SQL_DISTINCT 语句详细用法
2018-01-25 17:08
591 查看
一 测试数据构建
二 基本使用(单独使用)
三 聚合函数中的DISTINCT
下面全部是在MySQL 的环境下进行测试的!!!!!
一 测试数据构建
数据表 跟 数据
样例数据
二 基本使用(单独使用)
介绍
distinct一般是用来去除查询结果中的重复记录的,而且这个语句在select、insert、delete和update中只可以在select中使用,
具体的语法如下:
select distinct expression[,expression...] from tables [where conditions];
这里的expressions可以是多个字段。
示例:
只能在SELECT 语句中使用,不能在 INSERT, DELETE, UPDATE 中使用

2.1 只对一列操作
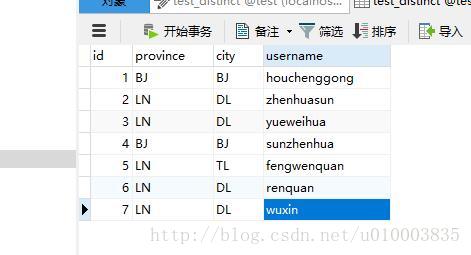
对一列操作,表示选取该列不重复的数据项,这是用的比较多的一种用法
测试数据

SELECT DISTINCT city FROM test_distinct;
2.2 对多列操作
对多列操作,表示选取 多列都不重复的数据,相当于 多列拼接的记录 的整个一条记录 , 不重复的记录。
测试数据:

SELECT DISTINCT province, city FROM test_distinct;
结果:

注意:
1. DISTINCT 必须放在第一个参数。
错误示例:

2.DISTINCT 表示对后面的所有参数的拼接取 不重复的记录,相当于 把 SELECT 表达式的项 拼接起来选唯一值。
测试数据:
SELECT DISTINCT province,city FROM test_distinct;
期望值: 只对 第一个参数 province 取唯一值。
province city
BJ BJ
LN DL
Record LN(province), TL(city) 被过滤掉,实际上
实际值:
DISTINCT 表示对后面的所有参数的拼接取 不重复的记录,相当于 把 SELECT 表达式的项 拼接起来选唯一值。
解决方法:使得DISTINCT 只对其中某一项生效
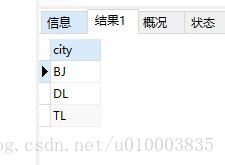
方法一: 利用 group_concat 函数
SELECT group_concat(DISTINCT province) AS province, city FROM test_distinct GROUP BY province;
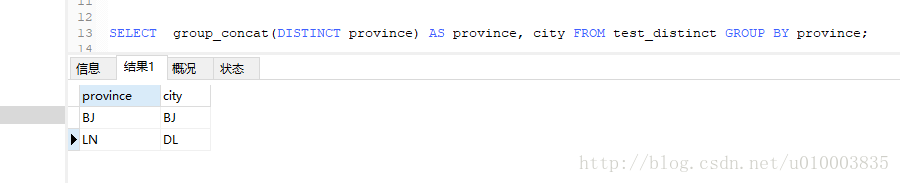
方法二: 不利用DISTINCT , 而是利用group by (我认为第一种方法 其实就是 第二种方法, 第一种方法也就是第二种方法)
SELECT province, city FROM test_distinct GROUP BY province;

最后,比较下这两种方法的执行效率,分别EXPLAIN 一下。
方法一
EXPLAIN SELECT group_concat(DISTINCT province) AS province, city FROM test_distinct GROUP BY province;

方法二
EXPLAIN SELECT province, city FROM test_distinct GROUP BY province;

