NLP底层技术之句法分析
2018-01-28 16:54
706 查看
句法分析是自然语言处理(natural language processing, NLP)中的关键底层技术之一,其基本任务是确定句子的句法结构或者句子中词汇之间的依存关系。
句法分析分为句法结构分析(syntactic structure parsing)和依存关系分析(dependency parsing)。以获取整个句子的句法结构或者完全短语结构为目的的句法分析,被称为成分结构分析(constituent structure parsing)或者短语结构分析(phrase structure parsing);另外一种是以获取局部成分为目的的句法分析,被称为依存分析(dependency parsing)。
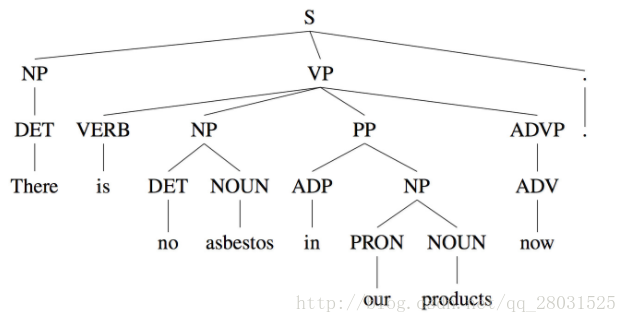
如以下取自WSJ语料库的句法结构树示例:
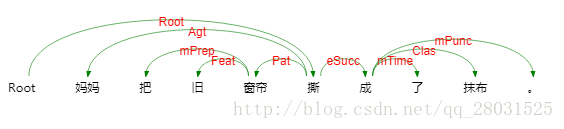
以及取自哈工大LTP的依存句法分析实例:
目前的句法分析已经从句法结构分析转向依存句法分析,一是因为通用数据集Treebank(Universal Dependencies treebanks)的发展,虽然该数据集的标注较为复杂,但是其标注结果可以用作多种任务(命名体识别或词性标注)且作为不同任务的评估数据,因而得到越来越多的应用,二是句法结构分析的语法集是由固定的语法集组成,较为固定和呆板;三是依存句法分析树标注简单且parser准确率高。
本文将对学习中遇到的PCFG、Lexical PCFG及主流的依存句法分析方法—Transition-based Parsing(基于贪心决策动作拼装句法树)做一整理。
目录:
PCFG
Lexical PCFG基于词典的PCFG
Transition-based parsing基于贪心决策动作的拼接句法树
参考资料
(The key idea in probabilistic context-free grammars(PCFG) is to extend our definition to give a probability over possible derivations.)
对最左派生规则的每一步都添加概率,这样整棵句法分析树的概率就是所有这些“独立”的概率的乘积。
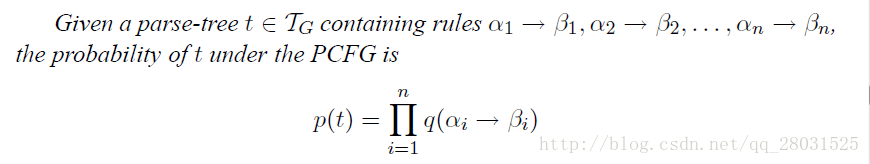
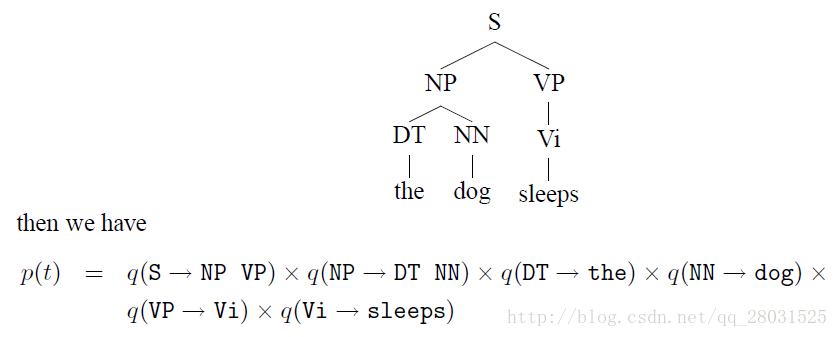
如下例:
为了方便计算,在PCFG中添加对rules的限制(Chomsky Normal Form):
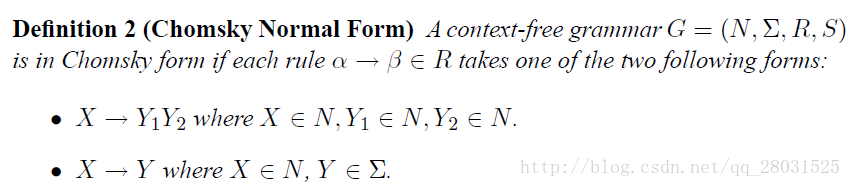
问题是如何寻找概率最大的句法分析树结构?
1. 暴力搜索(Brute-force method)
暴力搜索Brute-force method(根据PCFG的rules,暴力计算不同句法结构的概率,选择概率最高的句法分析树作为结论),缺陷在于随着句子的增长,计算量指数增长:

