MaxCompute Studio使用心得:一个工具完成整个Python UDF开发
2018-01-22 17:53
1141 查看
2017/12/20 北京云栖大会上阿里云MaxCompute发布了最新的功能Python UDF,万众期待的功能终于支持啦,我怎么能不一试为快,今天就分享如何通过Studio进行Python udf开发。
原文:http://click.aliyun.com/m/40729/
前置条件
了解到,虽然功能发布,不过还在公测阶段,如果想要使用,还得申请开通:https://page.aliyun.com/form/odps_py/pc/index.htm。这里我就不介绍申请开通具体流程了。
环境准备
MaxCompute Studio支持Python UDF开发,前提需要安装python, pyodps和idea的python插件。
1. 安装Python:可以Google或者百度搜索下如何安装。
2. 安装pyodps:可以参考python sdk文档的安装步骤。即,在 Python 2.6 以上(包括 Python 3),系统安装 pip 后,只需运行下 pip install pyodps,PyODPS 的相关依赖便会自动安装。
3. Intellij IDEA中安装Python插件。搜索Python Community Edition插件并安装
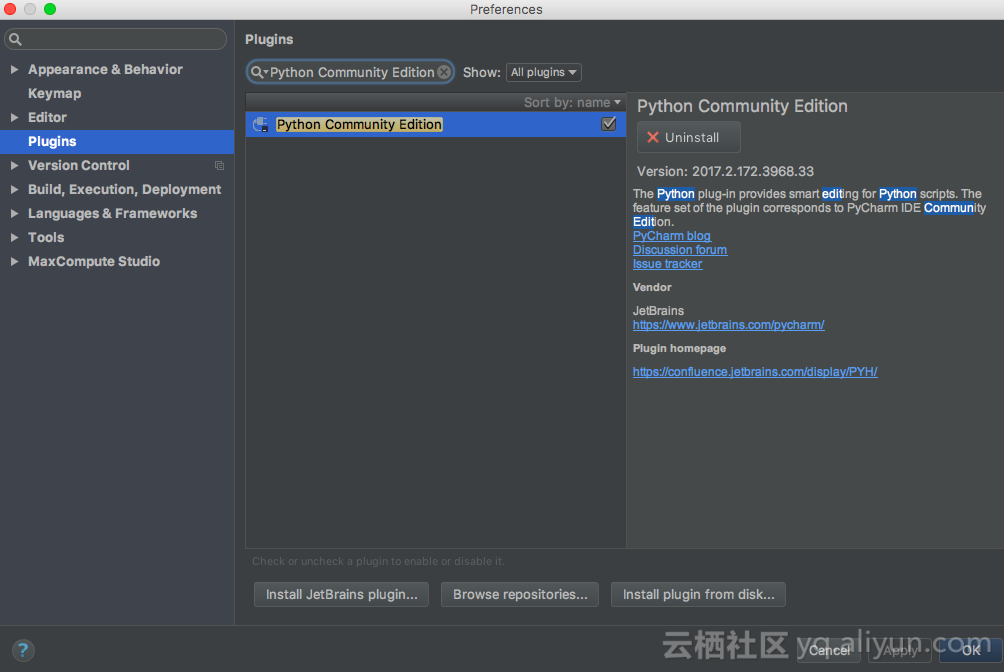
4. 配置studio module对python的依赖。
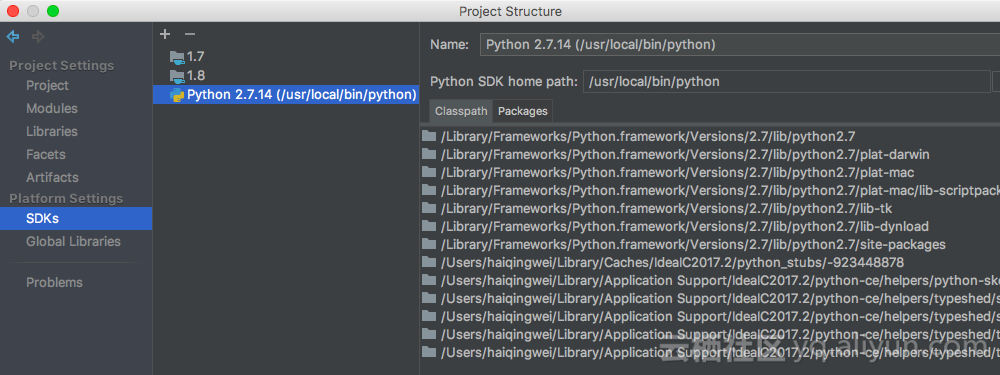
File -> Project structure,添加python sdk:
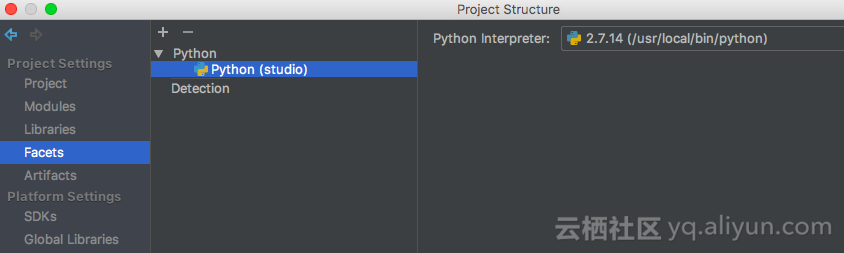
File -> Project structure,添加python facets:
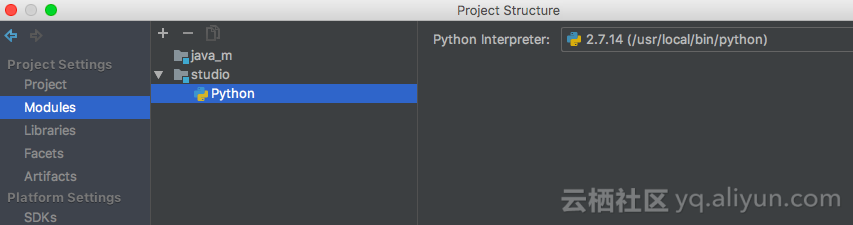