2.3 针对NULL的处理
distinct对NULL是不进行过滤的,即返回的结果中是包含NULL值的。
测试数据:
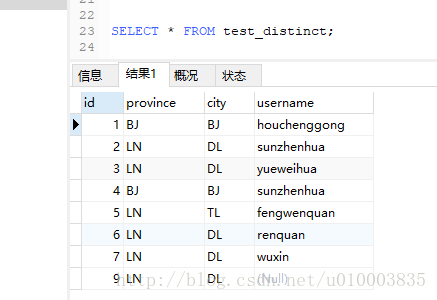
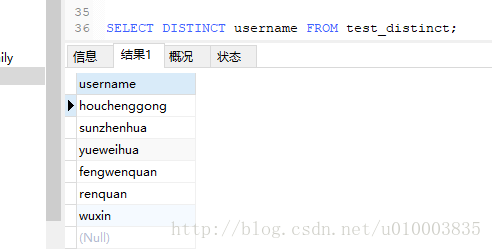
SELECT DISTINCT username FROM test_distinct;
2.4 与ALL不能同时使用
默认情况下,查询时返回所有的结果,此时使用的就是all语句,这是与distinct相对应的,如下:
测试数据:
SELECT ALL province, city FROM test_distinct;

2.5 与distinctrow同义
select distinctrow expression[,expression...] from tables [where conditions];
三 聚合函数中的DISTINCT
在聚合函数中DISTINCT 一般跟 COUNT 结合使用。
效果与 SELECT SUM (tmp.tmp_ct) FROM ( SELECT COUNT(name) AS tmp_ct GROUP BY name ) AS tmp 类似
但不相同 !!, COUNT 会过滤NULL , 而 第二种方法不会!!!!
示例:
测试数据:

SELECT COUNT(DISTINCT username) FROM test_distinct;
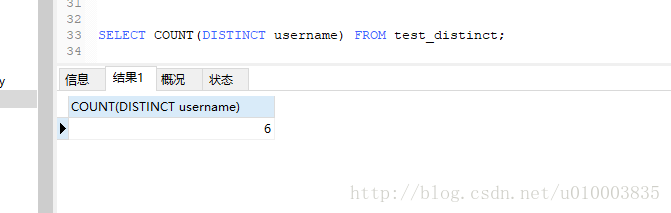
注意 COUNT( ) 会过滤掉为NULL 的项
再用 GROUP BY 试一下
SELECT SUM(tmp.u_ct) FROM (SELECT COUNT(username) AS u_ct FROM test_distinct GROUP BY username) AS tmp;

我们在子查询中调查一下:
SELECT username, COUNT(username) AS u_ct FROM test_distinct GROUP BY username

