如何在E-MapReduce上提交Storm作业处理Kafka数据
2018-02-11 17:29
405 查看
点击有惊喜
本文演示如何在E-MapReduce上部署Storm集群和Kafka集群,并运行Storm作业消费Kafka数据。
这里我选择在杭州Region进行测试,版本选择EMR-3.8.0,本次测试需要的组件版本有:
Kafka:2.11_1.0.0
Storm: 1.0.1
E-MapReduce的集群管理界面地址:https://emr.console.aliyun.com/console#/cn-hangzhou/
由于Zookeeper和Storm组件默认不是必选的,所以在创建集群时需要记得勾选上,如下:
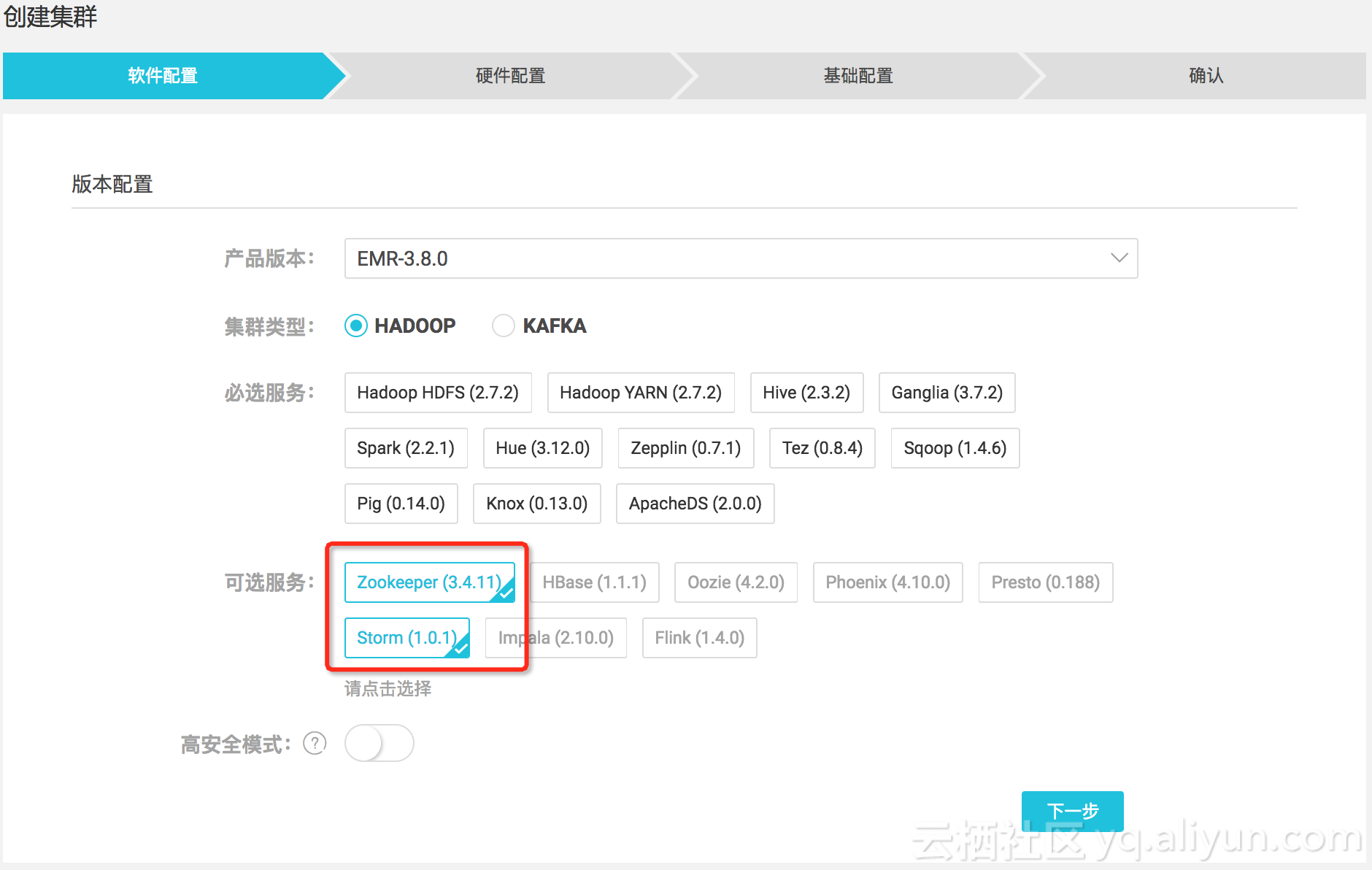
详细创建集群步骤,请参考E-MapReduce-用户指南-集群一节。
接着创建Kafka集群,集群类型选择Kafka,如下:
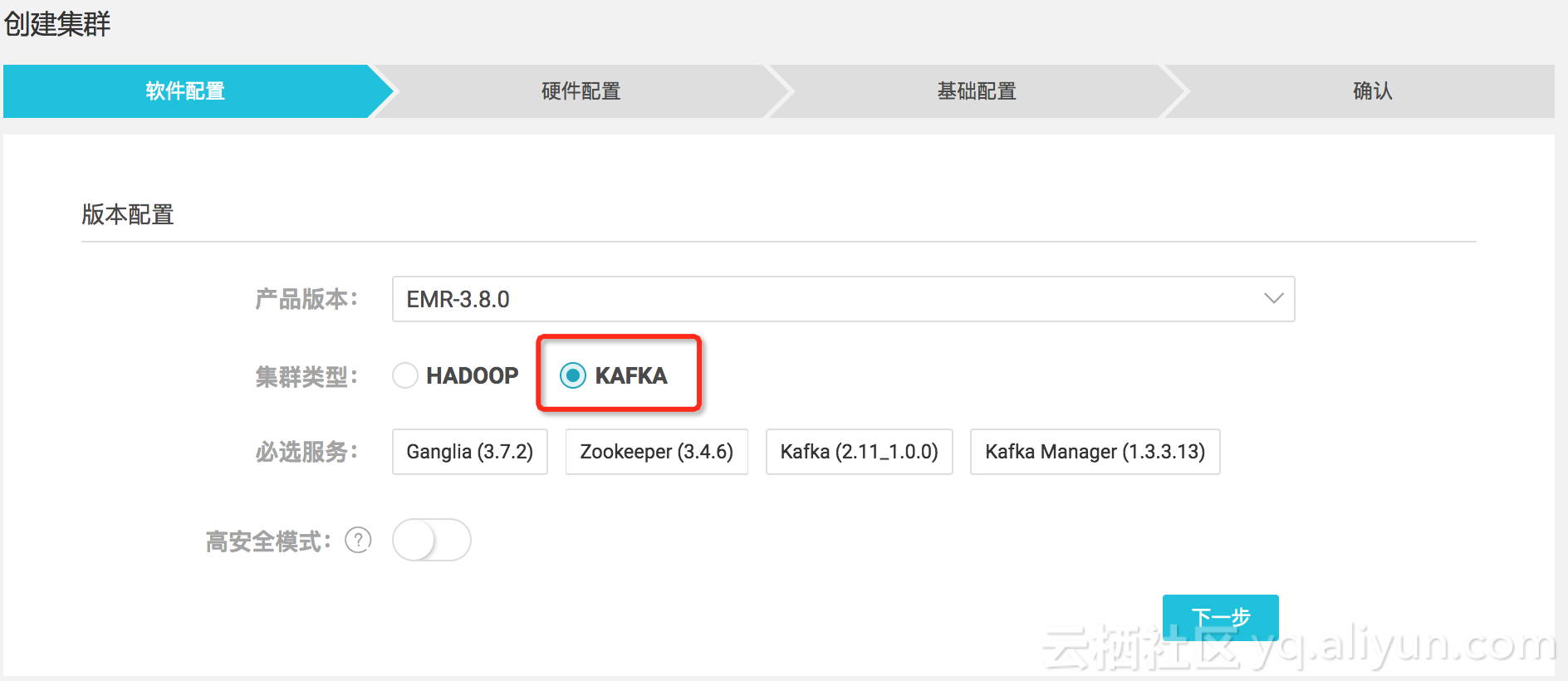
注意:
如果使用经典网络,请注意将Hadoop集群和Kafka集群放置在同一个安全组下面,这样可以省去配置安全组,避免网络不通的问题。
如果使用VPC网络,请注意将Hadoop集群和Kafka集群放置在同一个VPC/VSwitch以及安全组下面,这样同样省去配置网路和安全组,避免网络不通。
如果你熟悉ECS的网络和安全组,可以按需配置。
点击有惊喜

0. 序言
本文演示如何在E-MapReduce上部署Storm集群和Kafka集群,并运行Storm作业消费Kafka数据。
1. 准备环境
