强化学习——从最简单的开始入手
2018-02-05 12:18
239 查看
1. 什么是强化学习(Refinancement Learning)
强化学习是机器学习大家族中的一类,使用强化学习能够让机器学者如何在环境中拿到高分,表现出优秀的成绩。而这些成绩的背后是算法不断的试错,不断的学习经验,累计经验的结果。
强化学习是一类算法,是让计算机实现从一开始什么都不懂,脑袋里什么都没有,通过不断地尝试,从错误中学习,最后找到规律,学会了达到目的的方法。这就是一个完整的强化学习过程。实际中的强化学习例子有很多,比如近期有名的Alpha go,让计算机自己学习着玩经典游戏Atari,这些都是让计算机在不断的尝试中更新自己的行为准则,从而一步步学会如何下好围棋,如何操控游戏得到高分。既然要让计算机自己学习,那计算机通过什么来学习呢?
原来计算机也需要一位虚拟的老师,这个老师比较吝啬,他不会告诉你以什么形式学习这些现有的资源,或者说怎么样只从分数中学习到我应该怎么做决定呢?很简单,我只需要记住那些高分,低分对应的行为,下次用同样的行为拿高分,并避免低分的行为。
比如老师会根据我的开心程度来打分,我开心时,可以得到高分,我不开心时得到低分,有了这些被打分的经验, 我就能判断为了拿到高分, 我应该选择一张开心的脸, 避免选到伤心的脸. 这也是强化学习的核心思想. 可以看出在强化学习中, 一种行为的分数是十分重要的. 所以强化学习具有分数导向性. 我们换一个角度来思考.这种分数导向性好比我们在监督学习中的正确标签.。
对比监督学习

我们知道监督学习, 是已经有了数据和数据对应的正确标签, 比如这样. 监督学习就能学习出那些脸对应哪种标签. 不过强化学习还要更进一步, 一开始它并没有数据和标签.
他要通过一次次在环境中的尝试, 获取这些数据和标签, 然后再学习通过哪些数据能够对应哪些标签, 通过学习到的这些规律, 竟可能地选择带来高分的行为 (比如这里的开心脸). 这也就证明了在强化学习中, 分数标签就是他的老师, 他和监督学习中的老师也差不多.、
强化学习算法种类:
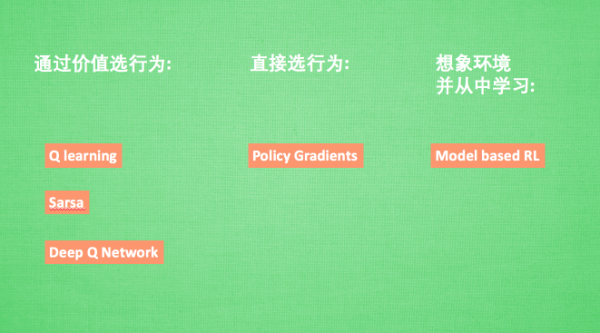
强化学习是一个大家族, 他包含了很多种算法, 我们也会一一提到之中一些比较有名的算法, 比如有通过行为的价值来选取特定行为的方法, 包括使用表格学习的 q learning, sarsa, 使用神经网络学习的 deep q network, 还有直接输出行为的 policy gradients, 又或者了解所处的环境, 想象出一个虚拟的环境并从虚拟的环境中学习 等等.
下面通过一个例子来阐述强化学习实现的过程:
我们用 Q-learning 的方法实现一个小例子, 例子的环境是一个一维世界, 在世界的右边有宝藏, 探索者只要得到宝藏尝到了甜头, 然后以后就记住了得到宝藏的方法, 这就是他用强化学习所学习到的行为.
