RGBD-SLAM学习6
2018-02-18 23:46
316 查看
整个第六讲其实就是增加了g2o优化部分
在看g2o时,看到了贺大神的博文,优化部分的简单举例感觉非常好,非常有代入感的介绍了什么是优化,为什么要优化,如何操作等问题。其实更高维度的优化核心逻辑是一样的,只是操作起来复杂,需要更高级的操作。
http://blog.csdn.net/heyijia0327/article/details/47686523
转过来看高博的RGBD,先贴一下代码:
整体框架也很简单,在之前的基础上增加了g2o优化,除了g2o本身需要的初始化部分;另外就是在循环计算每帧之间运动时,把每个顶点和边同时add进g2o优化器中;还有最后的整体优化部分。
第一部分:
初始化,拆解开看:
其实最核心的主干代码就这一句:
字面意思是创建一个g2o稀疏优化器,将其命名为
这个
OK,构造优化算法传进去就是了:
问题又来了,构造优化算法需要传入什么参数呢?块求解器!也就是上面的blocksolver。
构造一下吧:
好,这里我们又发现了一个linearSolver的东东。。。
构造块求解器需要传入线性求解器,继续构造吧:
注意就是线性稀疏求解器是模板类,需要传入顶点类型,这里就用的现成的,6*3块求解器中的位姿矩阵类型。
OK,连环套终于到了最底层,因为linearSolver的构造不再需要参数。
整个逻辑流程是:
求解器需要设置优化算法;
优化算法需要块求解器;
块求解器需要线性求解器;
写一个不是代码的东西:
对应到代码书写流程上:
用linearsolver构造blocksolver;
用blocksolver构造optimizationAlgorithm;