2. 动态规划(dynamic programming)CKY算法
π(i,j,X)π(i,j,X)is the highest score for any parse tree that dominates words , and has non-terminal X as its root.
因此整个句子的概率为π(1,n,S)=argmaxTG(s)π(1,n,S)=argmaxTG(s),其中TG(s)TG(s)是句子ss所有可能结构的集合。


结合上面π(i,j,X)π(i,j,X)的定义:
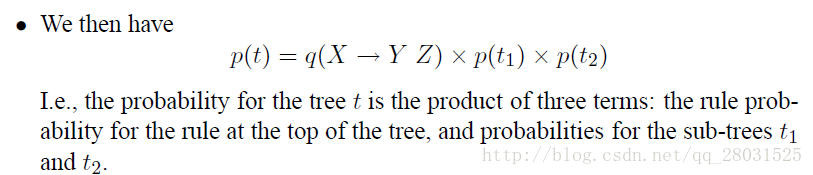
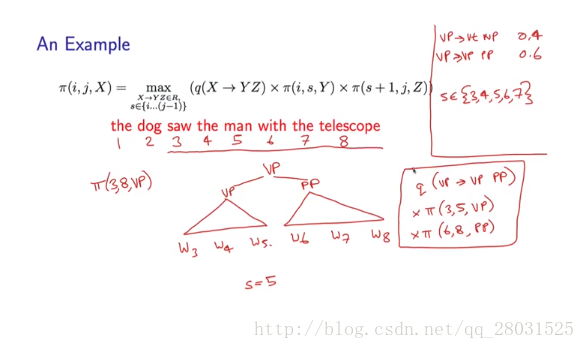
下面举例说明:

因此整个动态规划算法如下:

考虑算法时间复杂度:
i,j,s的选择都是o(n),对于X、Y和Z 和rules的选择都是o(|N|)。(n是句子中单词的数量,N是非终止符号的数量)

