.net和SQL面试题
2018-01-21 14:15
204 查看
1.用户访问mvc的过程
用户在请求之后首先会进入管道,然后在管道的第七个事件(Post Resolve Request Chace)中执行
MvcHandler进行路由创建,并判断路由的配置(
UrlRoutingModel类),之后在第八个事件根据用户的请求路径(url)创建对应的页面,然后进入对应页面的控制器,执行了这个控制器中的代码后,最终返回控制器对应的
ActionResult
2.WebApi 作用
webapi是一种比较像restful风格的轻量级框架,它提供了比较完整的http请求支持,主要用来做开放API,并且还可以对前端和后台进行解耦,让前端更加灵活3.数据库碎片是什么
碎片就是在访问一个表时,造成了比正常情况更多的磁盘IO操作或更长的磁盘IO操作碎片分为逻辑/物理磁盘碎片和索引碎片
逻辑碎片
逻辑碎片是在文件系统里数据库文件的碎片产生原因和造成的后果
数据库和其他文件放在一个磁盘,导致系统没法给数据库文件分配连续的空间,从而产生。这样会造成磁头在读取数据库文件时需要来回移动
数据库文件频繁的以小块增长大小,也会造成逻辑碎片。所以创建数据库文件时估量好大小,分配足够的空间,避免频繁的增长 或者 指定数据库以大块增长不是频繁的小块增长
索引碎片
索引碎片如果比较高的话,优化器将不能最优的使用索引索引碎片又分为 内部碎片 和 外部碎片
内部碎片
内部碎片是根据每个索引页的饱和度来衡量的(页密度),如果一个索引页能100%存满,那么它就不存在内部碎片,换而言之就是说,内部碎片在索引页的可用空间中产生,一般由insert,delete,update等DML(data manipulation language)语句操作造成
每个页都有一定的大小用来保存数据,但是并不能保证每个页都可以占满,例如一个页的大小为750,一条数据大小为100,那么750/100,这个页就只可以存7条数据,剩下的50空间,因为不足以容纳一条数据,所以只能空着,然后开辟一个新的页去继续储存数据
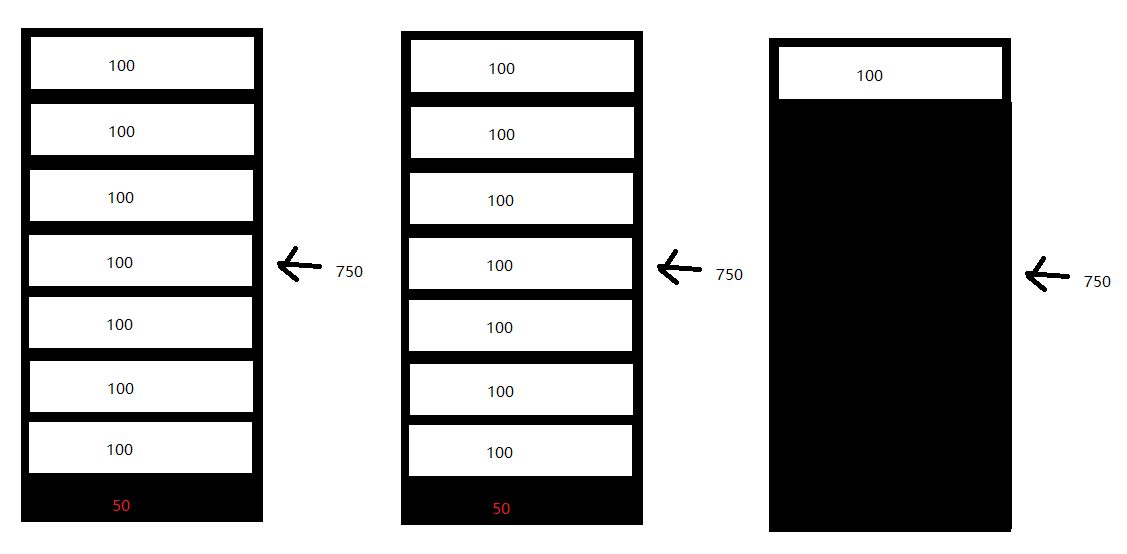
然后我们随便删除一半的数据就会变成这样

可以看到有大范围的空位置,留下的数据有7条,完全可以通过一个页来保存,但是实际我们用的三个页。
这就会造成查询时,原本读取一个页就可以,但是现在要读取三个页,增加了IO操作。
内部碎片还会让缓存和数据库文件占用更大的空间,用来存储额外的页
外部碎片
外部碎片是页的逻辑顺序和物理顺序不一致造成的如果像下图这样顺序一致的数据的话,就不会有外部碎片产生

不过我们可以看到第一页中少了一个5,现在我们
4000
要向里面插入5,这时因为第一页空间已经占满了,不能再放数据,就只能把第一页拆开,一半数据在第一页,一半数据在新的页(第三页)
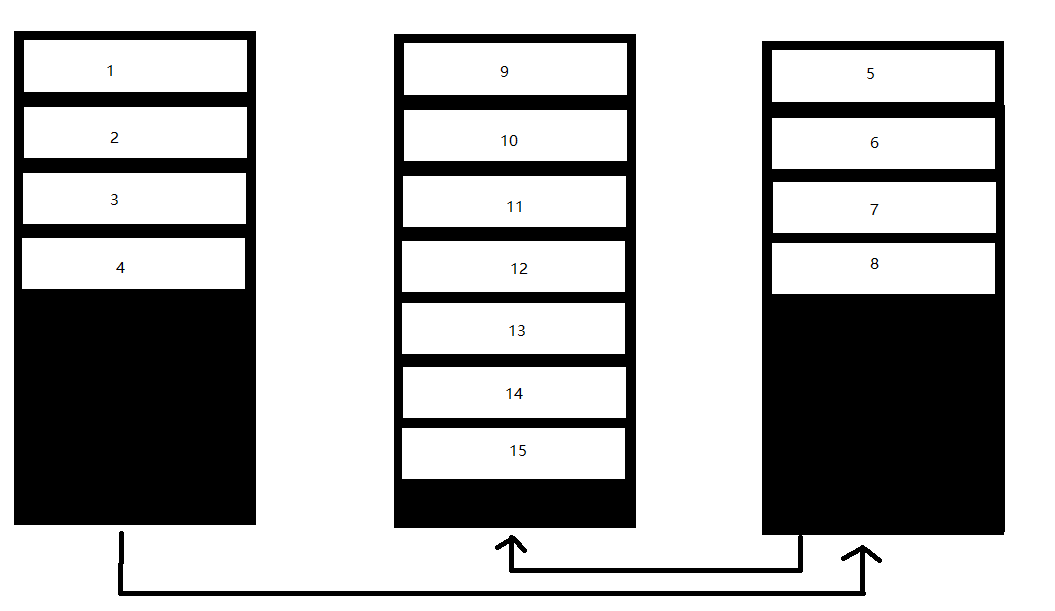
如果是使用where之类的有详细条件的查询或无序查询时,外部碎片不会造成影响,但是在进行有序查询时,磁头就需要在不同页中来回跳,从而降低了性能
