Coursera 机器学习(by Andrew Ng)课程学习笔记 Week 8(一)——无监督学习
2018-02-01 20:50
856 查看
此系列为 Coursera 网站机器学习课程个人学习笔记(仅供参考)
课程网址:https://www.coursera.org/learn/machine-learning
参考资料:http://blog.csdn.net/MajorDong100/article/details/51104784
前面提到的,对于无监督学习(Unsupervised Learning),我们常常面对的是未标记的数据。常见的算法是聚类(Clustering),还有很多其他算法,但我们暂时只讨论聚类算法。
假如下图是我们的数据点,没有标记。目标是将其分为两簇。
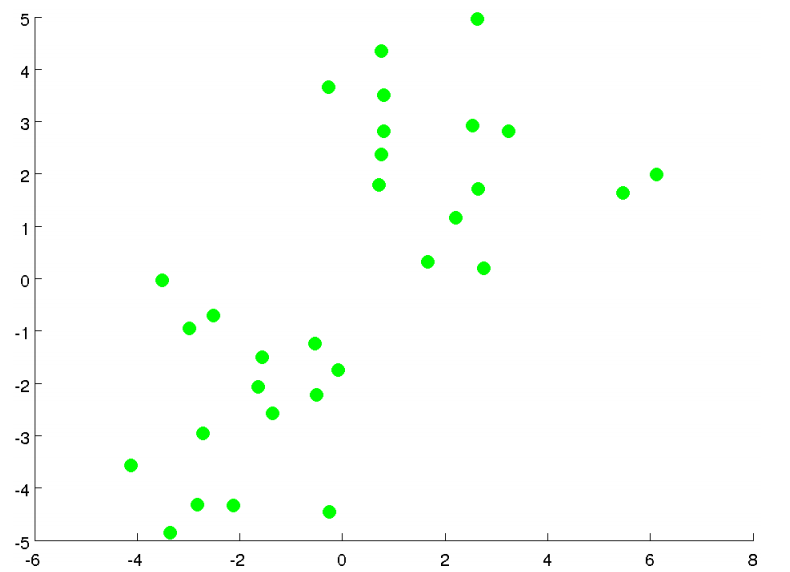
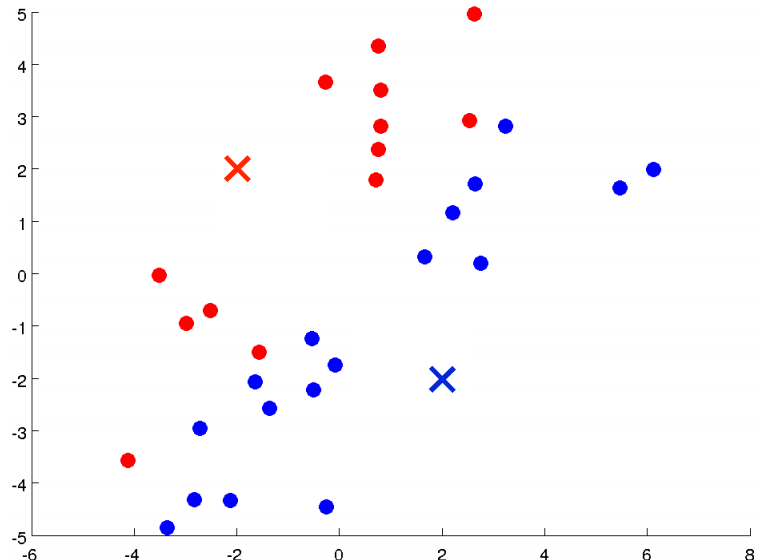
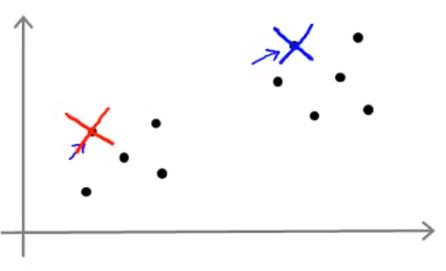
下面我们执行K均值算法。第一步我们随机选择两个点(如下图红色和蓝色的叉点),这两个点称为聚类中心(Clustering Centroid)。

K均值算法是一个迭代算法,它需要做两件事,一个是簇分配(Cluster Assignment),一个是聚类中心移动(Move Centroid)。下面我们来解释一下这两步的具体任务。在K均值算法的每一次循环中,第一步要进行簇分配,就是遍历所有的样本(绿色的点),然后看每一个点与两个聚类中心距离的哪个更近,就将其分配给对应的聚类中心。分配后如下图所示:
下一步就是要移动聚类中心,也就是将红色的叉点和蓝色的叉点移动到与它们颜色一样的点的均值处(找到所有红色的点,计算它们平均下来的位置,蓝色点也一样)。如下图:
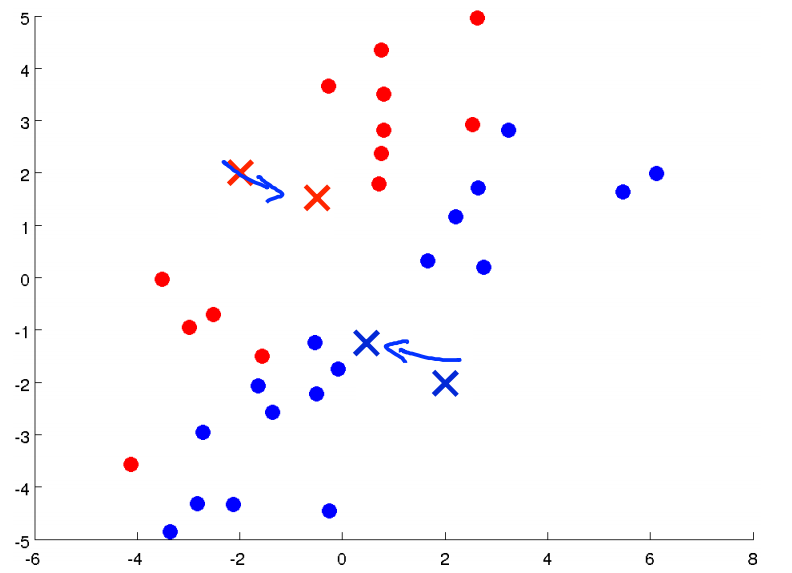
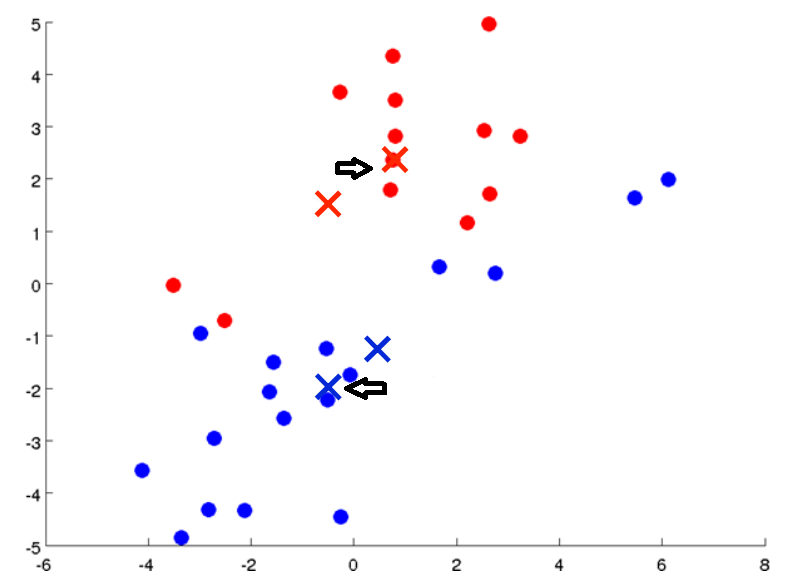
