一种基于状态机的 DOM 树生成技术(二)
2018-02-22 10:47
246 查看
摘要: 本文介绍了一种基于状态机的分词技术,设计了一个能够识别HTML 字符串中分词的状态机,并对状态机的运行流程做了细致的分析。欢迎点击「算法与编程之美」↑关注我们!
本文首发于微信公众号:"算法与编程之美",欢迎关注,及时了解更多此系列博客。
在上一篇https://my.oschina.net/gschen/blog/1618549我们给大家介绍了状态机的基本概念、设计思路以及基于 Java 语言的实现,希望大家能够了解相关知识点。状态机是我们后续介绍 DOM 树生成的关键技术,后面几篇博客都将基于状态机来实现。所以请大家务必掌握,如果还有不清楚的地方可以阅读之前的文章,也非常欢迎大家关注微信公众号,及时了解最新文章。
首先我们还是来回顾一下我们的任务,给定一个 HTML 文件,生成该文件的 DOM 树。一个 HTML 文件即一段采用 HTML 规则编写的字符串,如"<html><body><p>hello</p></body></html>"。
那么如何根据这样的一段字符串生成 DOM 树呢?
我们定义以下类型的分词,称每一个分词为 Token。
StartTag:开始标签如<html>。
EndTag:结束标签如</html>。
Character:StartTag 和 EndTag 之间的内容如 hello 。
EOF:结束标记。
针对这个字符串"<html><body><p>hello</p></body></html>",我们可以得到以下的分词:
StartTag:<html>
StartTag:<body>
StartTag:<p>
Character:hello
EndTag:</p>
EndTag:</body>
EndTag:</html>
现在我们已经明确了要达到什么目标,那么接下来如何实现将 HTML 字符串转化为一个个的分词呢?
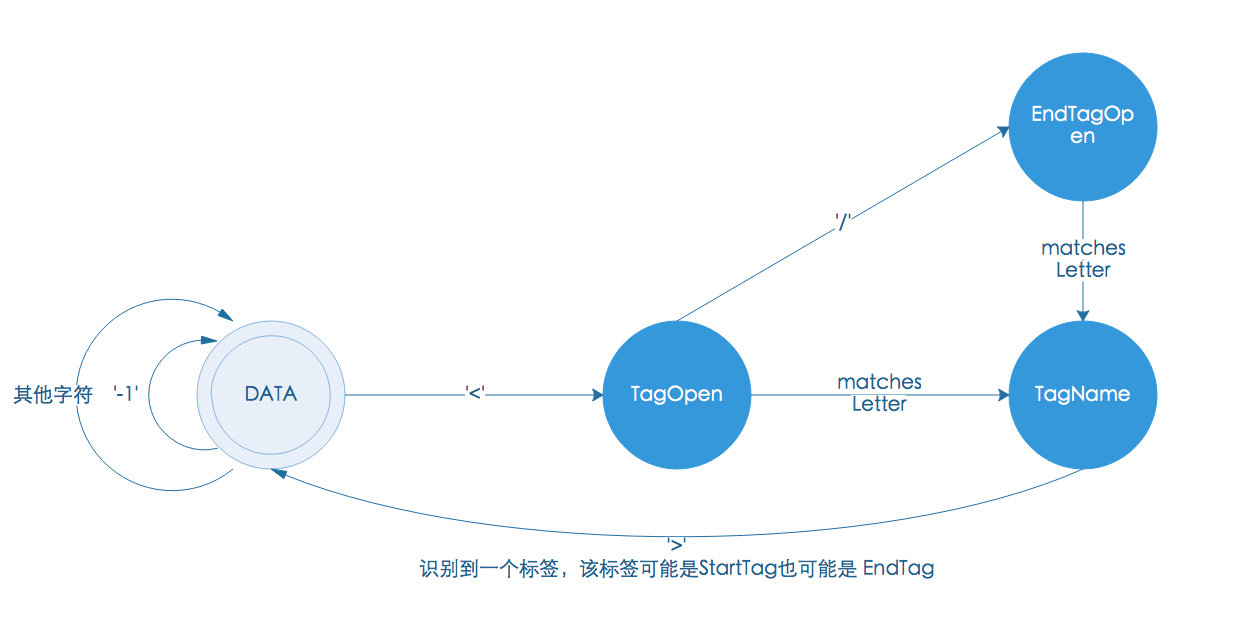
上图为实现第一节分词而设计的一个状态机,这个状态机屏蔽了很多错误处理环节,目的是为了让我们的描述更加简洁,让大家能够更加关注核心问题。我们来看一下这个状态机是如何设计的。
DATA:起始状态。
当输入字符为'-1'表示已经到达字符串的结尾,此时识别到一个分词 EOF。
当输入字符为'<',进入 TagOpen 状态。
输入字符为其他字符时,此时识别到一个分词 Character。
TagOpen:
当输入字符为'/'进入到 EndTagOpen 状态。
检测当前字符是否为字母,如果是则进入 TagName。
EndTagOpen:
检测当前字符是否为字母,如果是则进入 TagName。
TagName:
该状态将一次性读取所有字母,直到遇到'/'或'>'为止。
当下一个输入字符为'>',此时已经识别到一个HTML 标签,并将进入到 DATA。
接下来我们就将以一个实例来描述状态机的运行过程。
<html><body><p>hello</p></body></html>
当前输入为'<',将进入TagOpen。
<html><body><p>hello</p></body></html>
TagOpen检测到下一个字符为字母'h',进入 TagName。
TagName 一次性读取所有的字母 "html",此时识别到一个 StartTag,并做 token 识别完成标记。下一个输入为'>',进入 DATA 。