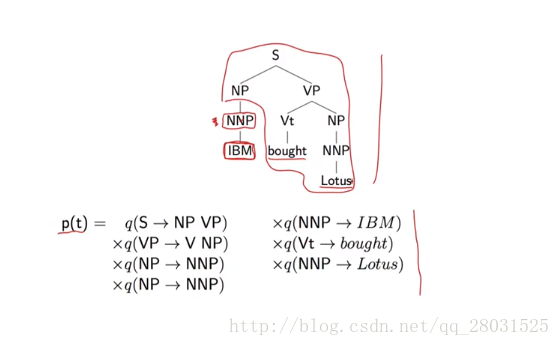
1、在PCFG中,词的选择具有很强的独立性假设,词的选择完全依赖于当前的词性(POS),而条件独立于与其他所有句法树上的结构(More formally, the choice of each word in the string is conditionally independent of the entire tree,once we have conditioned on the POS directly above the word),而这正是很多歧义问题的原因。下例中,’IBM’的选择仅仅与’NP’有关,而与其他树上的结构完全无关。
2、对结构偏好(structure preference)不敏感
对于存在歧义的两个句子,具有完全相同的树形结构,但是由于缺乏词汇的信息,进而缺少结构依赖的信息,使得最终不同树形结构计算的概率完全相同。
如下例中:同一句话,两个完全不同的句法分析结构,由于采用了相同的rules,因此概率计算最终也会相同。
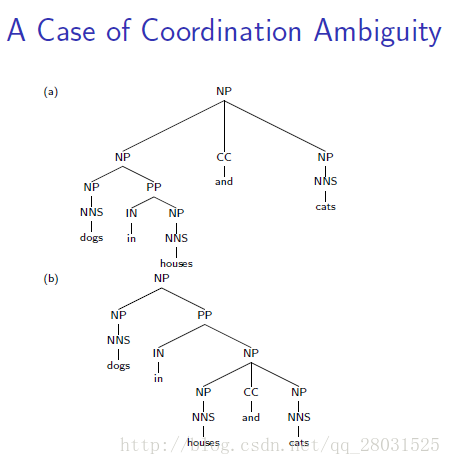
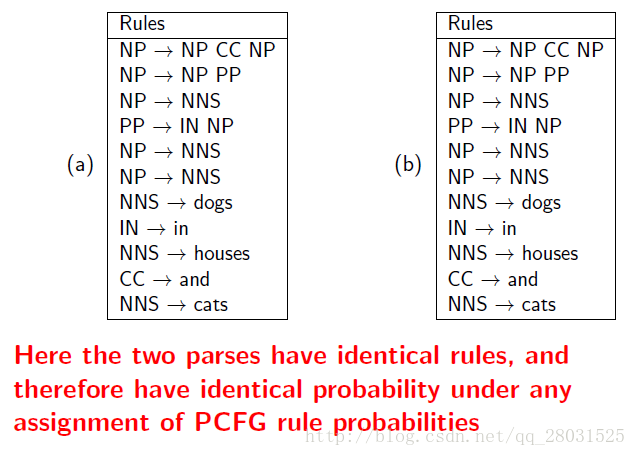
特别是介词短语(PP)的情况,在训练集中能统计到PP与名词短语(NP)或动词短语(VP)结合时不同的比例,但是PCFG完全忽略了这种偏好(preference)。
Lexicalized Context-Free
自下向上(bottom-up)的标记每条规则的head child,并添加到句法分析树上,每条规则的head child采用启发式自动选择。
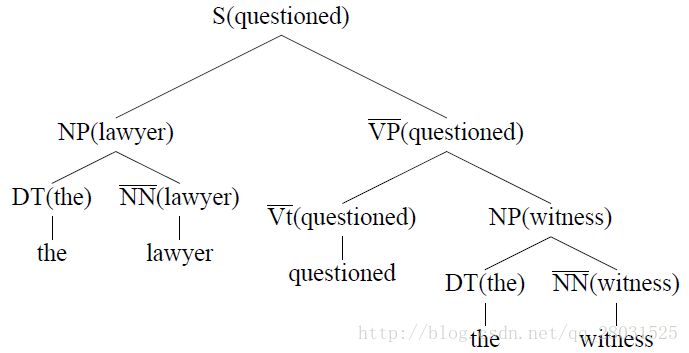

如下图在基于词典的PCFG中,规则概率如下:

基于词典的PCFG的参数估计
由于采用lexicalized PCFG之后,添加了词典信息,rules的数量和参数数量增多。因此需要考虑参数估计方法。

整个概率计算分为两部分,第一部分预测了规则(rules)的概率,第二部分预测了该规则下的词概率,每部分都利用平滑的估计方法进行计算。


对于Lexical PCFG,同样存在如何寻找概率最大的句法分析树结构的问题,而答案和PCFG相同,一样是采用动态规划(dynamic programming)的思想。
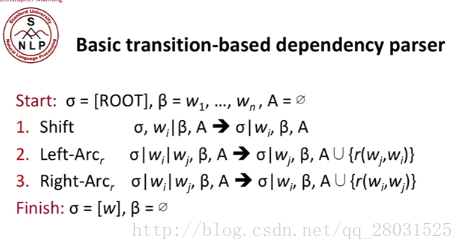
整个转移过程中的三种动作:Shift, Left-Arc, Right-Arc。一个stack,Buffer(整个原始的句子)。
在arc-standard system中,一次分析任务c=(s,b,A)c=(s,b,A)由一个栈s,一个队列b,一系列依存弧A构成。如果定义一个句子为单词构成的序列w1...wnw1...wn那么——
栈
栈s是用来储存系统已经处理过的句法子树的根节点的,初始状态下S=[ROOT]S=[ROOT]。另外,定义从栈顶数起的第ii个元素为sisi。那么栈顶元素就是s1s1,s1s1的下一个元素就是s2s2:

在一些中文论文中习惯使用焦点词这个表述,如果我们将栈横着放,亦即让先入栈的元素在左边,后入栈的元素在右边:

则称s2s2为左焦点词,s1s1为右焦点词。接下来的动作都是围绕着这两个焦点词展开的。
队列
初始状态下队列就是整个句子,且顺序不变b=[w1...wn]b=[w1...wn],队列的出口在左边。
依存弧
一条依存弧有两个信息:动作类型+依存关系名称I。l视依存句法语料库中使用了哪些依存关系label而定,在arc-standard系统中,一共有如下三种动作:
LEFT-ARC(l):添加一条s1 -> s2的依存边,名称为l,并且将s2s2从栈中删除。前提条件:|s|≥2|s|≥2。亦即建立右焦点词依存于左焦点词的依存关系,例如:

RIGHT-ARC(l):添加一条s2 -> s1的依存边,名称为l,并且将s1s1从栈中删除。前提条件:|s|≥2|s|≥2。亦即建立左焦点词依存于右焦点词的依存关系,例如:

SHIFT:将b1出队,压入栈。亦即不建立依存关系,只转移句法分析的焦点,即新的左焦点词是原来的右焦点词,依此类推。例如:

But How to check the next operation?(由于有三种动作,因此需要判断在下一步动作的顺序)。
Answer: 每一步动作都是由机器学习分类器得到的,如果我们得到treebank的句法分析树结构,我们就能得到序列转移或动作的顺序,最终变成一个有监督学习问题。(Since we have a treebank with parses of sentences,We can use these sentences to see which sequences of operations would give the correct parse of a sentences.)
只是在该算法提出之际,只是简单的用到了传统的机器学习方法。

