数学建模——统计回归模型
2018-02-02 13:09
471 查看
前言:看完数学建模的统计回归模型,更是感到了数学建模的“细腻”之处,对比与机器学习,如果说机器学习像是“打一场仗”,那数学建模更是像“做一场手术”,一个简单的回归问题也可以从中感觉到他“细腻”的美感
回归模型是利用统计分析方法建立的最常用的一个模型,下面将通过对软件得到的结果进行分析,进而改进我们的模型。
下面将用3个例子展示对回归模型的优化。
假设我们拿到的数据如下:
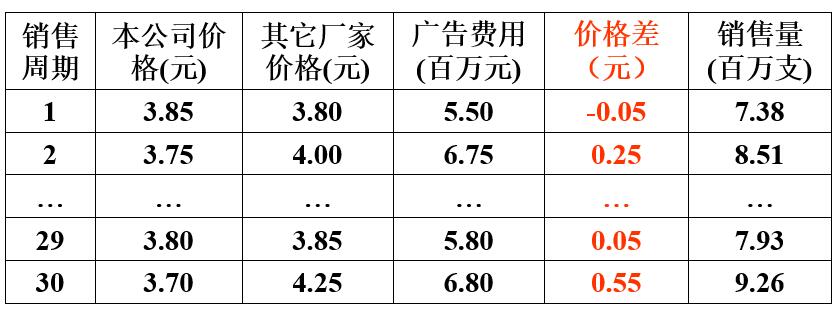
我们可以根据数据建立一个基本的模型:
y:公司牙膏销售量y:公司牙膏销售量
x1:价格差x1:价格差
x2:公司广告的费用x2:公司广告的费用
模型为:y=β0+β1x1+β2x2+β3x22+ϵy=β0+β1x1+β2x2+β3x22+ϵ
求解这个模型我们会得到下面的结果:
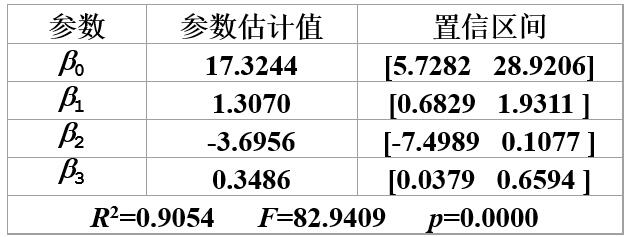
这说明y的90.54%可以由模型确定,x2对因变量y 的影响不太显著(因为β2的置信区间包括0点β2的置信区间包括0点)。
这些数据具体到公司的销售量到底意味着什么呢?
假设我们把控制价格差x1=0.2x1=0.2,投入广告费x2=650x2=650万,根据我们的模型可以求出y的值为8.2933(百万支),销售量的预测区间为[7.8230,8.7636]。
那么我们就有95%把握知道销售量在7.8320百万支以上。
y=β0+β1x1+β2x2+β3x22+β4x1x2+ϵy=β0+β1x1+β2x2+β3x22+β4x1x2+ϵ
从而求得的结果为:

这是后仍控制价格差x1为0.2,投入广告费用x2位6.5百万,我们得到的销售量为8.3272,可见比原来有所增加,预测区间变为[7.8953,8.7592],预测区间缩短。
下面是模型的比较:

那么加入交互项对模型有什么影响呢?
由上图可见加入交互项之后函数的变化更加明显,我们也可以从中得到一些启发,比如下图我们用了不同的价格差,对广告费(x2x2)用和销售量(y)进行比较:

由上图我们可以容易的总结出以下两条:
广告费用小于7左右的时候,价格优势的作用更加明显,价格低的销售量多。
当广告费大于6百万的时候,价格差小的,销售良随着广告的增加而增加的速率更快,所以此时应该增加广告来吸引眼球。
数据为46个开发人员的薪资