如果在某个地点
Q-learning 是一种记录行为值 (Q value) 的方法, 每种在一定状态的行为都会有一个值
1. 预设值,主要是模型需要手动设置的一些参数。
2. Q表,Q-learning主要是通过更新Q表中的value。
对于 Q learning, 我们必须将所有的 Q values (行为值) 放在
3. 定义动作
接着定义探索者是如何挑选行为的. 这是我们引入
4. 环境反馈 S_, R
做出行为后, 环境也要给我们的行为一个反馈, 反馈出下个 state (S_) 和 在上个 state (S) 做出 action (A) 所得到的 reward (R). 这里定义的规则就是, 只有当
[b]环境更新(只针对对本例中的环境)[/b]
核心:强化学习主循环

最后,整合本例中的所有代码
强化学习是机器学习大家族中的一类,使用强化学习能够让机器学者如何在环境中拿到高分,表现出优秀的成绩。而这些成绩的背后是算法不断的试错,不断的学习经验,累计经验的结果。
强化学习是一类算法,是让计算机实现从一开始什么都不懂,脑袋里什么都没有,通过不断地尝试,从错误中学习,最后找到规律,学会了达到目的的方法。这就是一个完整的强化学习过程。实际中的强化学习例子有很多,比如近期有名的Alpha go,让计算机自己学习着玩经典游戏Atari,这些都是让计算机在不断的尝试中更新自己的行为准则,从而一步步学会如何下好围棋,如何操控游戏得到高分。既然要让计算机自己学习,那计算机通过什么来学习呢?
原来计算机也需要一位虚拟的老师,这个老师比较吝啬,他不会告诉你以什么形式学习这些现有的资源,或者说怎么样只从分数中学习到我应该怎么做决定呢?很简单,我只需要记住那些高分,低分对应的行为,下次用同样的行为拿高分,并避免低分的行为。
比如老师会根据我的开心程度来打分,我开心时,可以得到高分,我不开心时得到低分,有了这些被打分的经验, 我就能判断为了拿到高分, 我应该选择一张开心的脸, 避免选到伤心的脸. 这也是强化学习的核心思想. 可以看出在强化学习中, 一种行为的分数是十分重要的. 所以强化学习具有分数导向性. 我们换一个角度来思考.这种分数导向性好比我们在监督学习中的正确标签.。
对比监督学习
我们知道监督学习, 是已经有了数据和数据对应的正确标签, 比如这样. 监督学习就能学习出那些脸对应哪种标签. 不过强化学习还要更进一步, 一开始它并没有数据和标签.
他要通过一次次在环境中的尝试, 获取这些数据和标签, 然后再学习通过哪些数据能够对应哪些标签, 通过学习到的这些规律, 竟可能地选择带来高分的行为 (比如这里的开心脸). 这也就证明了在强化学习中, 分数标签就是他的老师, 他和监督学习中的老师也差不多.、
强化学习算法种类:
强化学习是一个大家族, 他包含了很多种算法, 我们也会一一提到之中一些比较有名的算法, 比如有通过行为的价值来选取特定行为的方法, 包括使用表格学习的 q learning, sarsa, 使用神经网络学习的 deep q network, 还有直接输出行为的 policy gradients, 又或者了解所处的环境, 想象出一个虚拟的环境并从虚拟的环境中学习 等等.
下面通过一个例子来阐述强化学习实现的过程:
我们用 Q-learning 的方法实现一个小例子, 例子的环境是一个一维世界, 在世界的右边有宝藏, 探索者只要得到宝藏尝到了甜头, 然后以后就记住了得到宝藏的方法, 这就是他用强化学习所学习到的行为.
如果在某个地点
s1, 探索者计算了他能有的两个行为,
a1/a2=left/right, 计算结果是
Q(s1, a1) > Q(s1, a2), 那么探索者就会选择
left这个行为. 这就是 Q learning 的行为选择简单规则.
-o---T # T 就是宝藏的位置, o 是探索者的位置
Q-learning 是一种记录行为值 (Q value) 的方法, 每种在一定状态的行为都会有一个值
Q(s, a), 就是说 行为
a在
s状态的值是
Q(s, a).
s在上面的探索者游戏中, 就是
o所在的地点了. 而每一个地点探索者都能做出两个行为
left/right, 这就是探索者的所有可行的
a啦. 接下来描述RL的基本步骤。
1. 预设值,主要是模型需要手动设置的一些参数。
N_STATES = 6 # 状态数s对应的集合 ACTIONS = ['left', 'right'] # 每个状态下的所有行为的集合 EPSILON = 0.9 # 贪婪度 greedy ALPHA = 0.1 # 学习率 GAMMA = 0.9 # 奖励递减值 MAX_EPISODES = 13 # 最大回合数 FRESH_TIME = 0.3 # 移动间隔时间(非必要参数,只是着这个例子中独有的参数)
2. Q表,Q-learning主要是通过更新Q表中的value。
对于 Q learning, 我们必须将所有的 Q values (行为值) 放在
q_table中, 更新
q_table也是在更新他的行为准则.
