斯坦福机器学习Coursera课程:第六周作业--支持向量机(SVM)
2018-01-22 18:41
501 查看
中间停了一段,课程任务是完成了,但都没在博客上记录和更新。最近抽空重新翻看下,作以记录。
本次作业主要两个内容:不同数据集的模型训练和垃圾邮件分类器。
首先是把数据图形化展现后,根据不同的C值画出不同不分类边界(C相当于线性/逻辑回归线中的正则化参数),以对应
C 较大时,相当于λ较小,可能会导致过拟合,高方差;
C 较小时,相当于λ较大,可能会导致低拟合,高偏差;
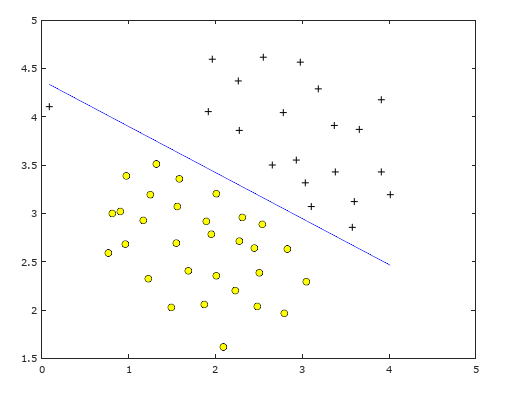
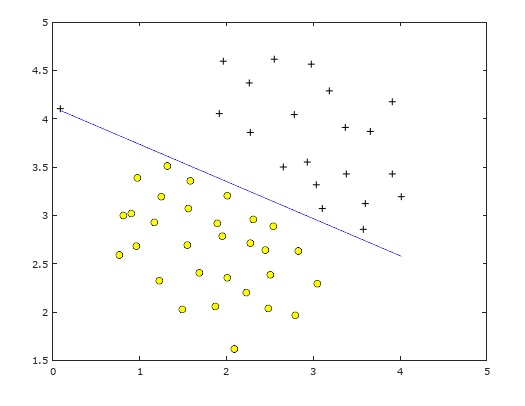
下面是C分别为1和100时的分类边界;很明显C=1时分类较好,C=10,100时分类边界逐渐倾斜,为了一个异常点导致了过拟合。

有了宏观认识后,下来才开始真正作业。实现高斯型核函数:

代码如下:
sim=sim+exp(-(x1-x2)'*(x1-x2)/2/sigma^2);
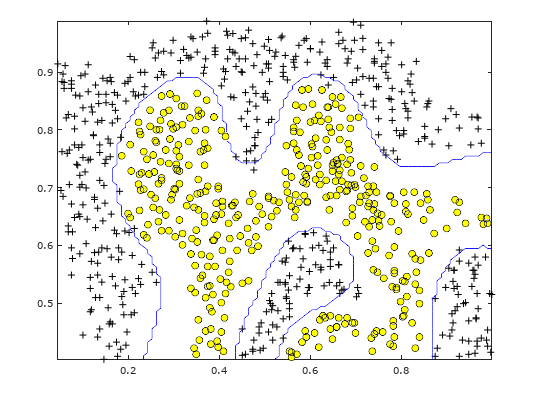
然后对数据集2使用C = 1; sigma = 0.1及此核函数训练出模型并画出分类边界。
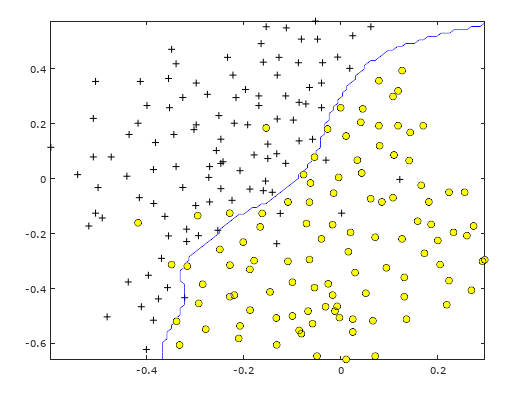
针对数据集3,要求在多个不同的C/sigma中计算尝试,选取较好的C/Sigma值作迭代训练。
要实现的代码如下,pdf文档中有说明,实现相对不难。
dataset3Params.m:
err=10000;
temp=[0.01,0.03,0.1,0.3,1,3,10,30];
for i=1:length(temp)
for j=1:length(temp)
model= svmTrain(X, y, temp(i), @(x1, x2) gaussianKernel(x1, x2,temp(j)));
predictions = svmPredict(model, Xval);
if(err>mean(double(predictions ~= yval)))
err=mean(double(predictions ~= yval));
C=temp(i);
sigma=temp(j);
end
end
end
较好的参数值为: C: sigma = 0.100000 , C= 1.000000。
Implementation Tip: When implementing cross validation to select the best C and parameter to use, you need to evaluate the error on the cross validation set. Recall that for classi cation, the error is dened as the fraction of the cross validation examples
that were classied incorrectly. In Octave/MATLAB, you can compute this error using mean(double(predictions ~= yval)), where predictions is a vector containing all the predictions from the SVM, and yval are the true labels from the
cross validation set. You can use the svmPredict function to generate the predictions for the cross validation set.