当然由于在整个监督学习中,我们只是标识了转移的方向,因此可以看做3分类问题,但是实际过程中,当我们从stack中移出元素时,我们通常标识的dependency关系可以达到40种之多,而这就是分类的标签数量。
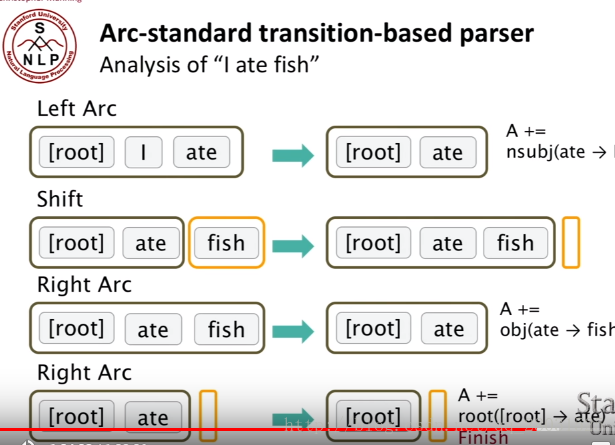
下面的一个重要的问题就是,How do we train the model,How do we choose the features?
一般而言,依存句法分析的可用特征:
1. Bilexical affinities(双词汇亲和)
2. Dependency distance(依存距离,一般倾向于距离近的)
3. Intervening material(标点符号两边的成分可能没有相互关系)
4. Valency of heads (词语配价,对于不同词性依附的词的数量或者依附方向)
传统的特征是栈和队列中的单词、词性或者依存标签等组合的特征,是一组很长的稀疏向量。
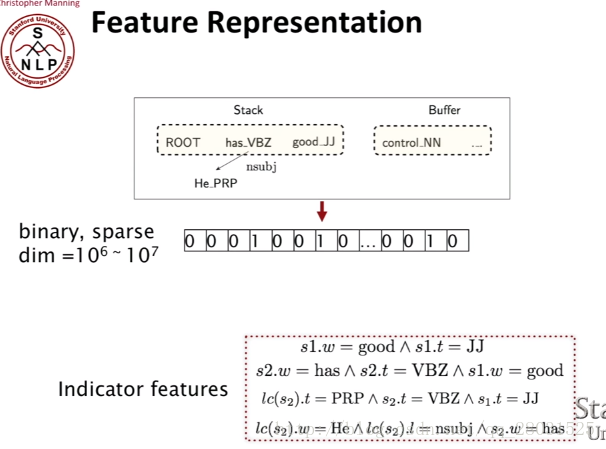
相比于使用大量的categorial (类别)特征,导致特征的sparse,使用神经网络可以使得特征更加dense,使用distributed representation of words减少特征的稀疏性。