q_table的 index 是所有对应的
state(探索者位置), columns 是对应的
action(探索者行为).
def build_q_table(n_states, actions): table = pd.DataFrame( np.zeros((n_states, len(actions))), # q_table 全 0 初始 columns=actions, # columns 对应的是行为名称 ) return table # q_table: """ left right 0 0.0 0.0 1 0.0 0.0 2 0.0 0.0 3 0.0 0.0 4 0.0 0.0 5 0.0 0.0 """
3. 定义动作
接着定义探索者是如何挑选行为的. 这是我们引入
epsilon greedy的概念. 因为在初始阶段, 随机的探索环境, 往往比固定的行为模式要好, 所以这也是累积经验的阶段, 我们希望探索者不会那么贪婪(greedy). 所以
EPSILON就是用来控制贪婪程度的值.
EPSILON可以随着探索时间不断提升(越来越贪婪), 不过在这个例子中, 我们就固定成
EPSILON = 0.9, 90% 的时间是选择最优策略, 10% 的时间来探索.
# 在某个 state 地点, 选择行为 def choose_action(state, q_table): state_actions = q_table.iloc[state, :] # 选出这个 state 的所有 action 值 if (np.random.uniform() > EPSILON) or (state_actions.all() == 0): # 非贪婪 or 或者这个 state 还没有探索过 action_name = np.random.choice(ACTIONS) else: action_name = state_actions.argmax() # 贪婪模式 return action_name
4. 环境反馈 S_, R
做出行为后, 环境也要给我们的行为一个反馈, 反馈出下个 state (S_) 和 在上个 state (S) 做出 action (A) 所得到的 reward (R). 这里定义的规则就是, 只有当
o移动到了
T, 探索者才会得到唯一的一个奖励, 奖励值 R=1, 其他情况都没有奖励.
def get_env_feedback(S, A): # This is how agent will interact with the environment if A == 'right': # move right if S == N_STATES - 2: # terminate S_ = 'terminal' R = 1 else: S_ = S + 1 R = 0 else: # move left R = 0 if S == 0: S_ = S # reach the wall else: S_ = S - 1 return S_, R
[b]环境更新(只针对对本例中的环境)[/b]
def update_env(S, episode, step_counter):
# This is how environment be updated
env_list = ['-']*(N_STATES-1) + ['T'] # '---------T' our environment
if S == 'terminal':
interaction = 'Episode %s: total_steps = %s' % (episode+1, step_counter)
print('\r{}'.format(interaction), end='')
time.sleep(2)
print('\r ', end='')
else:
env_list[S] = 'o'
interaction = ''.join(env_list)
print('\r{}'.format(interaction), end='')
time.sleep(FRESH_TIME)核心:强化学习主循环
def rl(): q_table = build_q_table(N_STATES, ACTIONS) # 初始 q table for episode in range(MAX_EPISODES): # 回合 step_counter = 0 S = 0 # 回合初始位置 is_terminated = False # 是否回合结束 update_env(S, episode, step_counter) # 环境更新 while not is_terminated: A = choose_action(S, q_table) # 选行为 S_, R = get_env_feedback(S, A) # 实施行为并得到环境的反馈 q_predict = q_table.loc[S, A] # 估算的(状态-行为)值 if S_ != 'terminal': q_target = R + GAMMA * q_table.iloc[S_, :].max() # 实际的(状态-行为)值 (回合没结束) else: q_target = R # 实际的(状态-行为)值 (回合结束) is_terminated = True # terminate this episode q_table.loc[S, A] += ALPHA * (q_target - q_predict) # q_table 更新 S = S_ # 探索者移动到下一个 state update_env(S, episode, step_counter+1) # 环境更新 step_counter += 1 return q_table
Q-learning算法
1 设置gamma相关系数,以及奖励矩阵R
2 将Q矩阵初始化为全0
3 For each episode:
设置随机的初使状态
Do While 当没有到达目标时
选择一个最大可能性的action(action的选择用一个算法来做,后面再讲)
根据这个action到达下一个状态
根据计算公式:Q(state, action) := Q(state, action)+Gamma *{R(state, action) + Max[Q(next state, all actions)]-Q(state, action)}计算这个状态Q的值 设置当前状态为所到达的状态 End Do End For
最后,整合本例中的所有代码
# -*- coding: utf-8 -*-
"""
Created on Fri Sep 15 17:59:06 2017
@author:
"""
import numpy as np
import pandas as pd
import time
np.random.seed(2) # reproducible