图形如下:
垃圾邮件分类:
基本原理 :根据词库中收集的常在垃圾邮件中出现的词,对测试邮件中的词进行预处理后,找到这些词在词库中的索引值(word_indices),并根据索引值构造邮件的特征向量(以词库容量为全集,测试邮件中的词为词库中的时,对应索引记为1,未出现的记为0)。然后开始对训练集、测试集进行训练(线性核函数),并计算出精度。
最后还有额外两步:列出容易识别为垃圾邮件的前15个词汇;用样例邮件或其它邮件让分类器识别是否为垃圾邮件。
有了上述知识后,相关的代码实现很简单,就是找出索引值,构建特征,代码如下:
processEmail.m:
for i=1:length(vocabList)
if(strcmp(vocabList(i),str))
word_indices=[word_indices;i]; //构建索引序列
end
end
emailFeatures.m
for i=1:length(word_indices)
x(word_indices(i))=1; //构建特征向量,词库容量为1899, x中为了的为45个
end
下面是输出日志:
Preprocessing sample email (emailSample1.txt)
==== Processed Email ====
anyon know how much it cost to host a web portal well it depend on how mani visitor you re expect thi can be anywher from less than number buck a month to a coupl of dollarnumb you should checkout httpaddr or perhap amazon ecnumb if your run someth big to unsubscrib
yourself from thi mail list send an email to emailaddr
=========================
Word Indices:
86 916 794 1077 883 370 1699 790 1822 1831 883 431 1171 794 1002 1893 1364 592 1676
238 162 89 688 945 1663 1120 1062 1699 375 1162 479 1893 1510 799 1182 1237 810 1895
1440 1547 181 1699 1758 1896 688 1676 992 961 1477 71 530 1699 531
Program paused. Press enter to continue.
Extracting features from sample email (emailSample1.txt)
==== Processed Email ====
anyon know how much it cost to host a web portal well it depend on how mani
visitor you re expect thi can be anywher from less than number buck a month
to a coupl of dollarnumb you should checkout httpaddr or perhap amazon ecnumb
if your run someth big to unsubscrib yourself from thi mail list send an
email to emailaddr
=========================
Length of feature vector: 1899
Number of non-zero entries: 45
non-zero entries of features: 0
non-zero entries of features: 0
non-zero entries of features: 0
non-zero entries of features: 0
non-zero entries of features: 0
........
Training Linear SVM (Spam Classification)
(this may take 1 to 2 minutes) ...
Training ..................................................................................................................................................................................................................................
............................... Done!
Training Accuracy: 99.825000 //训练集精度
Evaluating the trained Linear SVM on a test set ...
Test Accuracy: 98.800000 //测试集精度
Top predictors of spam:
our (0.499063)
click (0.465898)
remov (0.422430)
guarante (0.383453)
visit (0.369755)
basenumb (0.345419)
dollar (0.323258)
price (0.267478)
will (0.266835)
pleas (0.263838)
lo (0.258761)
nbsp (0.255940)
most (0.255197)
ga (0.244134)
da (0.238484)
Program paused. Press enter to continue.
