机器学习实战-决策树
2018-01-22 13:27
274 查看
参考:http://blog.csdn.net/rujin_shi/article/details/78776996
前言
决策树(Decesion Tree)是一种基本的分类算法。它可以认为是if-then规则的集合,也可以认为是定义在特征空间与类空间上的条件概率分布。其主要优点就是模型具有可读性,分类速度块。学习时,利用训练数据,根据损失函数最小化的原则建立决策树模型。旨在构建一个与训练数据拟合很好,并且复杂度小的决策树。因为从可能的决策树中直接选取最优决策树是NP问题,现实中采用启发方法学习次优的决策树。总的来说,决策树就是找出每一列特征的最佳划分以及划分的先后顺序排列。
决策树学习算法包括3部分:特征选择、树的生成和树的剪枝。常用算法有ID3(本文采用)、C4.5和CART算法。
决策树的生成:通常使用信息增益最大,信息增益比最大,或基尼指数最小作为特征选择的准则。决策树的生成往往通过计算信息增益或其他指标,从根节点开始,递归地产生决策树。这相当于用信息增益或其他准则不断地选取局部最优 的特征,或将训练集分割为能够基本正确分类的子集。
决策树的剪枝:由于生成的决策树存在过拟合的问题,需要对它进行剪枝(考虑全局最优)。决策树的剪枝,往往从已生成的树上剪掉一些叶结点或叶结点以上的树,并将其父结点或根结点作为新的叶结点。
3.1 决策树的构造
创建分支的伪代码如下: 
3.1.1 香农熵
在可以评测哪个数据划分方式是最好的数据划分之前,我们必须学习如何计算信息增益。集合信息的度量方式成为香农熵或者简称为熵(entropy),这个名字来源于信息论之父克劳德·香农。如果看不明白什么是信息增益和熵,请不要着急,因为他们自诞生的那一天起,就注定会令世人十分费解。克劳德·香农写完信息论之后,约翰·冯·诺依曼建议使用”熵”
4000
这个术语,因为大家都不知道它是什么意思。
熵定义为信息的期望值。在信息论与概率统计中,熵是表示随机变量不确定性的度量。如果待分类的事务可能划分在多个分类之中,则符号xi的信息定义为
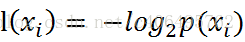
其中p(xi)是选择该分类的概率。有人可能会问,信息为啥这样定义啊?答曰:前辈得出的结论。这就跟1+1等于2一样,记住并且会用即可。上述式中的对数以2为底,也可以e为底(自然对数)。
通过上式,我们可以得到所有类别的信息。为了计算熵,我们需要计算所有类别所有可能值包含的信息期望值(数学期望),通过下面的公式得到:
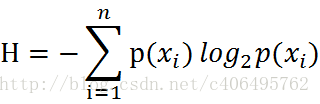
期中n是分类的数目。熵越大,随机变量的不确定性就越大。
当熵中的概率由数据估计(特别是最大似然估计)得到时,所对应的熵称为经验熵(empirical entropy)。什么叫由数据估计?比如有10个数据,一共有两个类别,A类和B类。其中有7个数据属于A类,则该A类的概率即为十分之七。其中有3个数据属于B类,则该B类的概率即为十分之三。浅显的解释就是,这概率是我们根据数据数出来的。我们定义贷款申请样本数据表中的数据为训练数据集D,则训练数据集D的经验熵为H(D),|D|表示其样本容量,及样本个数。设有K个类Ck,k = 1,2,3,···,K,|Ck|为属于类Ck的样本个数,这经验熵公式可以写为:
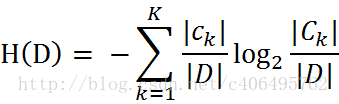
程序清单3-1:计算给定数据集的香农熵
#计算给定数据集的香农熵
from math import log
def calcShannonEnt(dataSet):
numEntries=len(dataSet)#实例总数
labelCounts={}#判断每个类标签对应数据集的出现次数,用字典存储
for featVec in dataSet:
currentLabel=featVec[-1]
#labelCounts[currentLabel]=labelCounts.get(currentLabel,0)+1等同
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel]=0
labelCounts[currentLabel]+=1
shannonEnt=0.0#香农熵
for key in labelCounts:
prob=float(labelCounts[key])/numEntries#计算每个特征的概率
shannonEnt-=prob*log(prob,2)
return shannonEntdef createDataSet(): dataSet=[[1,1,'yes'], [1,1,'yes'], [1,0,'no'], [0,1,'no'], [0,1,'no']] labels=['no surfacing','flippers'] return dataSet,labels
myData,labels=createDataSet() print(len(myData[0])) x=calcShannonEnt(myData) print(x)
输出结果:
3
0.9709505944546686
3.1.2 划分数据集
程序清单3-2 按照给定特征划分数据集def splitDataSet(dataSet,axis,value): #数据集,特征下标,特征值 分类特定特征的数据集 retDataSet=[]#抽取满足特征值之后的数据集 for featVec in dataSet: if featVec[axis]==value: reducedfeatVec=featVec[:axis]#该特征使用过之后,抛弃 reducedfeatVec.extend(featVec[axis+1:]) retDataSet.append(reducedfeatVec) return retDataSet
data1=splitDataSet(myData,0,1)
data0=splitDataSet(myData,0,0)
print("取第一个特征值为1的数据集:",data1)
print("取第一个特征值为0的数据集:",data0)输出结果:
取第一个特征值为1的数据集: [[1, 'yes'], [1, 'yes'], [0, 'no']]
取第一个特征值为0的数据集: [[1, 'no'], [1, 'no']]
这里注意append()和extend()的区别a=[4,5,6],b=[1,2,3]
a.append(b)结果是[4,5,6[1,2,3]],a.expend(b)结果是[4,5,6,1,2,3],