用optimizationAlgorithm设置optimizer.setAlgorithm()
另外,高博的代码中为了简化,用了两个typedef:
分别来代替块求解器和线性求解器的类型。为了思路看起来清晰一些,所以这里将他们都带入进去了。想简化的话,可以用auto。
第二部分:
在循环中往g2o增加顶点和边:
顶点很简单,设置下ID。说是ID,其实就是一个号,第几个地点。设定下估计值,这里就是单位矩阵了,因为并没有预先估计值。最后add方法,添加进去就好了:
边稍微复杂一些:
分成三小块看:
1、设置链接的顶点,由于每个边链接两个顶点,所以是二元边,所以在
2、设置信息矩阵,注意的是信息矩阵是个6*6的矩阵,初始为单位阵,权重都一样,根据位置去调整不同权重。00 11 22为位置,33 44 55为角度,所以分开写了。设定好
3、一定注意,边的估计值是pnp求解之结果:
第四部分:
整体优化
精简掉显示输出和文件输出后,最核心的只有两句:
在最后的解释部分,说一个点。
顶点取成了相机姿态:g2o::VertexSE3,而边则是连接两个VertexSE3的边:g2o::EdgeSE3
可以发现顶点和边其实本质都是SE3,没有本质区别。上一张图:
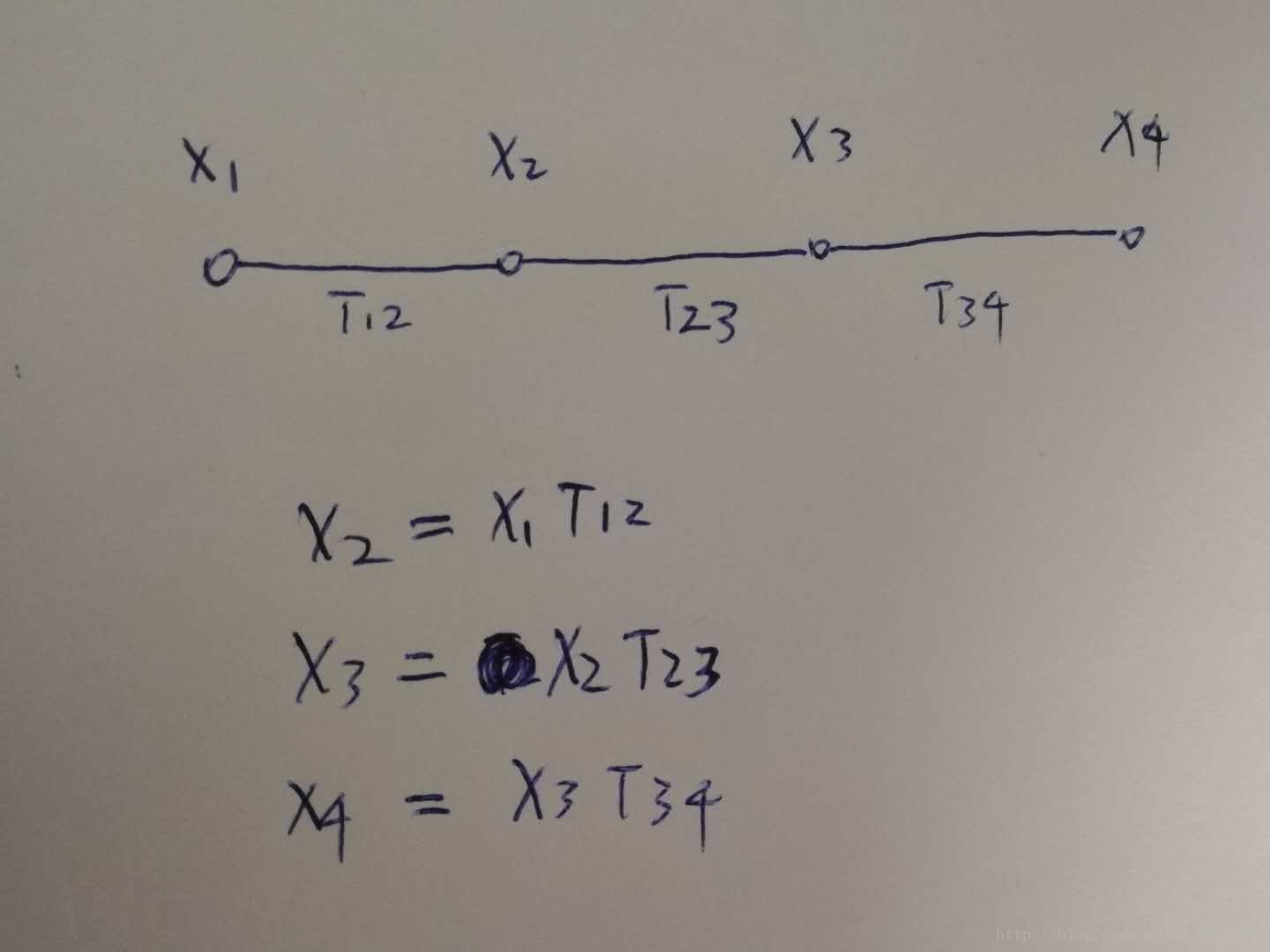
这个图就是位姿图,只包含位姿X和变换T。
假如将X1X1 设定为初始姿态,且位置和旋转都设定为0,此时对应的位姿矩阵是单位阵(旋转零向量通过rodrigus公式转换成旋转矩阵是单位阵!):
Xzero=⎡⎣⎢⎢⎢⎢1000010000100001⎤⎦⎥⎥⎥⎥Xzero=[1000010000100001]
此点切记!