资历~ 从事专业工作的年数;管理~ 1=管理人员,0=非管理人员;教育~ 1=中学,2=大学,3=更高程度
建立基本模型
y 薪金,x1 资历(年)y 薪金,x1 资历(年)
x2=1 管理人员,x2=0 非管理人员x2=1 管理人员,x2=0 非管理人员
x3=1 中学,x3=0 其它x3=1 中学,x3=0 其它
x4=1 大学,x4=0 其它x4=1 大学,x4=0 其它
所以:
中学:x3=1,x4=0;大学:x3=0,x4=1;更高:x3=0,x4=0中学:x3=1,x4=0;大学:x3=0,x4=1;更高:x3=0,x4=0
回归模型为:
y=a0+a1x1+a2x2+a3x3+a4x4+ϵy=a0+a1x1+a2x2+a3x3+a4x4+ϵ
得到结果:

我们可以从得到结果分析:
资历增加1年薪金增长546
管理人员薪金多6883
中学程度薪金比更高的少2994
大学程度薪金比更高的多148
a4置信区间包含零点,解释不可靠!
残差与资历x1的关系

可见残差的波动较大
管理与教育的组合一共有6种:

比较残差和管理——教育组合的关系:

残差全为正,或全为负,管理—教育组合处理不当 ,应在模型中增加管理x2与教育x3, x4的交互项

去除异常的值
R,F有改进,所有回归系数置信区间都不含零点,模型完全可用
由此可以定制6种管理—教育组合人员的“基础”薪金(资历为0)

大学程度管理人员比更高程度管理人员的薪金高
大学程度非管理人员比更高程度非管理人员的薪金略低
总结一下
我们利用了残差分析法发现模型的缺陷,并且由前两个我们也可以发现,引入交互项往往能够改进模型
该地区连续20年的统计数据

首先建立基本的统计回归模型:
t−年份,yt−投资额,x1t−GNP,x2t−物价指数t−年份,yt−投资额,x1t−GNP,x2t−物价指数
模型为:yt=β0+β1x1t+β2x2t+ϵyt=β0+β1x1t+β2x2t+ϵ
根据数据得到的结果:

此模型不足的地方:
没有考虑时间序列数据的滞后性影响
可能忽视了随机误差存在自相关;如果存在自相关性,用此模型会有不良后果
et−1et−1表示上一个数据的残差
画出et−et−1et−et−1的散点图

由图可见,大部分点落在1,3象限,说明有正的自相关
所以直观的判断该模型有正的自相关
Q1:如何估计ρρ?
A1:D-W统计量
D-W统计量的计算

由D-W值的大小确定自相关性:

那如何知道dL和dU呢?这是可以查表的。

Q2:如何消除自相关性?
A2:广义分差法

我们通过上面可以求得DW值和dL以及dU,那我们计算ρ=1−DW/2ρ=1−DW/2就可以知道是否存在自相关性了
例如我们样本容量n=20,回归变量数目k=3,a=0.05 ,我们可以查到临界值dL=1.10, dU=1.54
ρ=1−DW/2=0.5623ρ=1−DW/2=0.5623,说明存在正的自相关性。
于是我们就可以得到新的模型:

我们可以根据这个模型我们可以再做一次自相关性的检测,发现新的模型已经没有自相关性了。
最后我们就可以根据新的自相关模型进行对下一年数据的预测了。
总结一下
在面对与时间有关的数据的时候,我们常常要检测模型的自相关性,消除了模型的自相关性之后才能建立更加精确的模型。
常常通过D-W方法检测模型的自相关性,用广义差分法消除模型的自相关性。
浓度等后一个量往往受前一个量的影响,在建立模型时往往要考虑前一个值得影响
回归模型是利用统计分析方法建立的最常用的一个模型,下面将通过对软件得到的结果进行分析,进而改进我们的模型。
下面将用3个例子展示对回归模型的优化。
1.牙膏的销售模型
问题的提出:假设一个公司需要预测不同价格和广告费用下的牙膏的销售量,我们需要怎么建立模型呢?假设我们拿到的数据如下:
我们可以根据数据建立一个基本的模型:
y:公司牙膏销售量y:公司牙膏销售量
x1:价格差x1:价格差
x2:公司广告的费用x2:公司广告的费用
模型为:y=β0+β1x1+β2x2+β3x22+ϵy=β0+β1x1+β2x2+β3x22+ϵ
求解这个模型我们会得到下面的结果:
这说明y的90.54%可以由模型确定,x2对因变量y 的影响不太显著(因为β2的置信区间包括0点β2的置信区间包括0点)。
这些数据具体到公司的销售量到底意味着什么呢?
假设我们把控制价格差x1=0.2x1=0.2,投入广告费x2=650x2=650万,根据我们的模型可以求出y的值为8.2933(百万支),销售量的预测区间为[7.8230,8.7636]。
那么我们就有95%把握知道销售量在7.8320百万支以上。
优化——加入交互项
刚才我们只考虑了每个因素单独的影响,现在我们考虑他们的影响有交互作用,即我们的模型变为:y=β0+β1x1+β2x2+β3x22+β4x1x2+ϵy=β0+β1x1+β2x2+β3x22+β4x1x2+ϵ
从而求得的结果为:
这是后仍控制价格差x1为0.2,投入广告费用x2位6.5百万,我们得到的销售量为8.3272,可见比原来有所增加,预测区间变为[7.8953,8.7592],预测区间缩短。
下面是模型的比较:
那么加入交互项对模型有什么影响呢?
由上图可见加入交互项之后函数的变化更加明显,我们也可以从中得到一些启发,比如下图我们用了不同的价格差,对广告费(x2x2)用和销售量(y)进行比较:
由上图我们可以容易的总结出以下两条:
广告费用小于7左右的时候,价格优势的作用更加明显,价格低的销售量多。
当广告费大于6百万的时候,价格差小的,销售良随着广告的增加而增加的速率更快,所以此时应该增加广告来吸引眼球。
2.软件开发人员的薪金
建立模型研究薪金与资历、管理责任、教育程度的关系,从而分析人事策略的合理性,作为新聘用人员薪金的参考数据为46个开发人员的薪资
资历~ 从事专业工作的年数;管理~ 1=管理人员,0=非管理人员;教育~ 1=中学,2=大学,3=更高程度
建立基本模型
y 薪金,x1 资历(年)y 薪金,x1 资历(年)
x2=1 管理人员,x2=0 非管理人员x2=1 管理人员,x2=0 非管理人员
x3=1 中学,x3=0 其它x3=1 中学,x3=0 其它
x4=1 大学,x4=0 其它x4=1 大学,x4=0 其它
所以:
中学:x3=1,x4=0;大学:x3=0,x4=1;更高:x3=0,x4=0中学:x3=1,x4=0;大学:x3=0,x4=1;更高:x3=0,x4=0
回归模型为:
y=a0+a1x1+a2x2+a3x3+a4x4+ϵy=a0+a1x1+a2x2+a3x3+a4x4+ϵ
得到结果:
我们可以从得到结果分析:
资历增加1年薪金增长546
管理人员薪金多6883
中学程度薪金比更高的少2994
大学程度薪金比更高的多148
a4置信区间包含零点,解释不可靠!
优化——残差分析
残差:e=y−y^e=y−y^残差与资历x1的关系
可见残差的波动较大
管理与教育的组合一共有6种:
比较残差和管理——教育组合的关系:
残差全为正,或全为负,管理—教育组合处理不当 ,应在模型中增加管理x2与教育x3, x4的交互项
改进的模型
y=a0+a1x1+a2x2+a3x3+a4x4+a5x2x3+a5x2x4+ϵy=a0+a1x1+a2x2+a3x3+a4x4+a5x2x3+a5x2x4+ϵ去除异常的值
R,F有改进,所有回归系数置信区间都不含零点,模型完全可用
由此可以定制6种管理—教育组合人员的“基础”薪金(资历为0)
大学程度管理人员比更高程度管理人员的薪金高
大学程度非管理人员比更高程度非管理人员的薪金略低
总结一下
我们利用了残差分析法发现模型的缺陷,并且由前两个我们也可以发现,引入交互项往往能够改进模型
3.投资额与国民生产总值和物价指数
根据对未来国民生产总值(GNP)及物价指数 (PI)的估计,预测未来投资额该地区连续20年的统计数据
首先建立基本的统计回归模型:
t−年份,yt−投资额,x1t−GNP,x2t−物价指数t−年份,yt−投资额,x1t−GNP,x2t−物价指数
模型为:yt=β0+β1x1t+β2x2t+ϵyt=β0+β1x1t+β2x2t+ϵ
根据数据得到的结果:
此模型不足的地方:
没有考虑时间序列数据的滞后性影响
可能忽视了随机误差存在自相关;如果存在自相关性,用此模型会有不良后果
模型自相关的诊断
定性诊断——残差分析
模型残差:et=yt−y^tet=yt−y^tet−1et−1表示上一个数据的残差
画出et−et−1et−et−1的散点图
由图可见,大部分点落在1,3象限,说明有正的自相关
所以直观的判断该模型有正的自相关
定量诊断——D-W检验
我们引入自相关回归系数ρρ,当ρ=0ρ=0表示无自相关性,ρ>0ρ>0表示存在正自相关性,ρ<0ρ<0表示存在负自相关性Q1:如何估计ρρ?
A1:D-W统计量
D-W统计量的计算
由D-W值的大小确定自相关性:
那如何知道dL和dU呢?这是可以查表的。
Q2:如何消除自相关性?
A2:广义分差法
我们通过上面可以求得DW值和dL以及dU,那我们计算ρ=1−DW/2ρ=1−DW/2就可以知道是否存在自相关性了
例如我们样本容量n=20,回归变量数目k=3,a=0.05 ,我们可以查到临界值dL=1.10, dU=1.54
ρ=1−DW/2=0.5623ρ=1−DW/2=0.5623,说明存在正的自相关性。
于是我们就可以得到新的模型:
我们可以根据这个模型我们可以再做一次自相关性的检测,发现新的模型已经没有自相关性了。
最后我们就可以根据新的自相关模型进行对下一年数据的预测了。
总结一下
在面对与时间有关的数据的时候,我们常常要检测模型的自相关性,消除了模型的自相关性之后才能建立更加精确的模型。
常常通过D-W方法检测模型的自相关性,用广义差分法消除模型的自相关性。
浓度等后一个量往往受前一个量的影响,在建立模型时往往要考虑前一个值得影响

