caffe中五种层的实现与参数配置(1)------卷积层
2018-01-27 18:28
351 查看
卷积层的作用主要是把一些特征做强化,使特征的位置更突出
1.框架理解
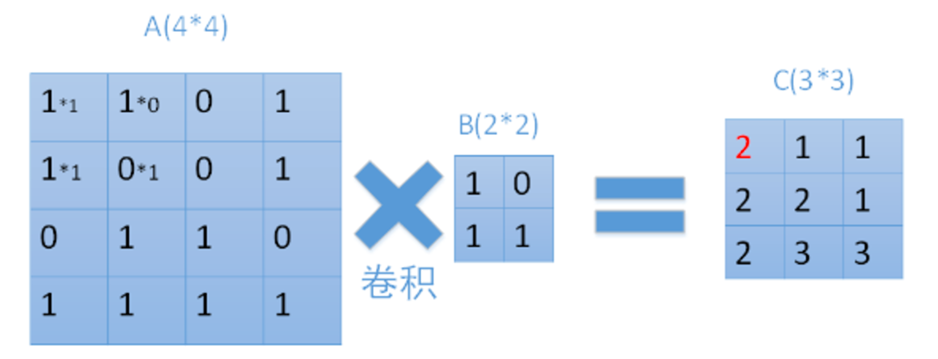
输入一个图像A的大小是4*4,经过2*2的卷积B,且步长为1,得到一个(4-2+1)×(4-2+1)=3*3的mapC
每个map是不同卷积核在前一层每个map上进行卷积,并将每个对应位置上的值相加然后再加上一个偏置项。
2.参数理解
layer {
name: "conv2" #该层的名字
type: "Convolution" #该层的类型,说明该层是卷积层
bottom: "pool1" #该层输入数据blob的名字
top: "conv2" #该层输出数据blob的名字
#该层的权值和偏置相关参数
param {
lr_mult: 1 #weight的学习率1,和权值更新相关
}
param {
lr_mult: 2 #bias的学习率2,和权值更新相关
}
convolution_param {
num_output: 50 # 50个输出的map
kernel_size: 5 #卷积核大小为5*5
stride: 1 #卷积步长为1
weight_filler { #权值初始化方式
type: “xavier" #默认为“constant",值全为0,很多时候我们也可以用"xavier"或者”gaussian"来进行初始化
}
bias_filler { #偏置值的初始化方式
type: “constant"#该参数的值和weight_filler类似,一般设置为"constant",值全为0
}
}
}以下转载:https://www.cnblogs.com/lutingting/p/5240629.html
3. 卷积层相关参数
接下来,分别对卷积层的相关参数进行说明
(根据卷积层的定义,它的学习参数应该为filter的取值和bias的取值,其他的相关参数都为hyper-paramers,在定义模型时是要给出的)
该系数用来控制学习率,在进行训练过程中,该层参数以该系数乘solver.prototxt配置文件中的base_lr的值为学习率
即学习率=lr_mult*base_lr
如果该层在结构配置文件中有两个lr_mult,则第一个表示fitler的权值学习率系数,第二个表示偏执项的学习率系数(一般情况下,偏执项的学习率系数是权值学习率系数的两倍)
该部分对卷积层的其他参数进行设置,有些参数为必须设置,有些参数为可选(因为可以直接使用默认值)
kernel_size:卷积层的filter的大小(直接用该参数时,是filter的长宽相等,2D情况时,也可以设置为不能,此时,利用kernel_h和kernel_w两个参数设定)
pad:是否对输入的image进行padding,默认值为0,即不填充(注意,进行padding可能会带来一些无用信息,输入image较小时,似乎不太合适)
weight_filter:权值初始化方法,使用方法如下
weight_filter{
type:"xavier" //这里的xavier是一冲初始化算法,也可以是“gaussian”;默认值为“constant”,即全部为0
}
bias_filter:偏执项初始化方法
bias_filter{
type:"xavier" //这里的xavier是一冲初始化算法,也可以是“gaussian”;默认值为“constant”,即全部为0
}
bias_term:是否使用偏执项,默认值为Ture
1.框架理解
输入一个图像A的大小是4*4,经过2*2的卷积B,且步长为1,得到一个(4-2+1)×(4-2+1)=3*3的mapC
每个map是不同卷积核在前一层每个map上进行卷积,并将每个对应位置上的值相加然后再加上一个偏置项。
2.参数理解
layer {
name: "conv2" #该层的名字
type: "Convolution" #该层的类型,说明该层是卷积层
bottom: "pool1" #该层输入数据blob的名字
top: "conv2" #该层输出数据blob的名字
#该层的权值和偏置相关参数
param {
lr_mult: 1 #weight的学习率1,和权值更新相关
}
param {
lr_mult: 2 #bias的学习率2,和权值更新相关
}
convolution_param {