以上就是识别一个StartTag 的流程。body 和 p 类似,不再赘述。
<html><body><p>hello</p></body></html>
上述流程已经识别完成了三个StartTag 分词,分别是<html>、<body> 和< p>。
当前状态为 DATA且下一个输入字符为 'h',一次性读取所有的字母'hello'。此时识别到一个分词 Character,并做分词结束标记。
<html><body><p>hello</p></body></html>
当前状态为 DATA且下一个输入字符为'<',进入 TagOpen。
<html><body><p>hello</p></body></html>
当前状态为 TagOpen,且下一个输入字符为'/',进入 EndTagOpen,当前标签类型为 EndTag。
检测到下一个字符为字母,故进入 TagName 。
<html><body><p>hello</p></body></html>
TagName 状态下不停的读取字母。当遇到字符'>',标记这是一个分词,并进入到DATA。
后续的 DOM树生成将基于上述分词。下一讲我们将介绍如何利用 Java 语言实现这样的分词技术。如您在博客阅读的过程遇到任何的疑问,欢迎在下方留言。
本文所有代码可在以下 git 库中 day02模块中找到,git 地址为: https://gitee.com/gschen/sctu-treebuilder.git 感兴趣的同学可以提前阅读代码。

本文首发于微信公众号:"算法与编程之美",欢迎关注,及时了解更多此系列博客。
在上一篇https://my.oschina.net/gschen/blog/1618549我们给大家介绍了状态机的基本概念、设计思路以及基于 Java 语言的实现,希望大家能够了解相关知识点。状态机是我们后续介绍 DOM 树生成的关键技术,后面几篇博客都将基于状态机来实现。所以请大家务必掌握,如果还有不清楚的地方可以阅读之前的文章,也非常欢迎大家关注微信公众号,及时了解最新文章。
首先我们还是来回顾一下我们的任务,给定一个 HTML 文件,生成该文件的 DOM 树。一个 HTML 文件即一段采用 HTML 规则编写的字符串,如"<html><body><p>hello</p></body></html>"。
那么如何根据这样的一段字符串生成 DOM 树呢?
1 分词
我们称第一阶段为分词,要想最终生成一颗 DOM树,我们并不是一个字符一个字符的处理,而是将HTML 字符串首先进行分词,然后再一个分词一个分词的处理。我们定义以下类型的分词,称每一个分词为 Token。
StartTag:开始标签如<html>。
EndTag:结束标签如</html>。
Character:StartTag 和 EndTag 之间的内容如 hello 。
EOF:结束标记。
针对这个字符串"<html><body><p>hello</p></body></html>",我们可以得到以下的分词:
StartTag:<html>
StartTag:<body>
StartTag:<p>
Character:hello
EndTag:</p>
EndTag:</body>
EndTag:</html>
现在我们已经明确了要达到什么目标,那么接下来如何实现将 HTML 字符串转化为一个个的分词呢?