然后我们重新遍历所有的样本点,计算它们到两个聚类中心的距离,并把它们分配给两个聚类中心(染成不同的颜色)。我们可以看到有一些点的颜色变了
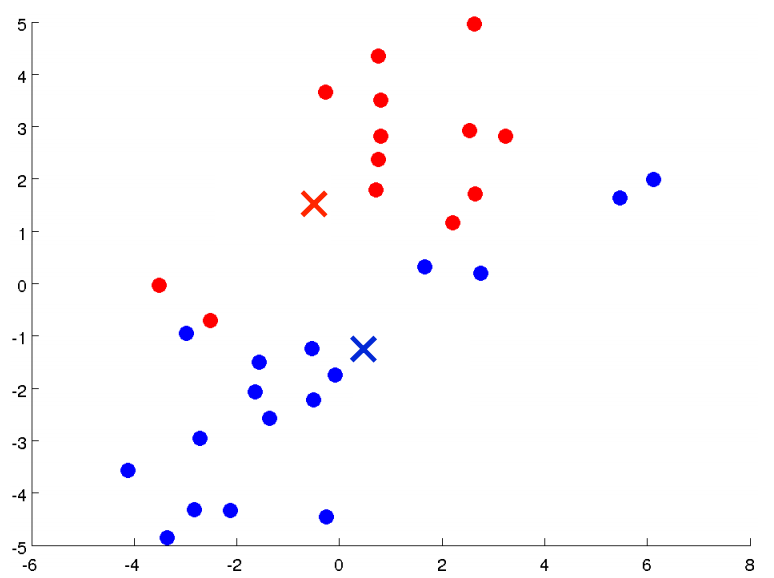
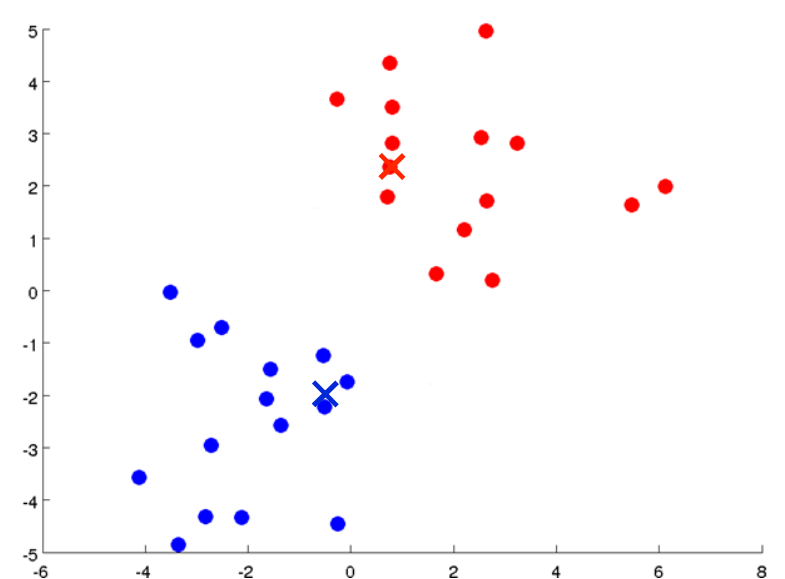
然后计算蓝色和红色点的均值,并移动聚类中心。
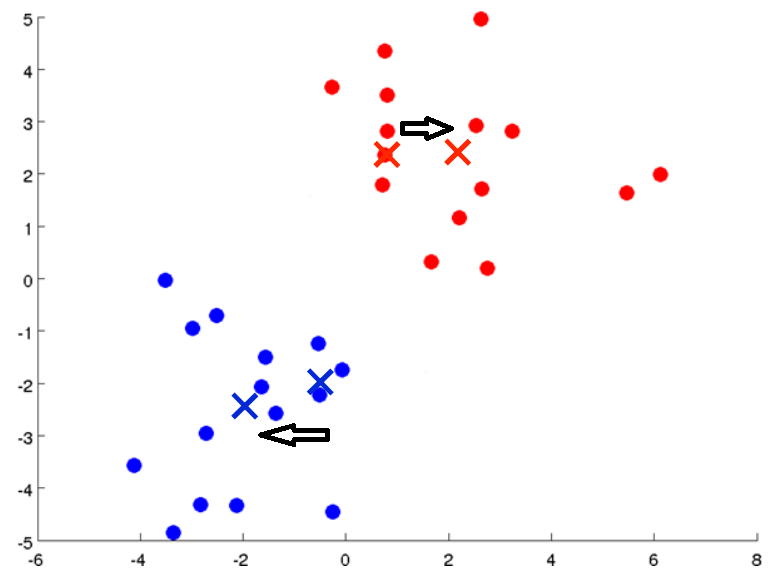
继续循环上述步骤,簇分配:
移动聚类中心:
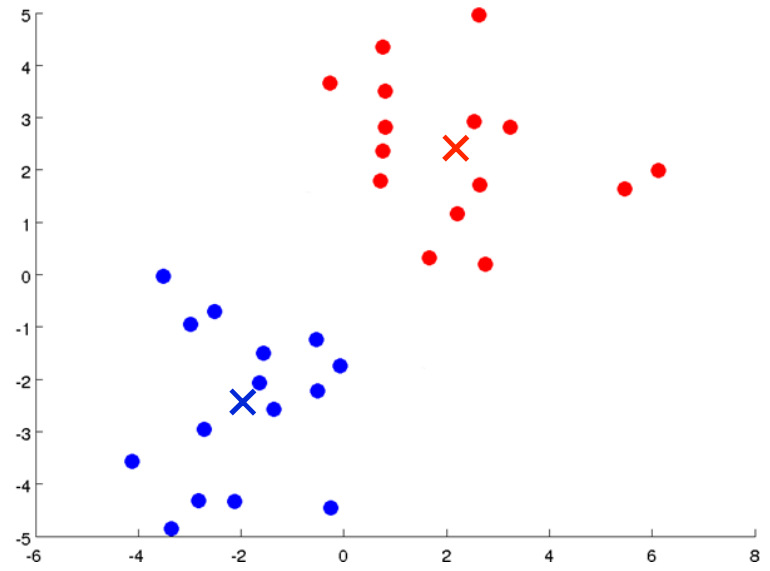
从这一步开始一直迭代下去,点的颜色不再改变,聚类中心也不再移动,我们可以说算法已经收敛了。最终我们将数据分为两簇(Clustering):
我们用更规范的语言来描述K均值算法:
K-Means Algorithm
Input:
- K(number of clusters)
- Training set{x(1),x(2),⋯,x(m)}
x(i)∈Rn(drop x0=1 convention)
Randomly initialize K cluster centroids μ1,μ2,⋯,μK∈Rn
Repeat {
for i=1 to m
c(i):=index(from 1 to K)of cluster centroid closest to x(i) (mink∥∥x(i)−uk∥∥2)
for k=1 to K
μk:=average(mean)of points assigned to cluster k
}
Repeat 循环中的第一个 for 循环其实就是簇分配,第二个 for 循环就是聚类中心移动。
如果一个聚类中心最终没有分配到点,一般情况下我们会移除这个点。不过实际情况下,这个问题不会经常出现。
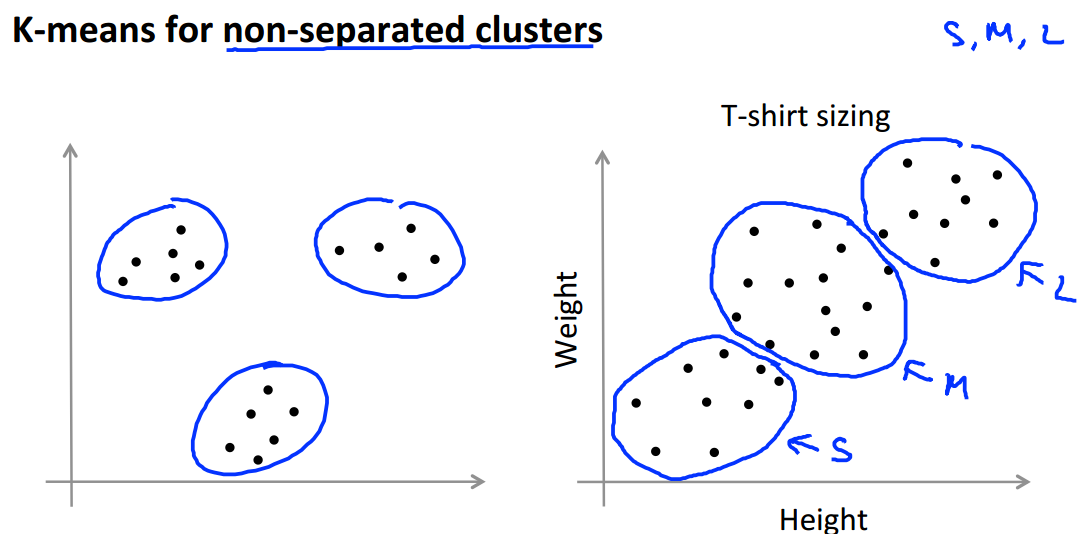