4.如何解决碎片
1.删除索引进行重建
这是对整理索引最有效的方式,但并不好用,因为在删除期间,索引不可用,会导致阻塞的发生,而且删除聚集索引时会导致非聚集索引重建两次(删除时一次,创建时一次)2.使用DROP_EXISTING语句重建索引
因为这个语句是原子性的,所以不会导致非聚集索引重建两次,但依然没有解决阻塞的发生3.使用alter index rebuild语句重建索引
使用这个语句同样也重建索引,但是通过动态创建索引而不需要卸载并重建索引,是优于前两种方法的,但依旧会造成堵塞,可以通过online关键字减少锁,但会造成重建时间加长4.使用alter index reorganize
这种方式不会重建索引,也不会生成新的页,仅仅是整理,当遇到加锁的页时跳过,所以不会造成阻塞。但同时,整理效果会差于前三种5.使用填充因子
使用上面的方法的确可以解决碎片,但是麻烦比较多,尤其是在数据非常多的时候填充因子的作用是设置一个页的使用程度,例如填充因子是0 (0-100是表示一个概念) 表示页的100%的空间都可以使用,所以会造成内部碎片时提到的情况,剩余空间不足,只能再开辟新页
那么如果我们把填充音质设置为80%,那么就会预留出20%的空间为插入数据或更新数据时使用,从而减少分页的次数
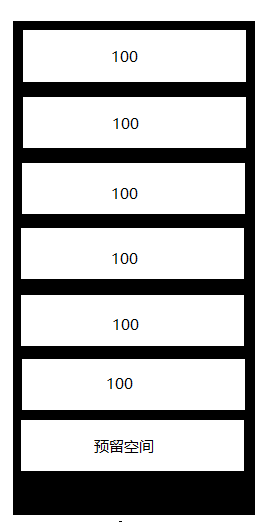
但是这样的话,原本一个页可以存储7条数据,现在却变成了6条,自然页的数量就会增加,要读取的页数变多,所以查询效率会降低,数据库文件占用的空间也会变大
所以使用填充因子时要根据读和写的情况
如果读的次数大幅度超过写的次数,那么就不要使用填充因子,直接让页100%用于储存
如果写大于读,那么填充因子可以设置50%-70%
如果读和写差不多,那么填充因子可以设置80%-90%
当然具体数值还是要根据实际情况判断
6.游标的作用
游标是一种能从包括多条数据的结果集中每次提取出一条数据的机制,游标充当指针的作用,尽管游标能遍历结果中的所有行,但是它一次只能指向一行。游标就是一种临时的数据库对象,最常见的用途是保存查询数据,以便之后使用,如果在处理过程中需要多次使用结果集,创建一个游标重复使用,要比重复查询数据库要快的多
但游标就相当于把存在磁盘上的一部分数据拿到内存在存储,所以在数据量很大时不建议用游标
游标的声明
cursor c is select * from table
7.什么是大小端
内存是以字节为单位的,如果像char类型一样长度刚好1字节的话,并不会涉及到大小端模式,但是有很多类型是高于一字节的,例如
short类型是2字节,
int类型是4字节,这就存在着一个数据的各个字节 的存放顺序问题,这个存放顺序就是大小端模式
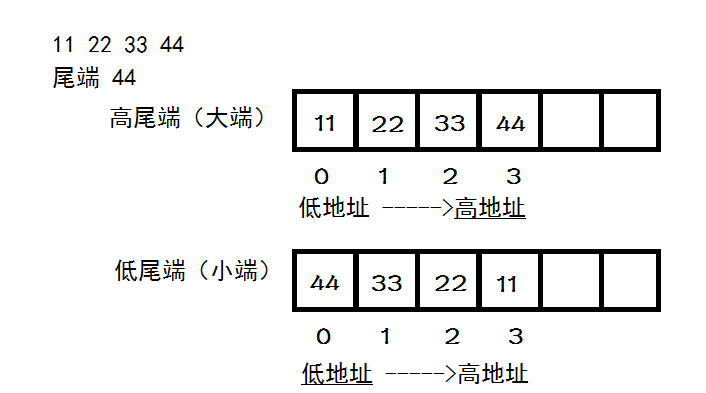
大端和小端,也可以称为高尾端和低尾端
大端模式 : 指的是将数据从高到低的存储,即高字节的数据存放在低地址中,低字节的数据存放在高地址中
小端模式 : 指的是将数据从低到高的存储,即低字节的数据存放在低地址中,高字节的数据存放在高地址中
内存的高低地址