2 利用状态机实现分词
在上一篇博客我们给大家介绍了状态机的基本知识,本节我们将介绍一种基于状态机的分词技术。上图为实现第一节分词而设计的一个状态机,这个状态机屏蔽了很多错误处理环节,目的是为了让我们的描述更加简洁,让大家能够更加关注核心问题。我们来看一下这个状态机是如何设计的。
DATA:起始状态。
当输入字符为'-1'表示已经到达字符串的结尾,此时识别到一个分词 EOF。
当输入字符为'<',进入 TagOpen 状态。
输入字符为其他字符时,此时识别到一个分词 Character。
TagOpen:
当输入字符为'/'进入到 EndTagOpen 状态。
检测当前字符是否为字母,如果是则进入 TagName。
EndTagOpen:
检测当前字符是否为字母,如果是则进入 TagName。
TagName:
该状态将一次性读取所有字母,直到遇到'/'或'>'为止。
当下一个输入字符为'>',此时已经识别到一个HTML 标签,并将进入到 DATA。
接下来我们就将以一个实例来描述状态机的运行过程。
<html><body><p>hello</p></body></html>
当前输入为'<',将进入TagOpen。
<html><body><p>hello</p></body></html>
TagOpen检测到下一个字符为字母'h',进入 TagName。
TagName 一次性读取所有的字母 "html",此时识别到一个 StartTag,并做 token 识别完成标记。下一个输入为'>',进入 DATA 。
以上就是识别一个StartTag 的流程。body 和 p 类似,不再赘述。
<html><body><p>hello</p></body></html>
上述流程已经识别完成了三个StartTag 分词,分别是<html>、<body> 和< p>。
当前状态为 DATA且下一个输入字符为 'h',一次性读取所有的字母'hello'。此时识别到一个分词 Character,并做分词结束标记。
<html><body><p>hello</p></body></html>
当前状态为 DATA且下一个输入字符为'<',进入 TagOpen。
<html><body><p>hello</p></body></html>
当前状态为 TagOpen,且下一个输入字符为'/',进入 EndTagOpen,当前标签类型为 EndTag。
检测到下一个字符为字母,故进入 TagName 。
<html><body><p>hello</p></body></html>
TagName 状态下不停的读取字母。当遇到字符'>',标记这是一个分词,并进入到DATA。
3 总结
本文介绍了一种基于状态机的分词技术,设计了一个能够识别HTML 字符串中分词的状态机,并对状态机的运行流程做了细致的分析。后续的 DOM树生成将基于上述分词。下一讲我们将介绍如何利用 Java 语言实现这样的分词技术。如您在博客阅读的过程遇到任何的疑问,欢迎在下方留言。
本文所有代码可在以下 git 库中 day02模块中找到,git 地址为: https://gitee.com/gschen/sctu-treebuilder.git 感兴趣的同学可以提前阅读代码。

相关文章推荐
- 一种基于状态机的 DOM 树生成技术(一)
- 一种基于状态机的 DOM 树生成技术(2)
- 一种基于状态机的 DOM 树生成技术(1)
- 一种基于状态机的 DOM 树生成技术(1)
- 一种基于 HTTP 长连接的“服务器推”技术在web端的应用
- 执法文书打印的实现(二):基于freemaker技术生成可打印的word文档
- 基于C语言的状态机实现技术
- [醒目] 自动生成hql[基于javabean的操作][Java reflect 技术的体现]
- 基于PHP的一种Cache回调与自动触发技术
- YbSoftwareFactory 代码生成插件【九】:基于JQuery、WebApi的ASP.NET MVC插件的代码生成项目主要技术解析
- 基于PHP与XML的PDF文档生成技术
- 基于 Eclipse 平台的代码生成技术
- 基于强化学习的文本生成技术
- 演示使用DOM技术如何根据指定XML,进行相应的修改然后生成新的XML文档
- 基于动态代码生成技术的动态对象工厂
- 基于动态代码生成技术的动态对象工厂
- 一种基于HBase韵海量图片存储技术
- 基于JQuery、WebApi的ASP.NET MVC插件的代码生成项目主要技术解析
- 真正的创新必然是基于对市场的了解,对客户反馈的观察,开发出来的产品一定要适应市场,提出的模式一定要能解决现实的问题。而在这其中,技术只是一种实现手段。
- 一种基于空间数据库和SVG的高速Web电子地图的生成及应用方法