OK,我们的顶点:X1,X2,X3,X4X1,X2,X3,X4 ;边:T12,T23,T34T12,T23,T34
关系式为:
X2=X1T12X3=X2T23X4=X3T34X2=X1T12X3=X2T23X4=X3T34
其实将中间量全部带入后得到:
X2=X1T12X3=X1T12T23X4=X1T12T23T34X2=X1T12X3=X1T12T23X4=X1T12T23T34
又由于X1X1为单位阵,所以最终各个顶点是这样的:
X2=T12X3=T12T23X4=T12T23T34X2=T12X3=T12T23X4=T12T23T34
这里发现,其实顶点也就是一些变换(边)的组合,只不过是各个边变换累积起来的。直观的理解就是,边是相邻顶点,单一节的变换,而顶点就是将单节累积起来,当前位姿相对于初始位姿的一个总变换(这里默认了初始位姿是0状态,其实是不是0都一样。。。)。
最后说一句就是,位姿图的运算是位姿在左,变换在右,得到新的位姿:
X2=X1T12X2=X1T12
而在坐标系变换坐标时则是左乘:
PX2=T12PX1PX2=T12PX1
PX1PX1为在X1X1位姿下看到空间中P点的坐标、PX2PX2为在X2X2位姿下看到空间中P点的坐标。
在看g2o时,看到了贺大神的博文,优化部分的简单举例感觉非常好,非常有代入感的介绍了什么是优化,为什么要优化,如何操作等问题。其实更高维度的优化核心逻辑是一样的,只是操作起来复杂,需要更高级的操作。
http://blog.csdn.net/heyijia0327/article/details/47686523
转过来看高博的RGBD,先贴一下代码:
#include <iostream>
#include <fstream>
#include <sstream>
using namespace std;
#include "slamBase.h"
//g2o的头文件
#include <g2o/types/slam3d/types_slam3d.h> //顶点类型
#include <g2o/core/sparse_optimizer.h>
#include <g2o/core/block_solver.h>
#include <g2o/core/factory.h>
#include <g2o/core/optimization_algorithm_factory.h>
#include <g2o/core/optimization_algorithm_gauss_newton.h>
#include <g2o/solvers/csparse/linear_solver_csparse.h>
#include <g2o/core/robust_kernel.h>
#include <g2o/core/robust_kernel_factory.h>
#include <g2o/core/optimization_algorithm_levenberg.h>
// 给定index,读取一帧数据
FRAME readFrame( int index, ParameterReader& pd );
// 估计一个运动的大小
double normofTransform( cv::Mat rvec, cv::Mat tvec );
int main( int argc, char** argv )
{
// 前面部分和vo是一样的
ParameterReader pd;
int startIndex = atoi( pd.getData( "start_index" ).c_str() );
int endIndex = atoi( pd.getData( "end_index" ).c_str() );
// initialize
cout<<"Initializing ..."<<endl;
int currIndex = startIndex; // 当前索引为currIndex
FRAME lastFrame = readFrame( currIndex, pd ); // 上一帧数据
// 我们总是在比较currFrame和lastFrame
string detector = pd.getData( "detector" );
string descriptor = pd.getData( "descriptor" );
CAMERA_INTRINSIC_PARAMETERS camera = getDefaultCamera();
computeKeyPointsAndDesp( lastFrame, detector, descriptor );
PointCloud::Ptr cloud = image2PointCloud( lastFrame.rgb, lastFrame.depth, camera );
pcl::visualization::CloudViewer viewer("viewer");
// 是否显示点云
bool visualize = pd.getData("visualize_pointcloud")==string("yes");
int min_inliers = atoi( pd.getData("min_inliers").c_str() );
double max_norm = atof( pd.getData("max_norm").c_str() );
/*******************************
// 新增:有关g2o的初始化
*******************************/
// 选择优化方法
typedef g2o::BlockSolver_6_3 SlamBlockSolver;