==== Processed Email ====
now that you ve train the spam classifi you can us it on your own email in
the starter code we have includ spamsamplenumb txt spamsamplenumb txt
emailsamplenumb txt and emailsamplenumb txt as exampl the follow code read in
on of these email and then us your learn svm classifi to determin whether the
email is spam or not spam set the file to be read in chang thi to
spamsamplenumb txt emailsamplenumb txt or emailsamplenumb txt to see differ
predict on differ email type try your own email as well
=========================
Processed spamSample3.txt
Spam Classification: 0
(1 indicates spam, 0 indicates not spam)
最后,对SVM相关的总结点,记录如下作参考:
针对核函数,由所取的地标所得出的判定边界,在预测时,我们采用的特征不是训练实例本身的特征,而是通过核函数计算出的新特征f1,f2,f3。
支持向量机的两个参数C和σ的影响:
C 较大时,相当于λ较小,可能会导致过拟合,高方差;
C 较小时,相当于λ较大,可能会导致低拟合,高偏差;
σ较大时,导致高方差;
σ较小时,导致高偏差。
下面是一些普遍使用的准则:n为特征数,m为训练样本数。
(1)如果相较于m而言,n要大许多,即训练集数据量不够支持我们训练一个复杂的非线性模型,我们选用逻辑回归模型或者不带核函数的支持向量机。
(2)如果n较小,而且m大小中等,例如n在1-1000 之间,而m在10-10000 之间,使用高斯核函数的支持向量机。
(3)如果n较小,而m较大,例如n在1-1000之间,而m大于50000,则使用支持向量机会非常慢,解决方案是创造、增加更多的特征,然后使用逻辑回归或不带核函数的支持向量机。
值得一提的是,神经网络在以上三种情况下都可能会有较好的表现,但是训练神经网络可能非常慢,选择支持向量机的原因主要在于它的代价函数是凸函数,不存在局部最小值。
本次作业主要两个内容:不同数据集的模型训练和垃圾邮件分类器。
首先是把数据图形化展现后,根据不同的C值画出不同不分类边界(C相当于线性/逻辑回归线中的正则化参数),以对应
C 较大时,相当于λ较小,可能会导致过拟合,高方差;
C 较小时,相当于λ较大,可能会导致低拟合,高偏差;
下面是C分别为1和100时的分类边界;很明显C=1时分类较好,C=10,100时分类边界逐渐倾斜,为了一个异常点导致了过拟合。
有了宏观认识后,下来才开始真正作业。实现高斯型核函数:
代码如下:
sim=sim+exp(-(x1-x2)'*(x1-x2)/2/sigma^2);
然后对数据集2使用C = 1; sigma = 0.1及此核函数训练出模型并画出分类边界。
针对数据集3,要求在多个不同的C/sigma中计算尝试,选取较好的C/Sigma值作迭代训练。
要实现的代码如下,pdf文档中有说明,实现相对不难。
dataset3Params.m:
err=10000;
temp=[0.01,0.03,0.1,0.3,1,3,10,30];
for i=1:length(temp)
for j=1:length(temp)
model= svmTrain(X, y, temp(i), @(x1, x2) gaussianKernel(x1, x2,temp(j)));
predictions = svmPredict(model, Xval);
if(err>mean(double(predictions ~= yval)))
err=mean(double(predictions ~= yval));
C=temp(i);
sigma=temp(j);
end
end
end
较好的参数值为: C: sigma = 0.100000 , C= 1.000000。
Implementation Tip: When implementing cross validation to select the best C and parameter to use, you need to evaluate the error on the cross validation set. Recall that for classi cation, the error is dened as the fraction of the cross validation examples
that were classied incorrectly. In Octave/MATLAB, you can compute this error using mean(double(predictions ~= yval)), where predictions is a vector containing all the predictions from the SVM, and yval are the true labels from the
cross validation set. You can use the svmPredict function to generate the predictions for the cross validation set.
图形如下:
垃圾邮件分类:
基本原理 :根据词库中收集的常在垃圾邮件中出现的词,对测试邮件中的词进行预处理后,找到这些词在词库中的索引值(word_indices),并根据索引值构造邮件的特征向量(以词库容量为全集,测试邮件中的词为词库中的时,对应索引记为1,未出现的记为0)。然后开始对训练集、测试集进行训练(线性核函数),并计算出精度。
最后还有额外两步:列出容易识别为垃圾邮件的前15个词汇;用样例邮件或其它邮件让分类器识别是否为垃圾邮件。
有了上述知识后,相关的代码实现很简单,就是找出索引值,构建特征,代码如下:
processEmail.m:
for i=1:length(vocabList)
if(strcmp(vocabList(i),str))
word_indices=[word_indices;i]; //构建索引序列
end
end
emailFeatures.m
for i=1:length(word_indices)
x(word_indices(i))=1; //构建特征向量,词库容量为1899, x中为了的为45个
end
下面是输出日志:
Preprocessing sample email (emailSample1.txt)
==== Processed Email ====
anyon know how much it cost to host a web portal well it depend on how mani visitor you re expect thi can be anywher from less than number buck a month to a coupl of dollarnumb you should checkout httpaddr or perhap amazon ecnumb if your run someth big to unsubscrib
yourself from thi mail list send an email to emailaddr
=========================
Word Indices:
86 916 794 1077 883 370 1699 790 1822 1831 883 431 1171 794 1002 1893 1364 592 1676
238 162 89 688 945 1663 1120 1062 1699 375 1162 479 1893 1510 799 1182 1237 810 1895
1440 1547 181 1699 1758 1896 688 1676 992 961 1477 71 530 1699 531
Program paused. Press enter to continue.
Extracting features from sample email (emailSample1.txt)
==== Processed Email ====
anyon know how much it cost to host a web portal well it depend on how mani
visitor you re expect thi can be anywher from less than number buck a month
to a coupl of dollarnumb you should checkout httpaddr or perhap amazon ecnumb
if your run someth big to unsubscrib yourself from thi mail list send an
email to emailaddr
=========================
Length of feature vector: 1899
Number of non-zero entries: 45
non-zero entries of features: 0
non-zero entries of features: 0
non-zero entries of features: 0
non-zero entries of features: 0
non-zero entries of features: 0
........