有了划分数据集和计算香农熵的算法,接下来就是设计如何划分数据集合了。
方法是对每个特征进行计算,找到信息增益最大的,就是最优的
程序清单3-3 选择最好的数据集划分
def choose_bestFeature_tosplit(dataset):
numfeature=len(dataset[0])-1#特征总数,减去最后一个标签
baseEntropy=calcShannonEnt(dataset)#初始熵
bestInfoGain=0.0 #最大信息增益
bestFeature=-1 #最优特征
for i in range(numfeature):
featlist=[example[i] for example in dataset] #获取第i个特征的所有特征值,列表推到
uniqueVals=set(featlist) #将重复特征去除
newEntropy=0.0
for value in uniqueVals:
subDataSet=splitDataSet(dataset,i,value)
prob=(len(subDataSet)/float(len(dataset)))
# print("当前分类出现的概率:",prob)
newEntropy+=prob*calcShannonEnt(subDataSet)
inforGain=baseEntropy-newEntropy
# print("当前最好的信息增益是:",inforGain)
if (inforGain>bestInfoGain):
bestInfoGain=inforGain
bestFeature=i
return bestFeature#v3.x 以后,“/”运算符被命名为“真除”,
#不再依据操作数类型选择返回值类型,保证计算结果数值上的精度是第一位的。
#所以,无须再把操作数转变成浮点型,以保证运算结果不被截断小数部分。
程序清单3-4 构建决策树
在基于最好的属性值划分数据集后(第一次),数据将被向下传递到树分支的下一个节点,在这个节点上,我们再次划分数据。因此我们可以采用递归的原则处理数据集。
递归结束的条件是:
1.每个分支下的所有实例都具有相同的分类。
怎么判断具有相同的分类呢?
首先获得所有的类标签,计算列表长度,然后计算第一类标签的数量,若两者相同,证明标签类只有一类
2.数据集已经处理了所有属性,但是类标签依然不唯一,此时我们需要使用投票的方式决定该叶子节点的分类。
def majorityCnt(classList):#处理完所有特征属性,标签类依然不唯一,采用多数表决,类似KNN中classy0
classCount={}
for vote in classList:
if vote not in classCount.keys(): #计算每个特征值的出现次数,选择次数最多的
classCount[vote]=0
classCount[vote]+=1
sortedclassCount=sorted(classCount.items(),Key=operator.itemgetter(1),reverse=True)#根据键值排序
return sortedclassCount[0][0]def createTree(dataSet,labels):
classlist=[example[-1] for example in dataSet]#返回的是yes和no
if classlist.count(classlist[0])==len(classlist):#当classlist中所有元素都相同
return classlist[0]
if len(dataSet[0])==1:#所有特征都用完了,采用多数表决法
return majorityCnt(classlist)
bestFeat=choose_bestFeature_tosplit(dataSet)
bestFeatLabel=labels[bestFeat]
myTree={bestFeatLabel:{}}
del(labels[bestFeat])
featValues=[example[bestFeat] for example in dataSet]#得到该划分特征属性的所有特征值
uniqueValues=set(featValues)
for value in uniqueValues:
subLabels=labels[:] #防止对原来的labels改sublabels=labels只是对同一列表起别名
#print(bestFeatLabel)
myTree[bestFeatLabel][value]=createTree(splitDataSet(dataSet,bestFeat,value),subLabels)#递归
return myTree#帮助理解 #dics={'a':{0:'q',1:'w',2:'e'}}
#dics['a']
#{0: 'q', 1: 'w', 2: 'e'}
#dics['a'][2] 'e'bestfeature=choose_bestFeature_tosplit(myData) print(bestfeature) mytree=createTree(myData,labels) print(mytree)
输出:
{'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}}
到这里,树就算是构建完毕了。但是这样的树并不直观,因此要将它图形化显示出来,这里就用到了matplotlib。下一节将继续。

相关文章推荐
- 机器学习实战-决策树
- 机器学习实战之决策树
- 机器学习实战- 第三章 决策树-学习笔记
- 机器学习实战-决策树
- 机器学习实战之决策树ID3算法
- 机器学习实战之决策树(2)---选择最好的特征来划分数据集
- 机器学习实战之决策树(一)
- 机器学习实战笔记——微软小冰的读心术与决策树
- 机器学习实战—决策树(python3+spyder)
- 机器学习实战—ch03 .决策树(ID3算法)
- 机器学习实战—决策树(二)
- 机器学习实战-决策树
- 机器学习实战学习笔记(二):决策树
- 机器学习实战 - 读书笔记(03) - 决策树
- 读书笔记:机器学习实战【第3章 决策树】
- 机器学习实战笔记-决策树
- 机器学习实战 (2)决策树 (二) 决策树ID3算法的优缺点
- 机器学习实战之决策树(一)
- 机器学习实战--决策树分类
- 机器学习实战-决策树ID3-python代码