num_output: 50 # 50个输出的map
kernel_size: 5 #卷积核大小为5*5
stride: 1 #卷积步长为1
weight_filler { #权值初始化方式
type: “xavier" #默认为“constant",值全为0,很多时候我们也可以用"xavier"或者”gaussian"来进行初始化
}
bias_filler { #偏置值的初始化方式
type: “constant"#该参数的值和weight_filler类似,一般设置为"constant",值全为0
}
}
}以下转载:https://www.cnblogs.com/lutingting/p/5240629.html
3. 卷积层相关参数
接下来,分别对卷积层的相关参数进行说明
(根据卷积层的定义,它的学习参数应该为filter的取值和bias的取值,其他的相关参数都为hyper-paramers,在定义模型时是要给出的)
lr_mult:学习率系数
放置在param{}中该系数用来控制学习率,在进行训练过程中,该层参数以该系数乘solver.prototxt配置文件中的base_lr的值为学习率
即学习率=lr_mult*base_lr
如果该层在结构配置文件中有两个lr_mult,则第一个表示fitler的权值学习率系数,第二个表示偏执项的学习率系数(一般情况下,偏执项的学习率系数是权值学习率系数的两倍)
convolution_praram:卷积层的其他参数
放置在convoluytion_param{}中该部分对卷积层的其他参数进行设置,有些参数为必须设置,有些参数为可选(因为可以直接使用默认值)
必须设置的参数
num_output:该卷积层的filter个数kernel_size:卷积层的filter的大小(直接用该参数时,是filter的长宽相等,2D情况时,也可以设置为不能,此时,利用kernel_h和kernel_w两个参数设定)
其他可选的设置参数
stride:filter的步长,默认值为1pad:是否对输入的image进行padding,默认值为0,即不填充(注意,进行padding可能会带来一些无用信息,输入image较小时,似乎不太合适)
weight_filter:权值初始化方法,使用方法如下
weight_filter{
type:"xavier" //这里的xavier是一冲初始化算法,也可以是“gaussian”;默认值为“constant”,即全部为0
}
bias_filter:偏执项初始化方法
bias_filter{
type:"xavier" //这里的xavier是一冲初始化算法,也可以是“gaussian”;默认值为“constant”,即全部为0
}
bias_term:是否使用偏执项,默认值为Ture

相关文章推荐
- caffe中五种层的实现与参数配置(3)------激活函数层
- Caffe学习笔记5--Caffe可视化和五种类型的层的实现和参数配置
- Caffe源码解读(十):Caffe五种层的实现和参数配置
- caffe中五种层的实现与参数配置(4)------softmax层
- Struts2不配置result参数 进行跳转实现
- LeNet-5结构分析及caffe实现————卷积部分
- 在resin配置参数实现JConsole远程监控JVM
- caffe CNN train_val.prototxt 神经网络参数配置说明
- caffe实现3D卷积代码 C3D 安装遇到的问题记录
- 22-FCKEditor参数配置 (通过JS文件实现)
- (不推荐使用)springMVC基本配置+继承MultiActionController来实现根据参数名指定要请求的方法
- caffe源码 之 卷积层实现
- Faster rcnn test浮点运算次数(卷积实现过程,Faster rcnn总体结构和参数)
- Vivado bug大揭秘——综合实现参数配置中的Bug及解决办法
- Caffe卷积层的实现细节
- caffe代码阅读10:Caffe中卷积的实现细节(涉及到BaseConvolutionLayer、ConvolutionLayer、im2col等)-2016.4.3
- caffe的卷积实现-1资料整理
- caffe中的卷积实现
- CNN的超参数 & 宽卷积和窄卷积的理解及tensorflow中的实现
- Caffe中卷积层的实现