到目前为止,我们的K均值算法都是基于如下图左侧所示的数据,它们都有很好地隔离开来,但是事实上K均值算法经常会用于处理一些没有分割开的数据,如下图右侧所示。这是一个实际例子,我们想要设计S、M、L三个大小的衣服,搜集了一些人的身高体重的信息,利用K均值算法将数据分为三类,分别作为这三个大小衣服设计的参考。
c(i)→ 样本x(i) 当前被分配给的簇的索引号
μk→ 聚类中心 k (μk∈Rn)
μc(i)→ 样本x(i) 当前被分配给的簇的聚类中心
有了这些符号我们就可以写出K均值算法的优化目标了。
K均值算法的代价函数为:
[align=center]J(c(1),⋯,c(m),μ1,⋯,μK)=1m∑mi=1∥∥x(i)−μc(i)∥∥2[/align]
K均值算法的优化目标为:
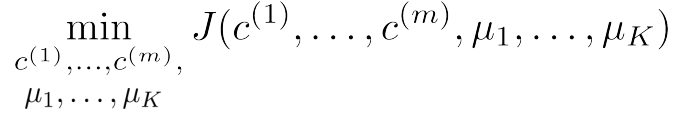
再来看之前的K均值算法步骤
Randomly initialize K cluster centroids μ1,μ2,⋯,μK∈Rn
Repeat {
for i=1 to m
c(i):=index(from 1 to K)of cluster centroid closest to x(i) (mink∥∥x(i)−uk∥∥2)
for k=1 to K
μk:=average(mean)of points assigned to cluster k
}
簇分配就是关于参数 c(1),⋯,c(m) 实现代价函数 J 的最小化,而 μ1,⋯,μK 保持不变; 移动聚类中心就是关于参数 μ1,⋯,μK 实现代价函数 J 的最小化, c(1),⋯,c(m) 保持不变。
Randomly initialize K cluster centroids μ1,μ2,⋯,μK∈Rn
下面我们介绍一种随机初始化的方法,它的效果要好于其他的方法。
如下图数据集:

首先,K 应该小于数据集的大小 m,例如 K=2,否则不符合常理。接下来我们随机选取 K 个训练样本,如下图,然后定义 K 个点与它们相等作为聚类中心。
刚刚我们选取的聚类中心看起来很好,但有时我们并不会那么幸运,例如下面这个例子:

根据初始化的聚类中心不同,我们最终会得到不同的结果。例如下图:
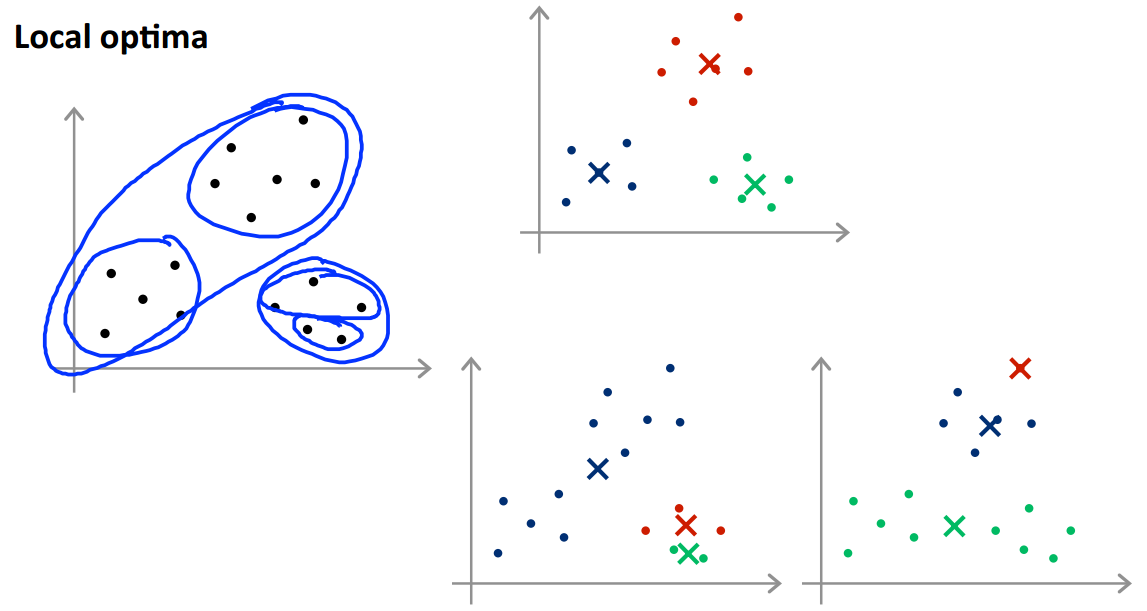
下面两种情况得到只是目标函数的局部最优解。为了解决这个问题,我们一般会尝试多次随机初始化,并运行多次K均值算法来保证我们得到一个足够好的结果。我们可以尝试 50∼1000 次。假如我们选择 100 次,如下图:

当你的 K 值很小,例如 2∼10,多次随机化能够保证你找到一个更好聚类,但是如果 K 值远远大于 10,多次随机化就不太可能有太大的影响,可能第一次的随机化就能给你带来相当好的结果。
当讨论选择聚类数目的方法时,人们可能会提及一个叫肘部法则(Elbow Method)的方法,我们画出代价函数关于聚类数目 K 的图像:
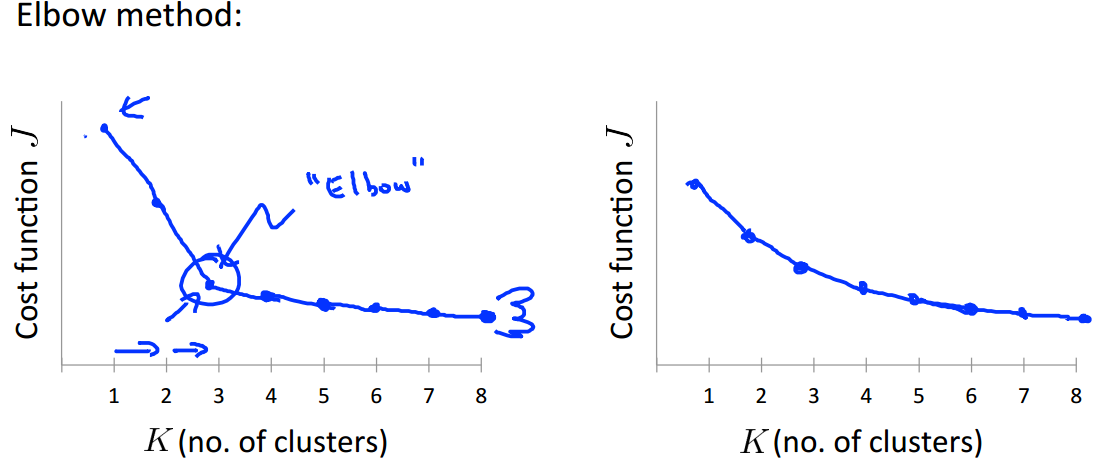
如左图,我们能看到图像在 K=3 处有一个明显的拐点,类似于“肘部”,我们可以选择聚类数目为 3。如果你得到一个这样的图,那么你可以明显选出合适的聚类数目。但是通常得到的图像可能如右图所示,肘部并不是那么清晰,看起来选择 3,4,5 都是可行的。这给我们的选择带来了一定的困难。
对于肘部法则,它是一个值得尝试的方法,但我们并不期待它在任何问题上都能有很好的表现。
如果聚类算法有后续目的,我们可以通过评估后面的工作来选择聚类数目。
附课后题

课程网址:https://www.coursera.org/learn/machine-learning
参考资料:http://blog.csdn.net/MajorDong100/article/details/51104784
前面提到的,对于无监督学习(Unsupervised Learning),我们常常面对的是未标记的数据。常见的算法是聚类(Clustering),还有很多其他算法,但我们暂时只讨论聚类算法。
一、K均值算法
下面我们介绍一个常用的聚类算法——K均值算法(K Means)。我们用图来说明。假如下图是我们的数据点,没有标记。目标是将其分为两簇。
