PLA算法(机器学习基石)
2018-01-28 22:24
267 查看
PLA算法的机制
故事起源于一个二元分类问题(比如说银行要不要给客户发信用卡的问题)我们的先决条件
1.我们有资料在手上(用户信息)
2.我们的资料有标签(有没有发信用卡)
3.假设我们的资料是线性可分的(可以被一个超平面所分割)
我们的假设
我们首先要给每一笔资料算出一个得分函数,由于资料是线性可分的所以我们有如下假设
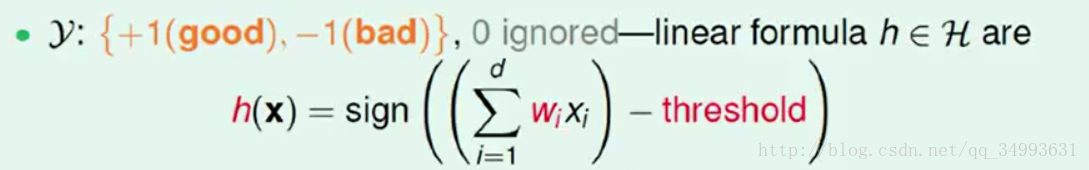
其中threshold为我们规定的门槛值,当得分为正sign()的结果为+1我们会给该客户发信用卡,否则不会。在此为了运算上的方便我们把门槛值归并到第0维中。
假设我们的得分函数是二维的,则h(x)的几何意义如下:
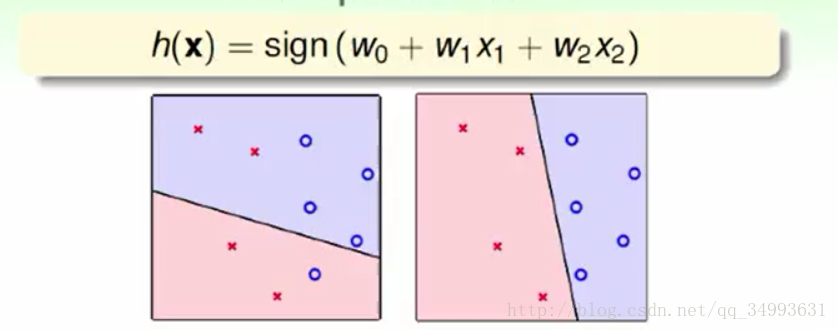
在这两幅图中每一个点代表一个用户(对应的资料),x与o代表没有发信用卡与发了信用卡,而图中的线(在高维空间中就是超平面)就是h(x)所代表的几何意义,它的作用是将平面分成两份。而进一步说h(x)的集合(假设集合)就是图中的无限多条线。我们的目的是利用学习算法找到一条能够完全正确的分割资料的直线。
PLA算法登场
基本描述:
1.首先我们有一条随机的直线在手上。
2.我们将遍历所有的资料,将所有的资料带入上面的假设。比较计算的结果与实际的标签是否对应。对于犯错误的点我们就要更新手上的直线。
3.更新直线让它离我们理想的直线越来越近。
在遇到犯错误的点是我们使用如下的公式来进行更新

它的底层逻辑基于向量的内积(两个向量的内积越大那么他们的相关性越强),如果预测y为+1实际为-1那么就将w与x的夹角往大调,如果预测y为-1实际为+1那么就将w与x的夹角往小调。归结起来就是上面的(2)式(其中y为实际的标签值)。就这样一个知错能改的算法在跑若干轮后就能够得到我们想要的直线。
PLA算法有效性的证明
我们的思路是证明我们每一轮的更新都会接近与我们理想中的那条线,具体来说就是求出他们的标准化的内积会越来越大。1.求内积
要求内积的两个向量如下图所示
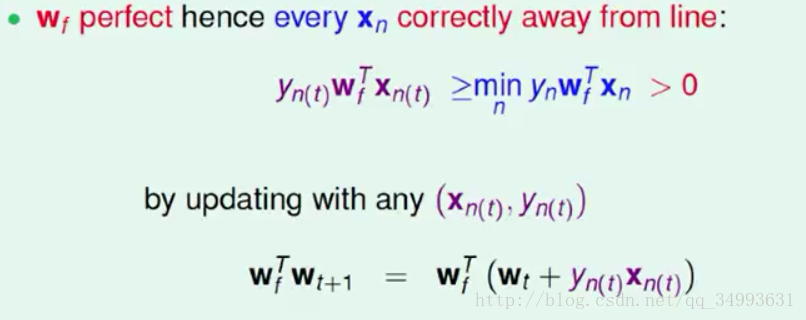
Wf为我们的理想直线Wt+1为我们下一轮更新后的直线,其中需要注意的是在直线附近的点是刚好被分开的一些点所以这些点x与对应的权重W的相关性较差所以内积较小。也就是离线最近的那个点它与对应权重W的内积就最小。
我们利用放缩法有如下的推导:

我们确实发现它们的内积在不断地增大,内积的增大原因有向量的模长在增大或者是夹角在变小。但是需要证明两个向量的相关性增大需要证明的是两个向量的夹角在变小,所以我们需要排除另一个模长的不确定性。
我们试着证明模长不在增大就好证明过程如下:
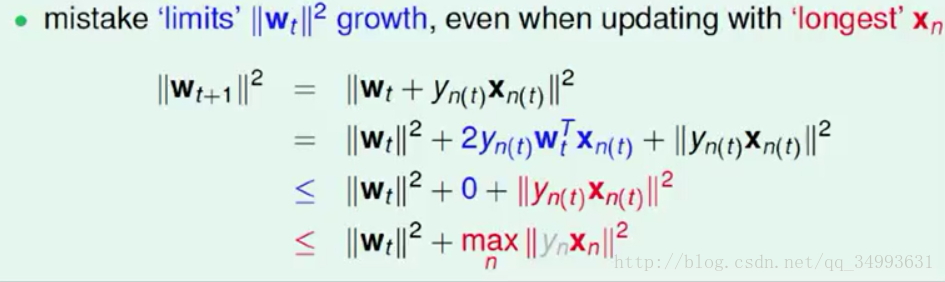
结果是Wt+1的模长在增大所以现在还不能证明夹角在变小。
我们综合两次的证明来看(结果标准化)

我们得到了它们的数量级是在增大,所以肯定的是我们的更新是有效的。
PLA算法的不足
我们在不知道数据的情况下(是否线性可分)PLA就不会停下来,这个时候我们会使用Pocket演算法来找到一根不错的直线。Pocket演算法的基本思想就是找到一根犯错误更小的直线。实务上我们一般会执行到一定的时间或者一定的步数就会停下来。结果是它是一条不错的线,但是可能不是一个最优解。最后特别感谢台湾大学林轩田老师!
附上主流的机器学习的教程
主流机器学习教程 密码:ab3w

相关文章推荐
- 机器学习基石PLA算法c++语言实现
- PLA算法总结——Percetron Learning Algorithm(机器学习基石2)
- 林轩田机器学习基石笔记2:PLA算法
- 台大机器学习课程——PLA演算法介绍、证明
- 林轩田机器学习基石——Guarantee of PLA
- 机器学习总结(lecture 2)算法:感知机学习算法 (PLA)
- 机器学习基石 2.3 Guarantee of PLA
- 台大林轩田机器学习课程笔记1----机器学习初探及PLA算法
- 機器學習基石 - Lesson2 - PLA算法初步
- 机器学习基石 作业1 实现PLA和Pocket算法
- 【机器学习】感知机学习算法(PLA)
- 机器学习基石学习笔记(1)-PLA
- 机器学习基石2-3 Guarantee of PLA
- 机器学习基石 2.2 Perceptron Learning Algorithm (PLA)
- 机器学习基石-02-2-PLA何时停下来?
- PLA(Perceptron Learning Algorithm)--机器学习基石笔记
- 机器学习基石—作业1(15-20题PLA编程)
- 机器学习基石第一讲:PLA
- 机器学习总结2_感知机算法(PLA)
- 机器学习基石---第二周PLA