typedef g2o::LinearSolverCSparse< SlamBlockSolver::PoseMatrixType > SlamLinearSolver;
// 初始化求解器
SlamLinearSolver* linearSolver = new SlamLinearSolver();
linearSolver->setBlockOrdering( false );
SlamBlockSolver* blockSolver = new SlamBlockSolver( linearSolver );
g2o::OptimizationAlgorithmLevenberg* solver = new g2o::OptimizationAlgorithmLevenberg( blockSolver );
g2o::SparseOptimizer globalOptimizer; // 最后用的就是这个东
1e378
东
globalOptimizer.setAlgorithm( solver );
// 不要输出调试信息
globalOptimizer.setVerbose( false );
// 向globalOptimizer增加第一个顶点
g2o::VertexSE3* v = new g2o::VertexSE3();
v->setId( currIndex );
v->setEstimate( Eigen::Isometry3d::Identity() ); //估计为单位矩阵
v->setFixed( true ); //第一个顶点固定,不用优化
globalOptimizer.addVertex( v );
int lastIndex = currIndex; // 上一帧的id
for ( currIndex=startIndex+1; currIndex<endIndex; currIndex++ )
{
cout<<"Reading files "<<currIndex<<endl;
FRAME currFrame = readFrame( currIndex,pd ); // 读取currFrame
computeKeyPointsAndDesp( currFrame, detector, descriptor );
// 比较currFrame 和 lastFrame
RESULT_OF_PNP result = estimateMotion( lastFrame, currFrame, camera );
if ( result.inliers < min_inliers ) //inliers不够,放弃该帧
continue;
// 计算运动范围是否太大
double norm = normofTransform(result.rvec, result.tvec);
cout<<"norm = "<<norm<<endl;
if ( norm >= max_norm )
continue;
Eigen::Isometry3d T = cvMat2Eigen( result.rvec, result.tvec );
cout<<"T="<<T.matrix()<<endl;
// cloud = joinPointCloud( cloud, currFrame, T, camera );
// 向g2o中增加这个顶点与上一帧联系的边
// 顶点部分
// 顶点只需设定id即可
g2o::VertexSE3 *v = new g2o::VertexSE3();
v->setId( currIndex );
v->setEstimate( Eigen::Isometry3d::Identity() );
globalOptimizer.addVertex(v);
// 边部分
g2o::EdgeSE3* edge = new g2o::EdgeSE3();
// 连接此边的两个顶点id
edge->vertices() [0] = globalOptimizer.vertex( lastIndex );
edge->vertices() [1] = globalOptimizer.vertex( currIndex );
// 信息矩阵
Eigen::Matrix<double, 6, 6> information = Eigen::Matrix< double, 6,6 >::Identity();
// 信息矩阵是协方差矩阵的逆,表示我们对边的精度的预先估计
// 因为pose为6D的,信息矩阵是6*6的阵,假设位置和角度的估计精度均为0.1且互相独立
// 那么协方差则为对角为0.01的矩阵,信息阵则为100的矩阵
information(0,0) = information(1,1) = information(2,2) = 100;
information(3,3) = information(4,4) = information(5,5) = 100;
// 也可以将角度设大一些,表示对角度的估计更加准确
edge->setInformation( information );
// 边的估计即是pnp求解之结果
edge->setMeasurement( T );
// 将此边加入图中
globalOptimizer.addEdge(edge);
lastFrame = currFrame;
lastIndex = currIndex;
}
// pcl::io::savePCDFile( "data/result.pcd", *cloud );
// 优化所有边