下面我们执行K均值算法。第一步我们随机选择两个点(如下图红色和蓝色的叉点),这两个点称为聚类中心(Clustering Centroid)。
K均值算法是一个迭代算法,它需要做两件事,一个是簇分配(Cluster Assignment),一个是聚类中心移动(Move Centroid)。下面我们来解释一下这两步的具体任务。在K均值算法的每一次循环中,第一步要进行簇分配,就是遍历所有的样本(绿色的点),然后看每一个点与两个聚类中心距离的哪个更近,就将其分配给对应的聚类中心。分配后如下图所示:
下一步就是要移动聚类中心,也就是将红色的叉点和蓝色的叉点移动到与它们颜色一样的点的均值处(找到所有红色的点,计算它们平均下来的位置,蓝色点也一样)。如下图:
然后我们重新遍历所有的样本点,计算它们到两个聚类中心的距离,并把它们分配给两个聚类中心(染成不同的颜色)。我们可以看到有一些点的颜色变了
然后计算蓝色和红色点的均值,并移动聚类中心。
继续循环上述步骤,簇分配:
移动聚类中心:
从这一步开始一直迭代下去,点的颜色不再改变,聚类中心也不再移动,我们可以说算法已经收敛了。最终我们将数据分为两簇(Clustering):
我们用更规范的语言来描述K均值算法:
K-Means Algorithm
Input:
- K(number of clusters)
- Training set{x(1),x(2),⋯,x(m)}
x(i)∈Rn(drop x0=1 convention)
Randomly initialize K cluster centroids μ1,μ2,⋯,μK∈Rn
Repeat {
for i=1 to m
c(i):=index(from 1 to K)of cluster centroid closest to x(i) (mink∥∥x(i)−uk∥∥2)
for k=1 to K
μk:=average(mean)of points assigned to cluster k
}
Repeat 循环中的第一个 for 循环其实就是簇分配,第二个 for 循环就是聚类中心移动。