File -> Project structure,配置module依赖python facets:
开发Python UDF
环境都准备好后,既可在对应依赖的module里创建进行python udf开发。
新建python脚本
右键 new | MaxCompute Python,弹框里输入脚本名称,选择类型为python udf:
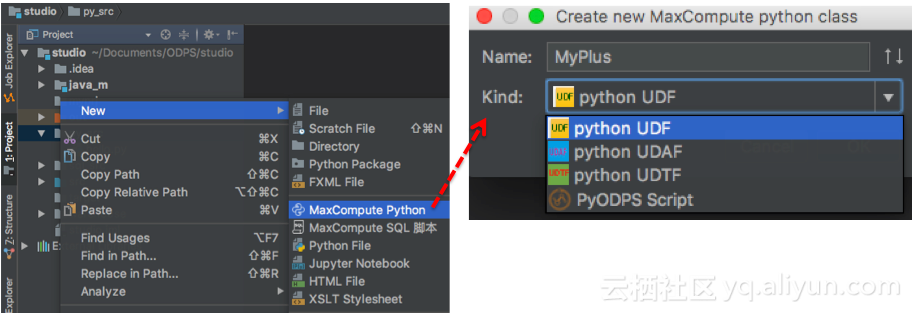
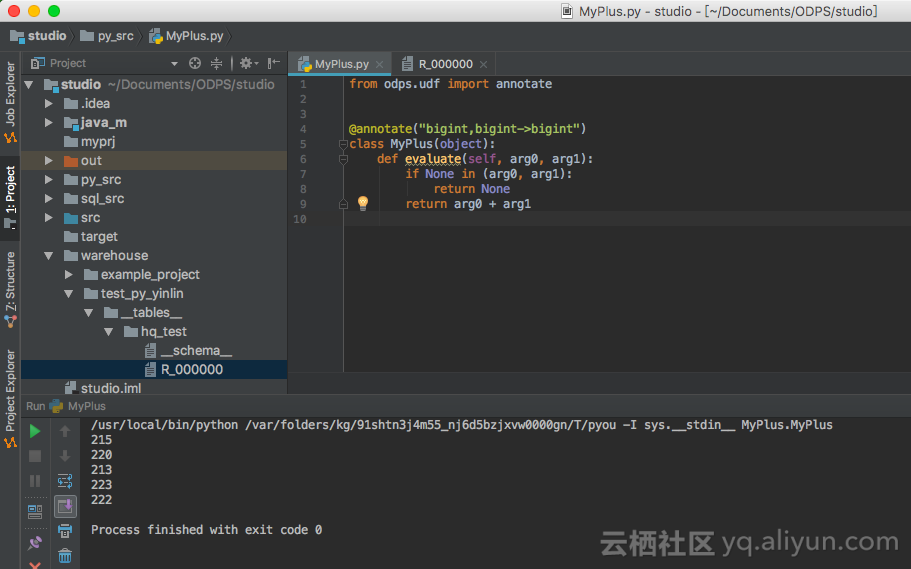
生成的模板已自动填充框架代码,只需要编写UDF的入参出参,以及函数逻辑:
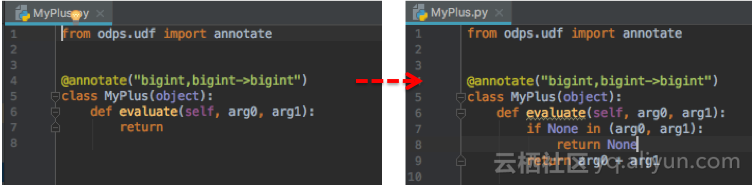
本地调试
代码开发好后,可以在Studio中进行本地调试。Studio支持下载表的部分sample数据到本地运行,进行debug,步骤如下:
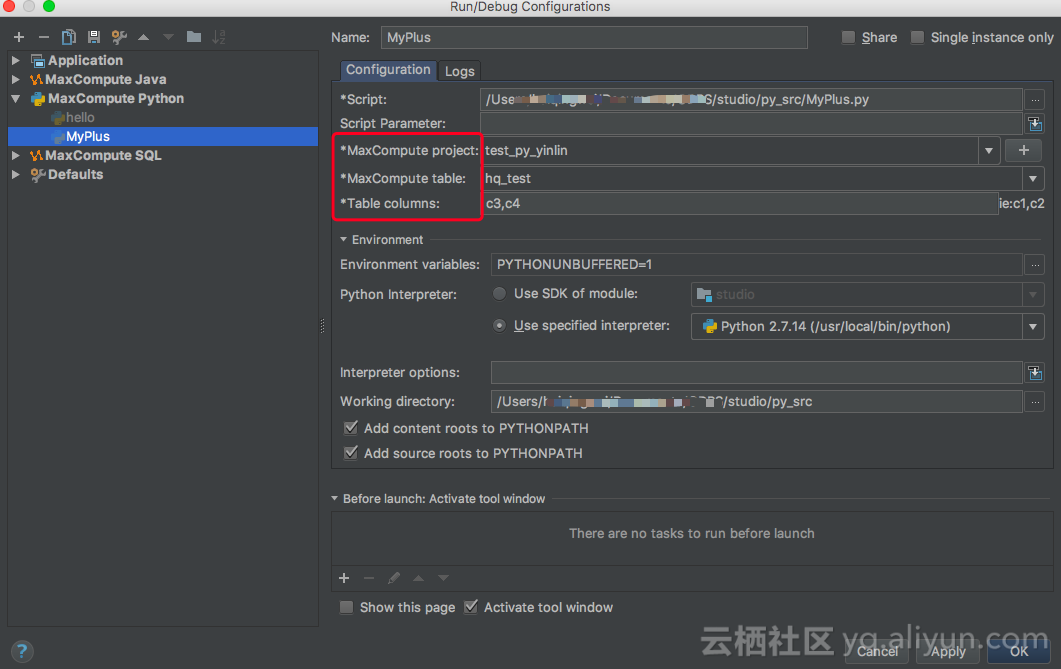
1. 右键python udf类,点击”运行”菜单,弹出run configuration对话框。UDF|UDAF|UDTF一般作用于select子句中表的某些列,此处需配置MaxCompute project,table和column(元数据来源于project explorer窗口和warehouse下的example项目):
2. 点击OK后,通过tunnel自动下载指定表的sample数据到本地warehouse目录(若之前已下载过,则不会再次重复下载,否则利用tunnel服务下载数据。默认下载100条,如需更多数据测试,可自行使用console的tunnel命令或者studio的表下载功能)。下载完成后,可以在warehouse目录看到下载的sample数据。这里用户也可以使用warehouse里的数据进行调试,具体可参考java udf开发中的关于本地运行的warehouse目录”部分)。