内存的地址对应十六进制的数值,值大的为高地址,值小的为低地址
为什么要分成大小端两种模式 ? 两者各自的优势
大端模式 : 因为高位存在前面,所以便于比较数值的大小和判断数值的正负 (比较大小从高位开始比)
小端模式 : 因为低位存在前面,所以便于数值的运算 (运算时从低位开始算)
数值的高低位
比如86这个数值,8是十位数,他就是高位,6是十位,则他是低位
整数类型是小端模式
inter处理器是小端模式
TCP/IP是大端模式
局部变量是先定义高地址,后定义低地址
类,结构,数组是先定义低地址,后定义高地址
8.AJAX的优缺点
Ajax的原理相当于在用户和服务器之间加了一个中间层,使用户的操作与服务器的响应异步化。并不是所有的请求都会提交给服务器,像一些数据验证或者数据处理等都会由Ajax引擎自己来做,只有需要从数据库读取数据时才会像服务器提交请求
优点
1.无刷新更新数据
2.异步的和服务器通信
3.前后端负载平衡,将一些服务器的工作移到了客户端处理,减轻了服务器的压力
4.可以被广泛支持
5.数据和页面分离,利于分工合作
6.减少服务器的负担,因为Ajax的根本理念是 “按需取数据” ,所以减少了很多冗余请求和对服务器的负担
缺点
1.不能使用浏览器的后退和历史记录功能
2.安全有一些问题
3.对搜索引擎支持比较弱
4.破坏了程序的异常处理机制 (不会报错)
5.不能很好的支持移动设备,手机的浏览器不支持ajax
6.增加了客户端的代码,造成客户端过肥
9.=、==、===之间的区别
= 赋值运算符 赋值时使用== 关系运算符 判断两个值是否相同,但是这个运算符不考虑类型,只判断值是否相同
=== 关系运算符 判断两个值是否完全相同,这个运算符会考虑类型,使其为绝对相同
10.写出一条SQL语句,取出表A中31到40的记录(注意ID可能是不连续的)
select top 10 * from a where id not in (select top 30 id from a order by id) order by id
筛掉前三十条数据,然后取之后的十条,即31到40
11.项目分为几个阶段
需求分析 - 概要设计 - 详细设计 - 编码 - 测试 - 软件交付 - 验收 - 维护12.冒泡排序
//冒泡排序本质:N个数,需要N-1趟,每趟需要比较N-i次(i是指第i趟)如10个数需要比较9+8+7+6+5+4+3+2+1=45次
//冒泡排序每一趟排序把最大的放在最右边。
for (int i = 0; i < arr.Length - 1; i++) //总共扫描n-1趟
{
judge = true;
for (int j = 0; j < arr.Length - 1 - i; j++)
{
if (arr[j] > arr[j + 1])
{
judge = false;
//a=a+b;
//b=a-b;
//a=a-b;
arr[j] = arr[j] + arr[j + 1];
arr[j + 1] = arr[j] - arr[j + 1];
arr[j] = arr[j] - arr[j + 1];