如果一个聚类中心最终没有分配到点,一般情况下我们会移除这个点。不过实际情况下,这个问题不会经常出现。
到目前为止,我们的K均值算法都是基于如下图左侧所示的数据,它们都有很好地隔离开来,但是事实上K均值算法经常会用于处理一些没有分割开的数据,如下图右侧所示。这是一个实际例子,我们想要设计S、M、L三个大小的衣服,搜集了一些人的身高体重的信息,利用K均值算法将数据分为三类,分别作为这三个大小衣服设计的参考。
二 K均值算法的优化目标
我们先总结一下几个符号:c(i)→ 样本x(i) 当前被分配给的簇的索引号
μk→ 聚类中心 k (μk∈Rn)
μc(i)→ 样本x(i) 当前被分配给的簇的聚类中心
有了这些符号我们就可以写出K均值算法的优化目标了。
K均值算法的代价函数为:
[align=center]J(c(1),⋯,c(m),μ1,⋯,μK)=1m∑mi=1∥∥x(i)−μc(i)∥∥2[/align]
K均值算法的优化目标为:
再来看之前的K均值算法步骤
Randomly initialize K cluster centroids μ1,μ2,⋯,μK∈Rn
Repeat {
for i=1 to m
c(i):=index(from 1 to K)of cluster centroid closest to x(i) (mink∥∥x(i)−uk∥∥2)
for k=1 to K
μk:=average(mean)of points assigned to cluster k
}
簇分配就是关于参数 c(1),⋯,c(m) 实现代价函数 J 的最小化,而 μ1,⋯,μK 保持不变; 移动聚类中心就是关于参数 μ1,⋯,μK 实现代价函数 J 的最小化, c(1),⋯,c(m) 保持不变。
三、随机初始化
我们来看K均值算法,对于如何初始化聚类中心这一步我们并没有讨论太多。Randomly initialize K cluster centroids μ1,μ2,⋯,μK∈Rn
下面我们介绍一种随机初始化的方法,它的效果要好于其他的方法。
如下图数据集:
首先,K 应该小于数据集的大小 m,例如 K=2,否则不符合常理。接下来我们随机选取 K 个训练样本,如下图,然后定义 K 个点与它们相等作为聚类中心。
刚刚我们选取的聚类中心看起来很好,但有时我们并不会那么幸运,例如下面这个例子:
根据初始化的聚类中心不同,我们最终会得到不同的结果。例如下图:
下面两种情况得到只是目标函数的局部最优解。为了解决这个问题,我们一般会尝试多次随机初始化,并运行多次K均值算法来保证我们得到一个足够好的结果。我们可以尝试 50∼1000 次。假如我们选择 100 次,如下图:
当你的 K 值很小,例如 2∼10,多次随机化能够保证你找到一个更好聚类,但是如果 K 值远远大于 10,多次随机化就不太可能有太大的影响,可能第一次的随机化就能给你带来相当好的结果。
四、聚类数目的选择
无监督式学习中数据没有标记,所以也就没有一个明确的答案。一个数据集分成几类比较合适是比较模糊的,目前比较常见的方法就是看可视化的图或聚类算法的输出结果。下图中的数据集可以分成2、3或者4类都是可以的。当讨论选择聚类数目的方法时,人们可能会提及一个叫肘部法则(Elbow Method)的方法,我们画出代价函数关于聚类数目 K 的图像:
如左图,我们能看到图像在 K=3 处有一个明显的拐点,类似于“肘部”,我们可以选择聚类数目为 3。如果你得到一个这样的图,那么你可以明显选出合适的聚类数目。但是通常得到的图像可能如右图所示,肘部并不是那么清晰,看起来选择 3,4,5 都是可行的。这给我们的选择带来了一定的困难。
对于肘部法则,它是一个值得尝试的方法,但我们并不期待它在任何问题上都能有很好的表现。
如果聚类算法有后续目的,我们可以通过评估后面的工作来选择聚类数目。
附课后题

相关文章推荐
- Coursera 机器学习(by Andrew Ng)课程学习笔记 Week 4——神经网络(一)
- Coursera 机器学习(by Andrew Ng)课程学习笔记 Week 8(二)——降维
- Coursera 机器学习(by Andrew Ng)课程学习笔记 Week 5——神经网络(二)