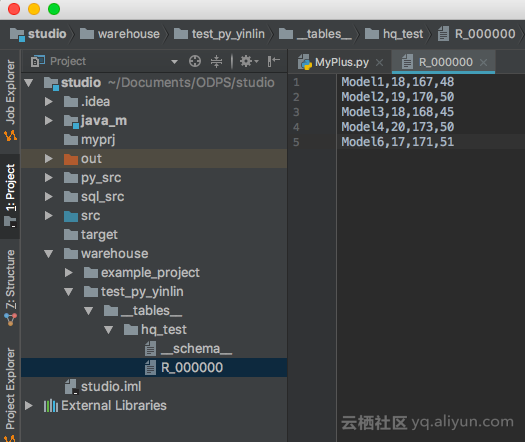
3. 然后本地运行框架会根据指定的列,获取data文件里指定列的数据,调用UDF本地运行。
注册发布Python UDF
1. 代码调试好后,将python脚本添加为MaxCompute的Resource:
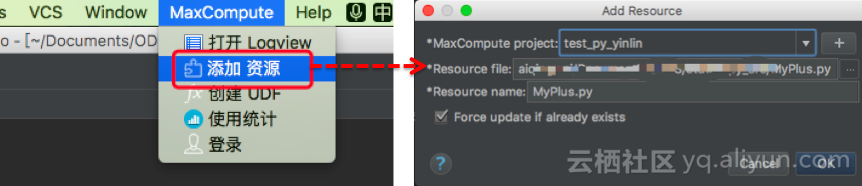
注意此处选择的MaxCompute project必须是已经申请开通python udf的project。
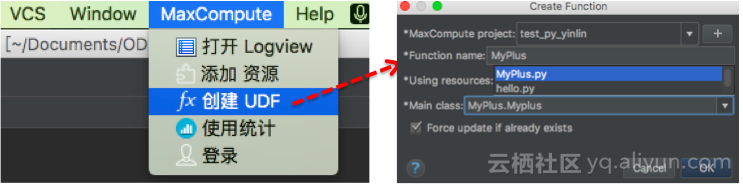
2. 注册python 函数:
3. 在sql脚本中编辑MaxCompute sql试用python udf:
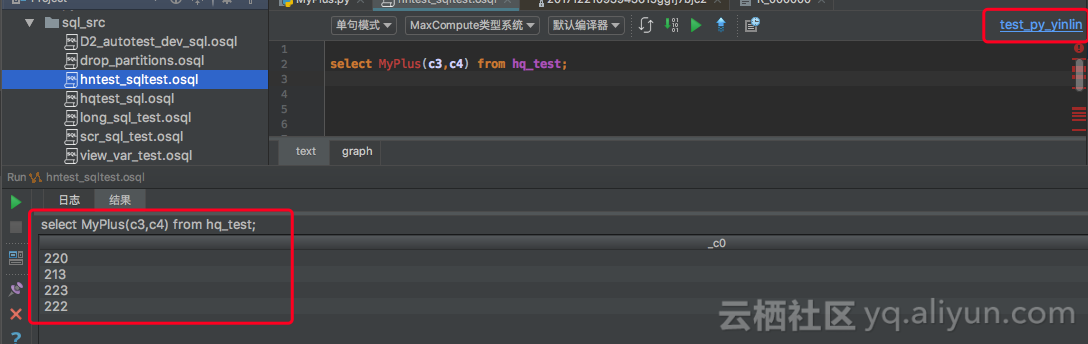
好了,一个简单完整的python UDF通过Studio开发实践分享完成。
原文:http://click.aliyun.com/m/40729/
前置条件
了解到,虽然功能发布,不过还在公测阶段,如果想要使用,还得申请开通:https://page.aliyun.com/form/odps_py/pc/index.htm。这里我就不介绍申请开通具体流程了。
环境准备
MaxCompute Studio支持Python UDF开发,前提需要安装python, pyodps和idea的python插件。
1. 安装Python:可以Google或者百度搜索下如何安装。
2. 安装pyodps:可以参考python sdk文档的安装步骤。即,在 Python 2.6 以上(包括 Python 3),系统安装 pip 后,只需运行下 pip install pyodps,PyODPS 的相关依赖便会自动安装。
3. Intellij IDEA中安装Python插件。搜索Python Community Edition插件并安装
4. 配置studio module对python的依赖。