Training Linear SVM (Spam Classification)
(this may take 1 to 2 minutes) ...
Training ..................................................................................................................................................................................................................................
............................... Done!
Training Accuracy: 99.825000 //训练集精度
Evaluating the trained Linear SVM on a test set ...
Test Accuracy: 98.800000 //测试集精度
Top predictors of spam:
our (0.499063)
click (0.465898)
remov (0.422430)
guarante (0.383453)
visit (0.369755)
basenumb (0.345419)
dollar (0.323258)
price (0.267478)
will (0.266835)
pleas (0.263838)
lo (0.258761)
nbsp (0.255940)
most (0.255197)
ga (0.244134)
da (0.238484)
Program paused. Press enter to continue.
==== Processed Email ====
now that you ve train the spam classifi you can us it on your own email in
the starter code we have includ spamsamplenumb txt spamsamplenumb txt
emailsamplenumb txt and emailsamplenumb txt as exampl the follow code read in
on of these email and then us your learn svm classifi to determin whether the
email is spam or not spam set the file to be read in chang thi to
spamsamplenumb txt emailsamplenumb txt or emailsamplenumb txt to see differ
predict on differ email type try your own email as well
=========================
Processed spamSample3.txt
Spam Classification: 0
(1 indicates spam, 0 indicates not spam)
最后,对SVM相关的总结点,记录如下作参考:
针对核函数,由所取的地标所得出的判定边界,在预测时,我们采用的特征不是训练实例本身的特征,而是通过核函数计算出的新特征f1,f2,f3。
支持向量机的两个参数C和σ的影响:
C 较大时,相当于λ较小,可能会导致过拟合,高方差;
C 较小时,相当于λ较大,可能会导致低拟合,高偏差;
σ较大时,导致高方差;
σ较小时,导致高偏差。
下面是一些普遍使用的准则:n为特征数,m为训练样本数。
(1)如果相较于m而言,n要大许多,即训练集数据量不够支持我们训练一个复杂的非线性模型,我们选用逻辑回归模型或者不带核函数的支持向量机。
(2)如果n较小,而且m大小中等,例如n在1-1000 之间,而m在10-10000 之间,使用高斯核函数的支持向量机。
(3)如果n较小,而m较大,例如n在1-1000之间,而m大于50000,则使用支持向量机会非常慢,解决方案是创造、增加更多的特征,然后使用逻辑回归或不带核函数的支持向量机。
值得一提的是,神经网络在以上三种情况下都可能会有较好的表现,但是训练神经网络可能非常慢,选择支持向量机的原因主要在于它的代价函数是凸函数,不存在局部最小值。

相关文章推荐
- Coursera吴恩达机器学习课程 总结笔记及作业代码——第7周支持向量机
- 吴恩达Coursera深度学习课程 DeepLearning.ai 编程作业——Initialize parameter(2-1.1)
- 吴恩达Coursera深度学习课程 DeepLearning.ai 编程作业——Tensorflow+tutorial(2-3)
- 吴恩达Coursera深度学习课程 DeepLearning第一课第二周编程作业
- Coursera 机器学习(by Andrew Ng)课程学习笔记 Week 9(二)——推荐系统作业
- Coursera吴恩达机器学习课程 第2周作业代码
- 吴恩达Coursera深度学习课程 DeepLearning.ai 编程作业——Regularization(2-1.2)
- Coursera_Stanford_ML_ex6_支持向量机(SVM) 作业记录
- Coursera吴恩达机器学习课程 编程作业
- Coursera吴恩达机器学习课程 总结笔记及作业代码——第5周神经网络续
- Coursera吴恩达机器学习课程 总结笔记及作业代码——第3周逻辑回归
- Coursera吴恩达机器学习课程 总结笔记及作业代码——第1,2周
- 吴恩达Coursera深度学习课程 DeepLearning.ai 编程作业——Gradients_check(2-1.3)
- 吴恩达Coursera深度学习课程 DeepLearning.ai 编程作业——Optimization Methods(2-2)
- Coursera吴恩达机器学习课程 总结笔记及作业代码——第4周神经网络
- 斯坦福机器学习Coursera课程:第二周作业--一元和多元线性回归
- 吴恩达Coursera深度学习课程 DeepLearning.ai 编程作业——Autonomous driving - Car detection(4.3)
- 吴恩达Coursera深度学习课程 DeepLearning.ai 编程作业——Convolution model:step by step and application (4.1)
- 吴恩达Coursera深度学习课程 DeepLearning.ai 编程作业——Keras tutorial - the Happy House (4.2)
- 作业——在线学习Android课程之第六周