_images(img_data, [200, 200], method=0)
method如上图所示,如果你学过数字图像处理,你应该不陌生,但这里不多讲了
图像剪裁或是填充
这里多说一句:其实这些函数都是英语单词的_的连接形式还是很好记的#参数: 输入图片数据, 改变尺寸 crop = tf.image.resize_image_with_crop_or_pad(img_data, 100, 100) pad = tf.image.resize_image_with_crop_or_pad(img_data, 800, 800)
crop:
pad:
可以看出来如果尺寸大于原图的话周围都自动被填充成黑色
还可以通过比例进行调整图像的大小
第二个参数为比例大小0-1之间的数字
central = tf.image.central_crop(img_data, 0.5)
结果为
图像翻转
updown = tf.image.flip_up_down(img_data) #上下镜像 leftright = tf.image.flip_left_right(img_data)#左右镜像 transpose = tf.image.transpose_image(img_data)#对角镜像
从代码函数的意思也很容易就理解
updown:
leftright :
transpose :
小总结
在很多图像识别问题中,图像的翻转一般不会影响识别的结果。于是在训练模型时采用随机翻转训练图像,这样训练出的模型可以更好的识别不同角度的实体。举一个很极端的例子,如果训练样本的目标都在左侧,最后训练出来的model可能就无法很好的识别目标在右侧的图片,所以随机的翻转照片可以性价比很高的在很大程度上缓解这个问题,这一方式也是很常见的。
updown = tf.image.random_flip_up_down(img_data) #随机上下镜像 leftright = tf.image.random_flip_left_right(img_data)#随机左右镜像
图片色彩调整
亮度调整
birght1 = tf.image.adjust_brightness(img_data, 0.5) birght2 = tf.image.adjust_brightness(img_data, -0.5)
对比度
contrast1 = tf.image.adjust_contrast(img_data, -5) contrast2 = tf.image.adjust_contrast(img_data, 5)
色相
hue = tf.image.adjust_hue(img_data, 0.1)
饱和度
saturation1 = tf.image.adjust_saturation(img_data, 1) saturation2 = tf.image.adjust_saturation(img_data, -1)
小总结
和图像翻转一样,图像的亮度、对比度、饱和度和色相在很多图像识别应用中都不会影响识别结果。所以和上述的思想一样也是随机的来调整图像的这些属性,从而可以使得训练得到的模型尽可能小的受这些无关因素的影响,这也是预处理的目标之一#[-max, max]随机 brightness= tf.image.random_brightness(img_data, max) #[lower, upper]随机 contrast= tf.image.random_contrast(img_data, lower, upper) #[-max, max]随机 max最大为0.5 hue = tf.image.random_hue(img_data, max) ##[lower, upper]随机 saturation = tf.image.random_saturation(img_data, lower, upper)

相关文章推荐
- 《TensorFlow学习笔记》对图片数据的预处理二、画标注框,预处理完整框架
- 基于j2me的图片特效(缩放,裁剪,调整大小,镜像,对比度亮度调整,黑白,线条,粉笔画)
- 数据绑定-2 (动态调整图片大小)
- 调整图片的饱和度,对比度,色彩,亮度,旋转图片
- C#图像处理(各种旋转、改变大小、柔化、锐化、雾化、底片、浮雕、黑白、滤镜效果,滤波,图像截取) 对图片的处理 : 亮度调整 抓屏 翻转 随鼠标画矩形
- PHP解码base64编码的图片例
- C++修改图片像素大小,求梯度,创建文件夹并读取文件数据,
- smartform中的图片大小调整问题
- post数据编码和解码的函数(C++)
- 对编码后的字节数组字符串进行Base64解码并生成图片
- iphone 图片URL地址编码、解码
- jquery实现div内图片水平左右滚动,滚动到最后一张停止、可根据需求调整图片数量及大小
- xvid 数据编码和解码
- C#和JAVA利用BASE64实现图片编码解码
- Oracle 11g笔记——调整表空间和数据文件的大小、移动数据文件、联机重做日志文件、控制文件
- 图片饱和度,色相,亮度调整
- C#图片处理之:色彩调整
- PHP获取远程图片并调整图像大小
- Flash本地传递大数据,图片数据,localconnection 超出大小,超出限制 bitmapdata
- C# 网络数据编码与解码(Encoder and Decoder)