cout<<"optimizing pose graph, vertices: "<<globalOptimizer.vertices().size()<<endl;
globalOptimizer.save("./data/result_before.g2o");
globalOptimizer.initializeOptimization();
globalOptimizer.optimize( 100 ); //可以指定优化步数
globalOptimizer.save( "./data/result_after.g2o" );
cout<<"Optimization done."<<endl;
globalOptimizer.clear();
return 0;
}
FRAME readFrame( int index, ParameterReader& pd )
{
...//省略掉了,有点长。。。
}
double normofTransform( cv::Mat rvec, cv::Mat tvec )
{
...//省略掉了,有点长。。。
}整体框架也很简单,在之前的基础上增加了g2o优化,除了g2o本身需要的初始化部分;另外就是在循环计算每帧之间运动时,把每个顶点和边同时add进g2o优化器中;还有最后的整体优化部分。
第一部分:
初始化,拆解开看:
其实最核心的主干代码就这一句:
g2o::SparseOptimizer globalOptimizer;
字面意思是创建一个g2o稀疏优化器,将其命名为
globalOptimizer。这一句是核心主干,其他都是辅助。
这个
globalOptimizer需要设置一下优化算法,用
globalOptimizer.setAlgorithm( 这里得传进来一个优化算法 );方法进行设置。这个方法需要传入一个优化算法,不论是GN,LM,DL等等,反正你得是个优化算法。
OK,构造优化算法传进去就是了:
g2o::OptimizationAlgorithmLevenberg* solver = new g2o::OptimizationAlgorithmLevenberg( blockSolver );构造了一个LM算法,将其命名为solver (这里感觉这名字不是很贴切,可以命名为OptimizationAlgorithm)。
问题又来了,构造优化算法需要传入什么参数呢?块求解器!也就是上面的blocksolver。
构造一下吧:
g2o::BlockSolver_6_3 blockSolver = new g2o::BlockSolver_6_3(linearSolver) ;
好,这里我们又发现了一个linearSolver的东东。。。
构造块求解器需要传入线性求解器,继续构造吧:
g2o::LinearSolverCSparse< g2o::BlockSolver_6_3::PoseMatrixType >* linearSolver = new g2o::LinearSolverCSparse< g2o::BlockSolver_6_3::PoseMatrixType >();
注意就是线性稀疏求解器是模板类,需要传入顶点类型,这里就用的现成的,6*3块求解器中的位姿矩阵类型。
OK,连环套终于到了最底层,因为linearSolver的构造不再需要参数。
整个逻辑流程是:
求解器需要设置优化算法;
优化算法需要块求解器;
块求解器需要线性求解器;
写一个不是代码的东西:
optimizer.setAlgorithm( optimizationAlgorithm( blocksolver( linearsolver ) ) )
对应到代码书写流程上:
用linearsolver构造blocksolver;
用blocksolver构造optimizationAlgorithm;
用optimizationAlgorithm设置optimizer.setAlgorithm()
另外,高博的代码中为了简化,用了两个typedef:
typedef g2o::BlockSolver_6_3 SlamBlockSolver; typedef g2o::LinearSolverCSparse< SlamBlockSolver::PoseMatrixType > SlamLinearSolver;
分别来代替块求解器和线性求解器的类型。为了思路看起来清晰一些,所以这里将他们都带入进去了。想简化的话,可以用auto。
第二部分:
在循环中往g2o增加顶点和边:
顶点很简单,设置下ID。说是ID,其实就是一个号,第几个地点。设定下估计值,这里就是单位矩阵了,因为并没有预先估计值。最后add方法,添加进去就好了:
// 顶点部分 // 顶点只需设定id即可 g2o::VertexSE3 *v = new g2o::VertexSE3(); v->setId( currIndex ); v->setEstimate( Eigen::Isometry3d::Identity() ); globalOptimizer.addVertex(v);
边稍微复杂一些:
// 边部分 g2o::EdgeSE3* edge = new g2o::EdgeSE3(); // 连接此边的两个顶点id edge->vertices() [0] = globalOptimizer.vertex( lastIndex ); edge->vertices() [1] = globalOptimizer.vertex( currIndex ); // 信息矩阵 Eigen::Matrix<double, 6, 6> information = Eigen::Matrix< double, 6,6 >::Identity(); // 信息矩阵是协方差矩阵的逆,表示我们对边的精度的预先估计 // 因为pose为6D的,信息矩阵是6*6的阵,假设位置和角度的估计精度均为0.1且互相独立 // 那么协方差则为对角为0.01的矩阵,信息阵则为100的矩阵 information(0,0) = information(1,1) = information(2,2) = 100; information(3,3) = information(4,4) = information(5,5) = 100; // 也可以将角度设大一些,表示对角度的估计更加准确 edge->setInformation( information ); // 边的估计即是pnp求解之结果 edge->setMeasurement( T ); // 将此边加入图中 globalOptimizer.addEdge(edge);
分成三小块看:
1、设置链接的顶点,由于每个边链接两个顶点,所以是二元边,所以在
edge->vertices() [0]中只有
[0]和
[1]这个索引指的是每条边链接的点个数,二元边就链接两个,则设置[0][1]。同理,要是一元边,只需设置[0],三元边就是[0][1][2]这种,以此类推。
2、设置信息矩阵,注意的是信息矩阵是个6*6的矩阵,初始为单位阵,权重都一样,根据位置去调整不同权重。00 11 22为位置,33 44 55为角度,所以分开写了。设定好
edge->setInformation( information );进行设定即可。
3、一定注意,边的估计值是pnp求解之结果:
edge->setMeasurement( T );因为边是测量值,而顶点是估计值。整个优化过程是优化顶点的估计值,以此来更好的满足观测值边!所以顶点初始估计值可以没有,随着优化迭代会慢慢的接近最优值。
第四部分:
整体优化
// 优化所有边
cout<<"optimizing pose graph, vertices: "<<globalOptimizer.vertices().size()<<endl;
globalOptimizer.save("./data/result_before.g2o");
globalOptimizer.initializeOptimization();
globalOptimizer.optimize( 100 ); //可以指定优化步数
globalOptimizer.save( "./data/result_after.g2o" );
cout<<"Optimization done."<<endl;
globalOptimizer.clear();精简掉显示输出和文件输出后,最核心的只有两句:
globalOptimizer.initializeOptimization(); //初始化 globalOptimizer.optimize( 100 );//开始迭代,设定次数为100次。
在最后的解释部分,说一个点。
顶点取成了相机姿态:g2o::VertexSE3,而边则是连接两个VertexSE3的边:g2o::EdgeSE3
可以发现顶点和边其实本质都是SE3,没有本质区别。上一张图:
这个图就是位姿图,只包含位姿X和变换T。
假如将X1X1 设定为初始姿态,且位置和旋转都设定为0,此时对应的位姿矩阵是单位阵(旋转零向量通过rodrigus公式转换成旋转矩阵是单位阵!):
Xzero=⎡⎣⎢⎢⎢⎢1000010000100001⎤⎦⎥⎥⎥⎥Xzero=[1000010000100001]
此点切记!
OK,我们的顶点:X1,X2,X3,X4X1,X2,X3,X4 ;边:T12,T23,T34T12,T23,T34
关系式为:
X2=X1T12X3=X2T23X4=X3T34X2=X1T12X3=X2T23X4=X3T34
其实将中间量全部带入后得到:
X2=X1T12X3=X1T12T23X4=X1T12T23T34X2=X1T12X3=X1T12T23X4=X1T12T23T34
又由于X1X1为单位阵,所以最终各个顶点是这样的:
X2=T12X3=T12T23X4=T12T23T34X2=T12X3=T12T23X4=T12T23T34
这里发现,其实顶点也就是一些变换(边)的组合,只不过是各个边变换累积起来的。直观的理解就是,边是相邻顶点,单一节的变换,而顶点就是将单节累积起来,当前位姿相对于初始位姿的一个总变换(这里默认了初始位姿是0状态,其实是不是0都一样。。。)。
最后说一句就是,位姿图的运算是位姿在左,变换在右,得到新的位姿:
X2=X1T12X2=X1T12
而在坐标系变换坐标时则是左乘:
PX2=T12PX1PX2=T12PX1
PX1PX1为在X1X1位姿下看到空间中P点的坐标、PX2PX2为在X2X2位姿下看到空间中P点的坐标。

相关文章推荐
- RGBD-SLAM V2的学习和测试(一)
- RGBD-SLAM学习5
- RGBD-SLAM学习3
- RGBD-SLAM学习1
- ORB_SLAM2初学习——RGBD
- RGBD-SLAM V2的学习和测试(二)
- RGBD-SLAM学习4
- RGBD-SLAM V2的学习和测试
- RGBD-SLAM学习2
- SLAM学习--三维空间刚体运动
- SLAM学习——后端(一)
- SLAM学习--开源测试数据集合
- 从零开始学习SLAM
- 【学习】视觉SLAM资源集锦
- ros学习笔记 - 深度传感器转换成激光数据(hector_slam)
- 学习SLAM需要哪些预备知识?
- SLAM学习资料汇总-超全
- 从零开始学习SLAM
- ROS+SLAM学习日志(2)基础
- SLAM学习——相机与图像