- Coursera 机器学习(by Andrew Ng)课程学习笔记 Week 3——逻辑回归、过拟合与正则化
- Coursera 机器学习(by Andrew Ng)课程学习笔记 Week 1——简单的线性回归模型和梯度下降
- Coursera 机器学习(by Andrew Ng)课程学习笔记 Week 6(一)—— 机器学习诊断、偏差与方差
- Coursera 机器学习(by Andrew Ng)课程学习笔记 Week 7——支持向量机
- Coursera 机器学习(by Andrew Ng)课程学习笔记 Week 9(二)——推荐系统作业
- Coursera 机器学习(by Andrew Ng)课程学习笔记 Week 6(二)——误差分析与数据集偏斜处理
- Andrew Ng机器学习笔记week8 无监督学习(聚类、PCA)
- COURSERA 机器学习课笔记(by Prof. Andrew Ng)学习笔记(一)
- 斯坦福大学公开课 :机器学习课程(Andrew Ng)——5、监督学习:Support Vector Machine,引
- 机器学习之&&Andrew Ng课程复习--- 学习笔记(第三课)
- 斯坦福大学公开课 :机器学习课程(Andrew Ng)——12、无监督学习:Factor Analysis
- Andrew NG 深度学习课程笔记:神经网络、有监督学习与深度学习
- 斯坦福大学公开课 :机器学习课程(Andrew Ng)——3、监督学习:Gaussian Discriminant Analysis (GDA)
- Coursera吴恩达机器学习课程 总结笔记及作业代码——第6周有关机器学习的小建议
- 课程笔记|吴恩达Coursera机器学习 Week1 笔记-机器学习基础
- 斯坦福大学公开课 :机器学习课程(Andrew Ng)——14、无监督学习:Independent Component Analysis(ICA)
- 机器学习——Andrew NG老师课程学习笔记