机器学习基石ch3
2018-02-11 11:28
148 查看
三、Types of Learning
各种类型的机器学习问题。3.1 Learning with Different Output Space
不同类型的输出空间。3.1.1 binary classification
二元分类问题。前两章中提到的银行发信用卡问题就是一个典型的二元分类问题,其输出空间只包含两个标记+1和-1,分别对应着发卡与不发卡。当然二元分类问题包含多种情况,如2.3节中提到过,如图3-1所示。

图3-1 a) 线性可分 b) 线性不可分包含噪音 c) 多项式可分
图3-1a为线性可分(linear binary separable),如可以使用PLA求解;b是包含噪音可以使用pocket求解,而c会在后面章节中详细叙述,属于多项式可分解。当然解决以上三种二元分类问题的机器学习方法很多,因为二元分类问题是机器学习中很重要、核心的问题。
3.1.2 Multiclass Classification
多元分类。有二元分类,就不难想到多元分类的问题,该类问题输出标签不止两种,而是{1,2,…,K}。这在人们的生活中非常常见,比如给水果的图像分类,识别硬币等等,其主要的应用场景就是模式识别。
3.1.3 Regression
回归分析。该问题的输出空间为整个实数集上或者在一定的实数范围内,这和前面讲的分类问题完全不一样,该输出不是一种毫无意义的标记,而是有实际意义的输出值。比如给定一个大气数据可以推出明天的天气等等之类的问题。统计学习对该类问题的研究比较成熟。
3.1.4 Structured Learning
结构学习。当然还有其他更为复杂的问题,比如很多很多类型的分类问题。
3.2 Learning with Different Data Label
不同的数据标记。3.2.1 Supervised Learning
监督学习。知道数据输入的同时还知道数据的标记。就相当于告诉你题目的同时还告诉你答案,让你在这种环境下学习,称之为监督学习(supervised learning)或者叫有师学习(learning with a teacher),之前讨论的一些算法都是这类问题。举个例子,硬币分类问题,如图3-2所示,其中横轴标示硬币的大小,纵轴标示硬币聚集的堆。

图3-2 有监督的多类别分类问题
其中这几种类别的硬币已经被各种不同的颜色所标示好。
3.2.2 Unsupervised Learning
无监督学习。这是一种没有标示(就是没有输出y)的问题,就是不告诉你题目的正确答案让你自己去寻找,再以硬币分类为例进行阐述,如图3-3所示。
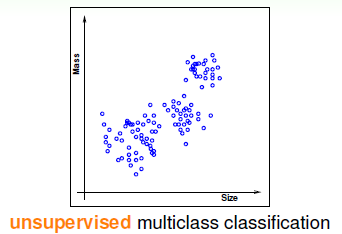
图3-3 无监督的多类别分类问题
这种类型的问题最常见的是聚类或者叫分群(clustering),从图中不难看出无标示的难度比有标示的难度增加不少,而且极有可能犯错,但是这种问题却拥有广泛的应用场景(毕竟标示需要花费大量人力物力),如将新闻按照不同的主题聚类,按用户的属性将用户聚成不同类型的用户群等等。
除了聚类之外还有其他的无监督学习,如密度评估(density estimation)和离群点检测(outlier detection)等等。
3.2.3 Semi-supervised Learning
半监督学习。是否能在监督式学习和无监督学习之间取一个中庸的方法呢?答案是可以的,就是半监督学习,它通过少量有标记的训练点和大量无标记的训练点达到学习的目的。还是以硬币为例,如图3-4所示。这种类型的例子也有很多,比如图像的识别,很多情况下我们不可能把每张图片都做上标记(因为做这种标记需要耗费大量的人力物力,是一种昂贵的行为),此时,使用半监督学习是一种不错的选择。
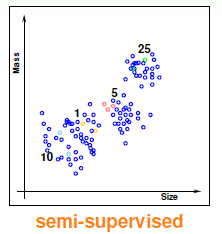
图3-4 半监督学习
3.2.4 Reinforcement Learning
强化学习。前面三个是机器学习中最传统的三种方式,除此之外,还有一种方式是通过对一个行为作出奖励或者惩罚,以此获得的输出,进而进行学习,这种学习方式称之为强化学习。
一般可以表示为
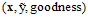
,其中向量
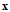
还是为输入向量,
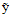
表示一种输出,注意
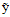
并不一定是最佳输出,最后一项是对输出做出的评判。比如一个广告系统可以写成如下形式
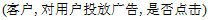
。
3.3 Learning with Different Protocol
不同方式获取数据。对此节的内容进行简单阐述,在不同的协议中可以将机器学习分为三大类:
批量(batch)学习就是将很多数据一次性的给算法进行学习,最常见的方式;
在线(online)学习就是一点一点将数据传输进去,如PLA和增强学习都适用于这种形式;
主动(active)学习是主动提出问题让算法解决,可以节省大量的训练和标记消耗。
3.4 Learning with Different Input Space
不同的输入空间。输入又可以称之为特征(features),其主要分为三种:
具体特征(Concrete Features),具体特征最大特点就是便于机器学习的处理,也是基础篇中主要讨论的情形。这种情况是人类或者机器通过一定的方式提取获得的,具有实用性。
原始特征(Raw Features),如图片的像素等等,是最为常见到的资料,但是需要经过处理,转换成具体特征,才容易使用,实用性不太大。
抽象特征(Abstract Features),如一些ID之类的看似无意义的数据,这就更需要特征的转换、提取等工作(相对于原始特征而言),几乎没有实用性。

相关文章推荐
- 机器学习基石 作业4 带Regularizer和Cross Validation的线性回归分类器
- [MOOC学习笔记]机器学习基石 Lecture01 The Learning Problem
- [MOOC学习笔记]机器学习基石 Lecture01 The Learning Problem
- 机器学习基石笔记 Lecture 2: Learning to Answer Yes/No
- 机器学习基石笔记9——Linear Regression
- 台大-林轩田老师-机器学习基石学习笔记13
- 机器学习中的噪音(机器学习基石)
- 1. 机器学习基石-When can Machine Learn? - The Learning Problem
- 机器学习基石第八讲笔记
- 听课笔记(第二讲): Perceptron-感知机 (台湾国立大学机器学习基石)
- 机器学习基石---Linear Regression
- 机器学习基石笔记1——在何时可以使用机器学习(1)
- 13. 机器学习基石-How can Machine Learn Better? - Validation
- 机器学习基石-02-1-yes/no
- 机器学习基石-07-2-VC Dimension of Perceptrons
- 机器学习基石第五讲:training versus testing
- 机器学习基石第三讲笔记
- 机器学习基石 - Training versus Testing
- 台大林轩田·机器学习基石记要
- 机器学习基石-Hazard of Overfitting