N_STATES = 10 # the length of the 1 dimensional world
ACTIONS = ['left', 'right'] # available actions
EPSILON = 0.9 # greedy police
ALPHA = 0.1 # learning rate
GAMMA = 0.9 # discount factor
MAX_EPISODES = 2 # maximum episodes
FRESH_TIME = 0.3 # fresh time for one move
def build_q_table(n_states, actions):
table = pd.DataFrame(
np.zeros((n_states, len(actions))), # q_table initial values
columns=actions, # actions's name
)
# print(table) # show table
return table
def choose_action(state, q_table):
# This is how to choose an action
state_actions = q_table.iloc[state, :]
if (np.random.uniform() > EPSILON) or ((state_actions == 0).all()): # act non-greedy or state-action have no value
action_name = np.random.choice(ACTIONS)
else: # act greedy
action_name = state_actions.idxmax() # replace argmax to idxmax as argmax means a different function in newer version of pandas
return action_name
def get_env_feedback(S, A): # This is how agent will interact with the environment if A == 'right': # move right if S == N_STATES - 2: # terminate S_ = 'terminal' R = 1 else: S_ = S + 1 R = 0 else: # move left R = 0 if S == 0: S_ = S # reach the wall else: S_ = S - 1 return S_, R
def update_env(S, episode, step_counter): # This is how environment be updated env_list = ['-']*(N_STATES-1) + ['T'] # '---------T' our environment if S == 'terminal': interaction = 'Episode %s: total_steps = %s' % (episode+1, step_counter) print('\r{}'.format(interaction), end='') time.sleep(2) print('\r ', end='') else: env_list[S] = 'o' interaction = ''.join(env_list) print('\r{}'.format(interaction), end='') time.sleep(FRESH_TIME)
def rl():
# main part of RL loop
q_table = build_q_table(N_STATES, ACTIONS)
for episode in range(MAX_EPISODES):
step_counter = 0
S = 0
is_terminated = False
update_env(S, episode, step_counter)
while not is_terminated:
A = choose_action(S, q_table)
S_, R = get_env_feedback(S, A) # take action & get next state and reward
q_predict = q_table.loc[S, A]
if S_ != 'terminal':
q_target = R + GAMMA * q_table.iloc[S_, :].max() # next state is not terminal
else:
q_target = R # next state is terminal
is_terminated = True # terminate this episode
q_table.loc[S, A] += ALPHA * (q_target - q_predict) # update
S = S_ # move to next state
update_env(S, episode, step_counter+1)
step_counter += 1
return q_table
if __name__ == "__main__":
q_table = rl()
print('\r\nQ-table:\n')
print(q_table)

相关文章推荐
- 学习O/RM,从最简单的例子开始...之二
- JavaScript学习笔记(二)——从简单开始学起
- 深入浅出学习Struts1框架:一个简单mvc模式代码示例开始
- JavaScript学习笔记(二)——从简单开始学起
- 深入浅出学习Struts框架(一):一个简单mvc模式代码示例开始
- 开始关于ruby的学习和研究,先简单介绍下ruby
- (原)spring学习笔记2.简单的开始
- JavaScript学习笔记(二)——从简单开始学起
- 今天开始学习信息安全以及如何简单的写一个网页
- 从最简单开始的正则学习
- Unity3D 学习从简单开始-AssetDatabase的使用
- 学习SpringMVC——从最简单的开始
- 深入浅出学习Struts1框架(一):一个简单mvc模式代码示例开始
- [原]spring学习笔记3.简单的开始2
- JavaScript学习笔记(二)——从简单开始学起
- 学习【设计模式】从简单开始----------------适配器模式
- C语言学习笔记(二)--从最简单的数据类型开始
- 强化学习与简单多臂老虎机问题
- JavaEE Spring 学习(快速的用myeclipse来创建Spring config.xml),从简单开始(一)
- 深入浅出学习Struts1框架(一):一个简单mvc模式代码示例开始