这里我选择在杭州Region进行测试,版本选择EMR-3.8.0,本次测试需要的组件版本有:Kafka:2.11_1.0.0
Storm: 1.0.1
E-MapReduce的集群管理界面地址:https://emr.console.aliyun.com/console#/cn-hangzhou/
1.1 创建Hadoop集群
由于Zookeeper和Storm组件默认不是必选的,所以在创建集群时需要记得勾选上,如下:详细创建集群步骤,请参考E-MapReduce-用户指南-集群一节。
1.2 创建Kafka集群
接着创建Kafka集群,集群类型选择Kafka,如下:注意:
如果使用经典网络,请注意将Hadoop集群和Kafka集群放置在同一个安全组下面,这样可以省去配置安全组,避免网络不通的问题。
如果使用VPC网络,请注意将Hadoop集群和Kafka集群放置在同一个VPC/VSwitch以及安全组下面,这样同样省去配置网路和安全组,避免网络不通。
如果你熟悉ECS的网络和安全组,可以按需配置。
点击有惊喜

相关文章推荐
- 大数据处理 Hadoop、HBase、ElasticSearch、Storm、Kafka、Spark
- 【storm-kafka】storm和kafka结合处理流式数据
- MapReduce 中如何处理HBase中的数据?如何读取HBase数据给Map?如何将结果存储到HBase中?
- springmvc使用实体类接收表单提交数据中含有String类型对应Date类型的不匹配报错400时如何处理
- 实时数据处理环境搭建flume+kafka+storm:3.kafka安装
- 实时数据处理环境搭建flume+kafka+storm:4.storm安装配置
- Flume+Kafka+Storm+Redis构建大数据实时处理系统 - 大数据
- Flume+Kafka+Storm+Redis构建大数据实时处理系统 - 大数据
- MapReduce源码解读系列之——作业如何提交到JobTracker
- MapReduce 中如何处理HBase中的数据?如何读取HBase数据给Map?如何将结果存储到HBase中?
- mapreduce和storm两者处理数据的区别!
- Flume+Kafka+Storm+Redis构建大数据实时处理系统:实时统计网站PV、UV+展示
- 大数据处理 Hadoop、HBase、ElasticSearch、Storm、Kafka、Spark
- Apache Storm 与 Spark:对实时处理数据,如何选择【翻译】
- 实时数据处理插件开发flume+kafka+storm:flume
- (大数据之MapReduce) Hadoop作业提交分析(四)
- logstash 如何处理 mongodb 导出来的 _id value数据。 how to custom fields of logstash by mongo mapreduce exported data.(example format: {_id:"xxx"} , value:{})
- MapReduce 中如何处理HBase中的数据?如何读取HBase数据给Map?如何将结果存储到HBase中?
- storm kafka出现错误或fail后,是否继续处理数据?
- 实时数据处理环境搭建flume+kafka+storm:1.zookeeper 安装配置