Log4j 2.x的体系架构详解
2018-01-18 21:29
363 查看
本译文主要内容分为以下两部分:
1. Log4j 2.x的层次结构
2. Log4j 2.x的主要组件详解
更多有关Log4j的配置详解及例子详见Log4j 2.x 配置详解及详细配置例子
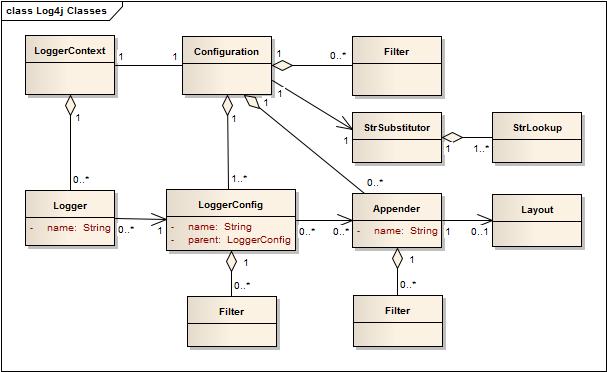
使用Log4j 2 API的应用程序将向LogManager请求具有特定名称的Logger。LogManager将找到相应的LoggerContext,然后从中获取Logger。如果必须创建Logger,则它将与LoggerConfig相关联,该LoggerConfig包含 a)与Logger相同的名称,b)父包的名称,或者c)根LoggerConfig。
LoggerConfig对象是从配置中的Logger声明中创建的。LoggerConfig与实际传递LogEvent的Appender相关联。
在Log4j 1.x中,记录器层次结构是通过记录器之间的关系来维护的。在Log4j 2中,这种关系不再存在。相反,这种层次结构通过LoggerConfig对象之间的关系来维持。
Loggers 和LoggerConfigs是已命名的实体。Logger名称区分大小写,它们遵循分层命名规则:
命名层次结构
如果一个LoggerConfig的名字+‘.’是后代名称的前缀, 则称该LoggerConfig是另一个LoggerConfig 的祖先。
如果一个LoggerConfig和后代LoggerConfig之间没有祖先,此LoggerConfig被称为是子 LoggerConfig 的父级。
例如,名为
根LoggerConfig位于LoggerConfig层次结构的顶部。作为唯一一个例外,它始终存在,并且是每个层次的一部分。直接链接到根LoggerConfig的Logger可以如下获得:
或者
所有其他的Logger可以使用 LogManager.getLogger 静态方法通过传递所需记录器的名称来检索。有关Logging API的更多信息可以在Log4j 2 API中找到。
Log4j环境的配置通常在应用程序初始化时完成。首选的方法是读取配置文件。这在配置中讨论。
Log4j可以很容易地通过软件组件来命名Logger。这可以通过在每个类中实例化一个Logger来完成,Logger名称等于该类的完全限定名称。这是定义Logger的有用和直接的方法。由于日志输出带有生成日志记录器的名称,因此该命名策略可以轻松识别日志消息的来源。然而,这只是一种可能的,尽管是通用的命名记录器的策略。Log4j不限制Logger命名规则。开发人员可以根据需要自由地命名Logger。
由于在拥有类之后命名“记录器”是一种常见习惯用法,所以提供了便捷方法 LogManager.getLogger()来自动使用调用类的完全限定类名作为记录器名称。
尽管如此,以类的名称来命名Logger似乎是目前已知的最好的策略。
Log4j 1.x 和 Logback 都有“级别继承”的概念。在Log4j 2中,Logger和LoggerConfig是两个不同的对象,所以这个概念的实现方式有所不同。每个Logger引用相应的LoggerConfig,这个LoggerConfig又可以引用它的父代,从而达到相同的效果。
以下是五个具有各种指定级别值的表格以及与每个Logger关联的结果级别。请注意,在所有这些情况下,如果未配置根LoggerConfig,则将为其分配默认级别。
在上述示例1中,只有根Logger被配置并且具有日志级别。所有其他的Logger引用根LoggerConfig并使用它的Level。
在上述示例2中,所有Logger都有一个已配置的LoggerConfig并从中获取它们的Level。
在上述示例3中,Logger root、X 和 X.Y.Z 都有一个名称相同的LoggerConfig。Logger X.Y 没有配置的具有匹配名称的LoggerConfig,因此使用LoggerConfig X的配置, 因为其名称与Logger的前缀名称具有最长匹配。
在上述示例4中,Logger root和X 和都有一个名称相同的LoggerConfig。Logger X.Y 和X.Y.Z没有配置的具有匹配名称的LoggerConfig,因此使用LoggerConfig X的配置, 因为其名称与Logger的前缀名称具有最长匹配。
在上述示例5中,Logger root、X 和 X.Y 都有一个名称相同的LoggerConfig。Logger X.YZ 没有配置的具有匹配名称的LoggerConfig,因此使用LoggerConfig X的配置, 因为其名称与Logger的前缀名称具有最长匹配。它不与LoggerConfig X.Y关联, 因为令牌必须完全匹配
在上述示例6中,LoggerConfig X.Y没有配置级别,所以它从LoggerConfig X继承它的级别。Logger X.Y.Z使用LoggerConfig X.Y,因为它没有名称完全匹配的LoggerConfig。它也从LoggerConfig X继承它的日志级别。
注:一个事件可能被一个过滤器接受,但事件仍然可能不会被记录。这种情况发生在事件被pre-LoggerConfig过滤器接受,但是被LoggerConfig过滤器拒绝,或被所有Appender拒绝。