相关文章推荐
- 数学建模--医疗保险欺诈的发现--模型:评价类的数学模型和多元统计模型--方法:”改进的”主成分分析,聚类分析,判别分析,相关分析
- 数学建模专栏 | 第七篇:MATLAB连续模型求解方法
- 背景建模方法模型统计
- §5 多对多线性回归数学模型
- 逻辑回归模型(一)——数学模型
- 统计学习-逻辑回归(LR)和最大熵模型
- 数学之美系列之一:统计语言模型
- BZOJ-1061 志愿者招募 线性规划转最小费用最大流+数学模型 建模
- SPSS统计分析过程包括描述性统计、均值比较、一般线性模型、相关分析、回归分析、对数线性模型、聚类分析、数据简化、生存分析、时间序列分析、多重响应等几大类
- 数学之美——统计语言模型
- 数学建模————统计问题之仿真(四)
- 数学之美 系列一 -- 统计语言模型
- <统计学习方法>5 逻辑斯蒂回归与最大熵模型
- 数学之美 系列一 -- 统计语言模型
- 逻辑回归模型(一)——数学模型
- BZOJ-1061 志愿者招募 线性规划转最小费用最大流+数学模型 建模
- SPSS统计分析过程包括描述性统计、均值比较、一般线性模型、相关分析、回归分析、对数线性模型、聚类分析、数据简化、生存分析、时间序列分析、多重响应等几大类
- 数学建模专栏 | 第八篇:MATLAB评价型模型求解方法
- 逻辑回归模型(一)——数学模型
- 数学之美 系列一 -- 统计语言模型