Michael Collins《Natural Language Processing》
斯坦福大学cs224n《Natural Language Processing and Deep Learning》
http://www.hankcs.com/nlp/cs224n-dependency-parsing.html
http://www.hankcs.com/nlp/parsing/neural-network-based-dependency-parser.html/2#h2-6
论文《A Fast and Accurate Dependency Parser using Neural Networks》
句法分析分为句法结构分析(syntactic structure parsing)和依存关系分析(dependency parsing)。以获取整个句子的句法结构或者完全短语结构为目的的句法分析,被称为成分结构分析(constituent structure parsing)或者短语结构分析(phrase structure parsing);另外一种是以获取局部成分为目的的句法分析,被称为依存分析(dependency parsing)。
如以下取自WSJ语料库的句法结构树示例:
以及取自哈工大LTP的依存句法分析实例:
目前的句法分析已经从句法结构分析转向依存句法分析,一是因为通用数据集Treebank(Universal Dependencies treebanks)的发展,虽然该数据集的标注较为复杂,但是其标注结果可以用作多种任务(命名体识别或词性标注)且作为不同任务的评估数据,因而得到越来越多的应用,二是句法结构分析的语法集是由固定的语法集组成,较为固定和呆板;三是依存句法分析树标注简单且parser准确率高。
本文将对学习中遇到的PCFG、Lexical PCFG及主流的依存句法分析方法—Transition-based Parsing(基于贪心决策动作拼装句法树)做一整理。
目录:
PCFG
Lexical PCFG基于词典的PCFG
Transition-based parsing基于贪心决策动作的拼接句法树
参考资料
1.PCFG
结合上下文无关文法(CFG)中最左派生规则(left-most derivations)和不同的rules概率,计算所有可能的树结构概率,取最大值对应的树作为该句子的句法分析结果。(The key idea in probabilistic context-free grammars(PCFG) is to extend our definition to give a probability over possible derivations.)
对最左派生规则的每一步都添加概率,这样整棵句法分析树的概率就是所有这些“独立”的概率的乘积。
如下例:
为了方便计算,在PCFG中添加对rules的限制(Chomsky Normal Form):
问题是如何寻找概率最大的句法分析树结构?
1. 暴力搜索(Brute-force method)
暴力搜索Brute-force method(根据PCFG的rules,暴力计算不同句法结构的概率,选择概率最高的句法分析树作为结论),缺陷在于随着句子的增长,计算量指数增长:
2. 动态规划(dynamic programming)CKY算法
π(i,j,X)π(i,j,X)is the highest score for any parse tree that dominates words , and has non-terminal X as its root.
因此整个句子的概率为π(1,n,S)=argmaxTG(s)π(1,n,S)=argmaxTG(s),其中TG(s)TG(s)是句子ss所有可能结构的集合。
结合上面π(i,j,X)π(i,j,X)的定义:
下面举例说明:
因此整个动态规划算法如下:
考虑算法时间复杂度:
i,j,s的选择都是o(n),对于X、Y和Z 和rules的选择都是o(|N|)。(n是句子中单词的数量,N是非终止符号的数量)
2.Lexical PCFG(基于词典的PCFG)
首先考虑PCFG的缺陷:1、在PCFG中,词的选择具有很强的独立性假设,词的选择完全依赖于当前的词性(POS),而条件独立于与其他所有句法树上的结构(More formally, the choice of each word in the string is conditionally independent of the entire tree,once we have conditioned on the POS directly above the word),而这正是很多歧义问题的原因。下例中,’IBM’的选择仅仅与’NP’有关,而与其他树上的结构完全无关。
2、对结构偏好(structure preference)不敏感
对于存在歧义的两个句子,具有完全相同的树形结构,但是由于缺乏词汇的信息,进而缺少结构依赖的信息,使得最终不同树形结构计算的概率完全相同。
如下例中:同一句话,两个完全不同的句法分析结构,由于采用了相同的rules,因此概率计算最终也会相同。
特别是介词短语(PP)的情况,在训练集中能统计到PP与名词短语(NP)或动词短语(VP)结合时不同的比例,但是PCFG完全忽略了这种偏好(preference)。
Lexicalized Context-Free
自下向上(bottom-up)的标记每条规则的head child,并添加到句法分析树上,每条规则的head child采用启发式自动选择。
如下图在基于词典的PCFG中,规则概率如下:
基于词典的PCFG的参数估计
由于采用lexicalized PCFG之后,添加了词典信息,rules的数量和参数数量增多。因此需要考虑参数估计方法。
整个概率计算分为两部分,第一部分预测了规则(rules)的概率,第二部分预测了该规则下的词概率,每部分都利用平滑的估计方法进行计算。