}
}
if (judge)
break;
}int[] a={2 ,1, 5, 3, 0 ,8, 9 ,4 ,6 ,7};
public void bubbleSort(int[] list) {
int temp = 0; // 用来交换的临时数
//总共扫描n-1趟 ,比如a的length是10,总共扫描9趟,但是第一趟是程序中i=0开始的,所以的第九趟其实是i=8,也就是i<9
for (int i = 0; i < list.length - 1; i++) {
for (int j =0 ; j <list.length - 1-i; j++) {
// 比较相邻的元素,如果前面的数大于后面的数,则交换
if (list[j ] > list[j+1]) {
temp = list[j + 1];
list[j + 1] = list[j];
list[j] = temp;
}
}
System.out.format("第 %d 趟:\t", i);
printAll(list);
}
}运行结果:
第 0 趟: 第 1 趟: 第 2 趟: 第 3 趟: 第 4 趟: 第 5 趟:
13.C#和.net的区别
.net是微软为了开发应用程序而创建的一个框架,其本身包括着一个庞大的类库(.net framework),可以使用一些语言(如C#)通过面向对象(OOP)的编程思想调用其中的代码而C#是为了调用.net类库创建的一个语言,除了C#以外,还有其他的语言可以调用.net类库,如VB,J#等
14.public等四个访问修饰符的作用
private 私有 被此修饰的成员只能在本类中被访问,类中的成员,默认为privateprotected 保护 被此修饰的成员只能在本类和子类中被访问
internal 内部 被此修饰的成员只能在本程序集中被访问
public 公开 被此修饰的成员没有限制,任何地方都可以访问

相关文章推荐
- .net 常见面试题(包含c#\sql\ado.net)
- .NET高级工程师面试题之SQL篇
- 一些.net,sql的面试题2(附答案)
- 一些.net,sql的面试题1(附个人答案)
- .NET面试题解析(11)-SQL语言基础及数据库基本原理
- 各公司技术面试题汇总(Java,.NET,C,C++,SQL,PHP)不断更新中……
- .NET高级工程师面试题之SQL篇
- 几道经典的SQL面试题
- .NET数据库编程求索之路--3.使用ADO.NET实现(SQL语句篇)(2)
- .net面试题大全(有答案)
- 步步为营VS 2008 + .NET 3.5(9) - DLINQ(LINQ to SQL)之执行SQL语句的添加、查询、更新和删除
- 今天面试笔试了一道SQL面试题,狠简单
- .NET基础面试题整理
- .net 收集的面试题
- 一个SQL存储过程面试题(比较简单)
- .net面试题大全(有答案)
- SQL面试题
- Oracle的一些经典SQL面试题
- 常用.net面试题
- 在.net执行sql脚本的简单实现