二 基本使用(单独使用)
三 聚合函数中的DISTINCT
下面全部是在MySQL 的环境下进行测试的!!!!!
一 测试数据构建
数据表 跟 数据
SET FOREIGN_KEY_CHECKS=0;
-- ----------------------------
-- Table structure for test_distinct
-- ----------------------------
DROP TABLE IF EXISTS `test_distinct`;
CREATE TABLE `test_distinct` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`province` varchar(255) DEFAULT NULL,
`city` varchar(255) DEFAULT NULL,
`username` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=gbk;
-- ----------------------------
-- Records of test_distinct
-- ----------------------------
INSERT INTO `test_distinct` VALUES ('1', 'BJ', 'BJ', 'houchenggong');
INSERT INTO `test_distinct` VALUES ('2', 'LN', 'DL', 'zhenhuasun');
INSERT INTO `test_distinct` VALUES ('3', 'LN', 'DL', 'yueweihua');
INSERT INTO `test_distinct` VALUES ('4', 'BJ', 'BJ', 'sunzhenhua');
INSERT INTO `test_distinct` VALUES ('5', 'LN', 'TL', 'fengwenquan');
INSERT INTO `test_distinct` VALUES ('6', 'LN', 'DL', 'renquan');
INSERT INTO `test_distinct` VALUES ('7', 'LN', 'DL', 'wuxin');样例数据
二 基本使用(单独使用)
介绍
distinct一般是用来去除查询结果中的重复记录的,而且这个语句在select、insert、delete和update中只可以在select中使用,
具体的语法如下:
select distinct expression[,expression...] from tables [where conditions];
这里的expressions可以是多个字段。
示例:
只能在SELECT 语句中使用,不能在 INSERT, DELETE, UPDATE 中使用
2.1 只对一列操作
对一列操作,表示选取该列不重复的数据项,这是用的比较多的一种用法
测试数据
SELECT DISTINCT city FROM test_distinct;
2.2 对多列操作
对多列操作,表示选取 多列都不重复的数据,相当于 多列拼接的记录 的整个一条记录 , 不重复的记录。
测试数据:
SELECT DISTINCT province, city FROM test_distinct;
结果:
注意:
1. DISTINCT 必须放在第一个参数。
错误示例:
2.DISTINCT 表示对后面的所有参数的拼接取 不重复的记录,相当于 把 SELECT 表达式的项 拼接起来选唯一值。
测试数据:
SELECT DISTINCT province,city FROM test_distinct;
期望值: 只对 第一个参数 province 取唯一值。
province city
BJ BJ
LN DL
Record LN(province), TL(city) 被过滤掉,实际上
实际值:
DISTINCT 表示对后面的所有参数的拼接取 不重复的记录,相当于 把 SELECT 表达式的项 拼接起来选唯一值。
解决方法:使得DISTINCT 只对其中某一项生效
方法一: 利用 group_concat 函数
SELECT group_concat(DISTINCT province) AS province, city FROM test_distinct GROUP BY province;
方法二: 不利用DISTINCT , 而是利用group by (我认为第一种方法 其实就是 第二种方法, 第一种方法也就是第二种方法)
SELECT province, city FROM test_distinct GROUP BY province;
最后,比较下这两种方法的执行效率,分别EXPLAIN 一下。
方法一
EXPLAIN SELECT group_concat(DISTINCT province) AS province, city FROM test_distinct GROUP BY province;
方法二
EXPLAIN SELECT province, city FROM test_distinct GROUP BY province;
2.3 针对NULL的处理
distinct对NULL是不进行过滤的,即返回的结果中是包含NULL值的。
测试数据:
SELECT DISTINCT username FROM test_distinct;
2.4 与ALL不能同时使用
默认情况下,查询时返回所有的结果,此时使用的就是all语句,这是与distinct相对应的,如下:
测试数据:
SELECT ALL province, city FROM test_distinct;
2.5 与distinctrow同义
select distinctrow expression[,expression...] from tables [where conditions];
三 聚合函数中的DISTINCT
在聚合函数中DISTINCT 一般跟 COUNT 结合使用。
效果与 SELECT SUM (tmp.tmp_ct) FROM ( SELECT COUNT(name) AS tmp_ct GROUP BY name ) AS tmp 类似
但不相同 !!, COUNT 会过滤NULL , 而 第二种方法不会!!!!
示例:
测试数据:
SELECT COUNT(DISTINCT username) FROM test_distinct;
注意 COUNT( ) 会过滤掉为NULL 的项
再用 GROUP BY 试一下
SELECT SUM(tmp.u_ct) FROM (SELECT COUNT(username) AS u_ct FROM test_distinct GROUP BY username) AS tmp;
我们在子查询中调查一下:
SELECT username, COUNT(username) AS u_ct FROM test_distinct GROUP BY username

相关文章推荐
- sql语句中的 in 、not in 、exists、not exists 详细用法说明和差别----not in失效
- UPDATE SQL语句详细用法
- 关于SQL 语句中distinct 关键词的用法小论
- sql语句中like的用法详细解析
- sql语句中like的用法详细解析
- 黑马程序员—SQL中group by 语句的含义和详细用法
- sql语句中的 in 、not in 、exists、not exists 详细用法说明和差别----not in失效
- SQL SERVER 2012 第三章 T-SQL 基本SELECT语句用法,Where子句详细用法
- sql存储过程详细用法介绍
- 合并union 和union all用法-sql语句查询结果
- LINQ体验(5)——LINQ to SQL语句之Select/Distinct和Count/Sum/Min/Max/Avg
- SQL语句Left join 中On和Where的用法区别
- Sql语句--日期函数用法
- With temp as---sql语句用法
- 超详细的SQL语句语法
- sql语句中not in和exists 的用法以及更新两个表数据的插入实例
- SQL SELECT DISTINCT 语句
- SQL语句中JOIN的用法
- 超详细的SQL语句语法汇总