对于Lexical PCFG,同样存在如何寻找概率最大的句法分析树结构的问题,而答案和PCFG相同,一样是采用动态规划(dynamic programming)的思想。
3.Transition-based parsing(基于贪心决策动作的拼接句法树)
首先介绍Arc-standard transition,动作体系的formal描述如下:整个转移过程中的三种动作:Shift, Left-Arc, Right-Arc。一个stack,Buffer(整个原始的句子)。
在arc-standard system中,一次分析任务c=(s,b,A)c=(s,b,A)由一个栈s,一个队列b,一系列依存弧A构成。如果定义一个句子为单词构成的序列w1...wnw1...wn那么——
栈
栈s是用来储存系统已经处理过的句法子树的根节点的,初始状态下S=[ROOT]S=[ROOT]。另外,定义从栈顶数起的第ii个元素为sisi。那么栈顶元素就是s1s1,s1s1的下一个元素就是s2s2:
在一些中文论文中习惯使用焦点词这个表述,如果我们将栈横着放,亦即让先入栈的元素在左边,后入栈的元素在右边:
则称s2s2为左焦点词,s1s1为右焦点词。接下来的动作都是围绕着这两个焦点词展开的。
队列
初始状态下队列就是整个句子,且顺序不变b=[w1...wn]b=[w1...wn],队列的出口在左边。
依存弧
一条依存弧有两个信息:动作类型+依存关系名称I。l视依存句法语料库中使用了哪些依存关系label而定,在arc-standard系统中,一共有如下三种动作:
LEFT-ARC(l):添加一条s1 -> s2的依存边,名称为l,并且将s2s2从栈中删除。前提条件:|s|≥2|s|≥2。亦即建立右焦点词依存于左焦点词的依存关系,例如:
RIGHT-ARC(l):添加一条s2 -> s1的依存边,名称为l,并且将s1s1从栈中删除。前提条件:|s|≥2|s|≥2。亦即建立左焦点词依存于右焦点词的依存关系,例如:
SHIFT:将b1出队,压入栈。亦即不建立依存关系,只转移句法分析的焦点,即新的左焦点词是原来的右焦点词,依此类推。例如:
But How to check the next operation?(由于有三种动作,因此需要判断在下一步动作的顺序)。
Answer: 每一步动作都是由机器学习分类器得到的,如果我们得到treebank的句法分析树结构,我们就能得到序列转移或动作的顺序,最终变成一个有监督学习问题。(Since we have a treebank with parses of sentences,We can use these sentences to see which sequences of operations would give the correct parse of a sentences.)
只是在该算法提出之际,只是简单的用到了传统的机器学习方法。
当然由于在整个监督学习中,我们只是标识了转移的方向,因此可以看做3分类问题,但是实际过程中,当我们从stack中移出元素时,我们通常标识的dependency关系可以达到40种之多,而这就是分类的标签数量。
下面的一个重要的问题就是,How do we train the model,How do we choose the features?
一般而言,依存句法分析的可用特征:
1. Bilexical affinities(双词汇亲和)
2. Dependency distance(依存距离,一般倾向于距离近的)
3. Intervening material(标点符号两边的成分可能没有相互关系)
4. Valency of heads (词语配价,对于不同词性依附的词的数量或者依附方向)
传统的特征是栈和队列中的单词、词性或者依存标签等组合的特征,是一组很长的稀疏向量。
相比于使用大量的categorial (类别)特征,导致特征的sparse,使用神经网络可以使得特征更加dense,使用distributed representation of words减少特征的稀疏性。
参考资料
宗成庆《统计自然语言处理》Michael Collins《Natural Language Processing》
斯坦福大学cs224n《Natural Language Processing and Deep Learning》
http://www.hankcs.com/nlp/cs224n-dependency-parsing.html
http://www.hankcs.com/nlp/parsing/neural-network-based-dependency-parser.html/2#h2-6
论文《A Fast and Accurate Dependency Parser using Neural Networks》

相关文章推荐
- 人工智能-语音交互-NLP自然语言(四) 句法分析/词向量
- 【技术分享】很详细的JS底层分析
- NLP汉语自然语言处理原理与实践 6 句法理论与自动分析
- NLP分析技术的三个层面
- Stanford NLP工具--句法分析
- NLP分析技术的三个层面
- NLP分析技术的三个层面
- NLP学习记录——句法分析
- 十二、教你如何利用强大的中文语言技术平台做依存句法和语义依存分析
- NLP分析技术的三个层面
- nlp 总结 分词,词义消歧,词性标注,命名体识别,依存句法分析,语义角色标注
- 【自然语言处理】句法分析 (syntactic parsing) 在 NLP 领域的应用是怎样的?
- 使用opennlp进行依存句法分析
- nlp-形式语言与自动机-ch08-句法分析
- NLP底层技术之语言模型
- spark streaming广告点击系统需求分析与技术架构
- 大数据分析技术研究报告(三-3)
- 股票技术分析要避免五大误区:
- HttpUrlConnection底层实现和关于java host绑定ip即时生效的设置及分析
- SQL语句优化技术分析