MapReduce工作原理及流程
2018-01-27 19:54
274 查看
一、MapReduce工作原理
作业执行涉及4个独立的实体1、客户端,用来提交MapReduce作业
2、JobTracker,用来协调作业的运行
3、TaskTracker,用来处理作业划分后的任务
4、HDFS,用来在其它实体间共享作业文件
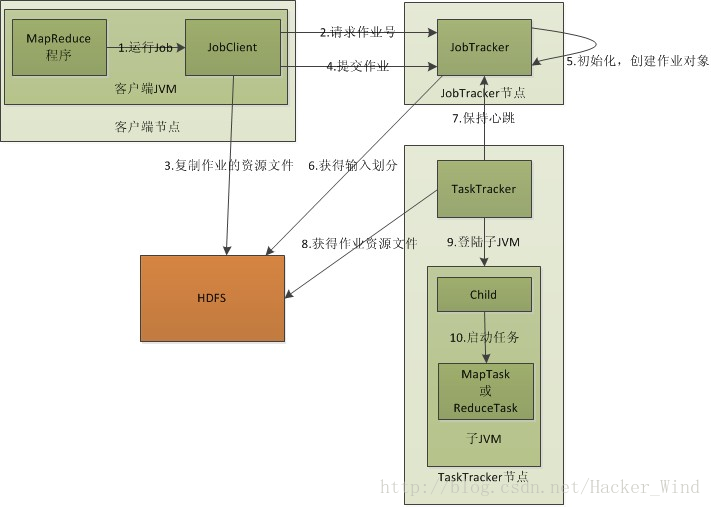
首先是客户端要编写好mapreduce程序,配置好mapreduce的作业也就是job,
接下来就是提交job了,提交job是提交到JobTracker上的,这个时候JobTracker就会构建这个job,具体就是分配一个新的job任务的ID值
接下来它会做检查操作,这个检查就是确定输出目录是否存在,如果存在那么job就不能正常运行下去,JobTracker会抛出错误给客户端,接下来还要检查输入目录是否存在,如果不存在同样抛出错误,如果存在JobTracker会根据输入计算输入分片(Input Split),如果分片计算不出来也会抛出错误,至于输入分片我后面会做讲解的,这些都做好了JobTracker就会配置Job需要的资源了。
分配好资源后,JobTracker就会初始化作业,初始化主要做的是将Job放入一个内部的队列,让配置好的作业调度器能调度到这个作业,作业调度器会初始化这个job,初始化就是创建一个正在运行的job对象(封装任务和记录信息),以便JobTracker跟踪job的状态和进程。
初始化完毕后,作业调度器会获取输入分片信息(input split),每个分片创建一个map任务。
接下来就是任务分配了,这个时候tasktracker会运行一个简单的循环机制定期发送心跳给jobtracker,心跳间隔是5秒,程序员可以配置这个时间,心跳就是jobtracker和tasktracker沟通的桥梁,通过心跳,jobtracker可以监控tasktracker是否存活,也可以获取tasktracker处理的状态和问题,同时tasktracker也可以通过心跳里的返回值获取jobtracker给它的操作指令。
任务分配好后就是执行任务了。在任务执行时候jobtracker可以通过心跳机制监控tasktracker的状态和进度,同时也能计算出整个job的状态和进度,而tasktracker也可以本地监控自己的状态和进度。当jobtracker获得了最后一个完成指定任务的tasktracker操作成功的通知时候,jobtracker会把整个job状态置为成功,然后当客户端查询job运行状态时候(注意:这个是异步操作),客户端会查到job完成的通知的。如果job中途失败,mapreduce也会有相应机制处理,一般而言如果不是程序员程序本身有bug,mapreduce错误处理机制都能保证提交的job能正常完成。
二、运行机制

在Hadoop中,一个MapReduce作业会把输入的数据集切分为若干独立的数据块,由Map任务以完全并行的方式处理
框架会对Map的输出先进行排序,然后把结果输入给Reduce任务。
作业的输入和输出都会被存储在文件系统中,整个框架负责任务的调度和监控,以及重新执行已经关闭的任务
MapReduce框架和分布式文件系统是运行在一组相同的节点,计算节点和存储节点都是在一起的
三、作业处理流程

按照时间顺序包括:
输入分片(input split)、
map阶段、
combiner阶段、
shuffle阶段和
reduce阶段。

相关文章推荐
- Mapreduce工作原理及流程
- MapReduce工作原理流程简介
- Hadoop二次排序及MapReduce处理流程实例详解
- Android系统Recovery工作原理之使用update.zip升级过程分析(六)---Recovery服务流程细节
- MapReduce作业运行流程
- struts2工作原理和流程
- View视图状态及View重绘流程分析,View工作原理(三)
- Hadoop回顾--MapReduce工作原理(一)
- hadoop mapreduce作业流程概论
- hadoop mapreduce作业提交流程
- K-MEANS算法的工作原理及流程
- Struts2 --- Struts2的运行流程及其工作原理
- MapReduce 图解流程超详细解答(1)-【map阶段】
- MapReduce的执行流程
- MapReduce任务创建和分配流程
- Mapreduce作业的工作原理
- mapreduce系列(2)shuffle流程及Combiner
- Struts 2 的学习笔记(二) struts的配置流程和strut是2的工作原理
- hadoop-mapReduce工作流程和组件简介
- Hadoop 4、Hadoop MapReduce的工作原理