File -> Project structure,添加python sdk:
File -> Project structure,添加python facets:
File -> Project structure,配置module依赖python facets:
开发Python UDF
环境都准备好后,既可在对应依赖的module里创建进行python udf开发。
新建python脚本
右键 new | MaxCompute Python,弹框里输入脚本名称,选择类型为python udf:
生成的模板已自动填充框架代码,只需要编写UDF的入参出参,以及函数逻辑:
本地调试
代码开发好后,可以在Studio中进行本地调试。Studio支持下载表的部分sample数据到本地运行,进行debug,步骤如下:
1. 右键python udf类,点击”运行”菜单,弹出run configuration对话框。UDF|UDAF|UDTF一般作用于select子句中表的某些列,此处需配置MaxCompute project,table和column(元数据来源于project explorer窗口和warehouse下的example项目):
2. 点击OK后,通过tunnel自动下载指定表的sample数据到本地warehouse目录(若之前已下载过,则不会再次重复下载,否则利用tunnel服务下载数据。默认下载100条,如需更多数据测试,可自行使用console的tunnel命令或者studio的表下载功能)。下载完成后,可以在warehouse目录看到下载的sample数据。这里用户也可以使用warehouse里的数据进行调试,具体可参考java udf开发中的关于本地运行的warehouse目录”部分)。
3. 然后本地运行框架会根据指定的列,获取data文件里指定列的数据,调用UDF本地运行。
注册发布Python UDF
1. 代码调试好后,将python脚本添加为MaxCompute的Resource:
注意此处选择的MaxCompute project必须是已经申请开通python udf的project。
2. 注册python 函数:
3. 在sql脚本中编辑MaxCompute sql试用python udf:
好了,一个简单完整的python UDF通过Studio开发实践分享完成。

相关文章推荐
- MaxCompute Studio使用心得系列4——可视化查看所有job并分析运行情况
- MaxCompute Studio提升UDF和MapReduce开发体验
- 使用 MaxCompute Studio 开发大数据应用
- MaxCompute Studio使用心得系列2——编译SQL脚本
- MaxCompute Studio使用心得系列1——本地数据上传下载
- 使用 MaxCompute Studio 开发大数据应用
- 使用 MaxCompute Studio 开发大数据应用
- MaxCompute Studio使用心得系列1——本地数据上传下载
- MaxCompute Studio使用心得系列3——可视化分析作业运行
- MaxCompute Studio提升UDF和MapReduce开发体验
- Oracle开发工具使用心得
- 从使用Python开发一个Socket示例说到开发者的思维和习惯问题
- 开发一个应用程序,使用 Python、NLTK 和机器学习对 RSS 提要进行分类
- 从使用Python开发一个Socket示例说到开发者的思维和习惯问题 推荐
- 这两天刚完成的一个任务,使用destoon,进行b2b网站开发
- Python开发环境Wing IDE使用手册之搜索工具
- python相关的开发及使用工具
- 从使用Python开发一个Socket示例说到开发者的思维和习惯问题
- Python:一个多功能的抓图工具开发(附源码)
- 使用Visual Studio.Net 2005开发Python扩展模块