可以通过调用当前配置的addLoggerAppender方法将Appender添加到Logger中 。如果与Logger名称匹配的LoggerConfig不存在,则将创建一个LoggerConfig,将Appender附加到该LoggerConfig,然后所有Logger被通知去更新其LoggerConfig引用。
对于给定的logger,每个启用的记录请求将被转发给Logger的LoggerConfig中的所有appender以及LoggerConfig父级的Appender。 换句话说,Appender是从LoggerConfig层次继承的。例如,如果将控制台appender添加到根日志记录器,则所有启用的日志记录请求将至少在控制台上打印。如果此时一个file appender添加到名为C的LoggerConfig,那启用日志请求时C和C的子级将在一个文件和在控制台上打印。可以重写此默认行为,通过在配置文件的Logger声明中设置
以下总结了Appender可加性的规则。
Appender的可加性
Logger L的日志语句的输出将传递到LoggerConfig L 自身 和 祖先中关联的所有Appender。这就是“appender additivity”的意思。
但是,如果与Logger L关联的LoggerConfig祖先 P,将其可加性标志设为
记录器默认情况下将其可加性标志设置为
例如,具有转换模式“%r [%t]%-5p%c - %m%n”的PatternLayout将输出类似于:
第一个字段是程序启动以来经过的毫秒数。第二个字段是处理日志请求的线程。第三个字段是日志语句的级别。第四个字段是与日志请求关联的logger的名称。“ - ”后面的文字是该陈述的讯息。
Log4j 为各种用例(如JSON,XML,HTML和Syslog(包括新的RFC 5424版本))提供了许多不同的布局。其他appender(如数据库连接器)将填充指定的字段而不是特定的文本布局。
同样重要的是,log4j将根据用户指定的标准呈现日志消息的内容。例如,如果您经常需要记录当前项目中使用的对象类型Oranges,则可以创建一个接受Orange实例的OrangeMessage类并将其传递给Log4j,以便在将Orange对象格式化为合适的字节数组时需要。
原文链接:Architecture
译文链接:http://blog.csdn.net/why_still_confused/article/details/79097136
版权声明:本文为博主原创翻译文章,若要转载请注明文章出处
1. Log4j 2.x的层次结构
2. Log4j 2.x的主要组件详解
更多有关Log4j的配置详解及例子详见Log4j 2.x 配置详解及详细配置例子
主要组件
Log4j使用下图中显示的类。使用Log4j 2 API的应用程序将向LogManager请求具有特定名称的Logger。LogManager将找到相应的LoggerContext,然后从中获取Logger。如果必须创建Logger,则它将与LoggerConfig相关联,该LoggerConfig包含 a)与Logger相同的名称,b)父包的名称,或者c)根LoggerConfig。
LoggerConfig对象是从配置中的Logger声明中创建的。LoggerConfig与实际传递LogEvent的Appender相关联。
Logger层次结构
任何日志API优于朴素的System.out.println的优势在于它能够禁用某些日志语句,同时允许其他语句无阻碍地进行输出。这种性能基于记录空间,即所有可能的记录语句的空间,按照一些开发人员选择的标准进行分类。
在Log4j 1.x中,记录器层次结构是通过记录器之间的关系来维护的。在Log4j 2中,这种关系不再存在。相反,这种层次结构通过LoggerConfig对象之间的关系来维持。
Loggers 和LoggerConfigs是已命名的实体。Logger名称区分大小写,它们遵循分层命名规则:
命名层次结构
如果一个LoggerConfig的名字+‘.’是后代名称的前缀, 则称该LoggerConfig是另一个LoggerConfig 的祖先。
如果一个LoggerConfig和后代LoggerConfig之间没有祖先,此LoggerConfig被称为是子 LoggerConfig 的父级。
例如,名为
"com.foo"的LoggerConfig是名为
"com.foo.Bar"的LoggerConfig的父级。类似地,
"java"是
"java.util"的父级和
"java.util.Vector"的祖先。这个命名方案应该是大多数开发人员都熟悉的。
根LoggerConfig位于LoggerConfig层次结构的顶部。作为唯一一个例外,它始终存在,并且是每个层次的一部分。直接链接到根LoggerConfig的Logger可以如下获得:
Logger logger = LogManager.getLogger(LogManager.ROOT_LOGGER_NAME);
或者
Logger logger = LogManager.getRootLogger();
所有其他的Logger可以使用 LogManager.getLogger 静态方法通过传递所需记录器的名称来检索。有关Logging API的更多信息可以在Log4j 2 API中找到。
LoggerContext
LoggerContext 在记录系统里充当锚点的作用。但根据具体情况,应用程序中可能会有多个活动的LoggerContext。LoggerContext的更多细节在Log Separtion部分。配置
每个LoggerContext都有一个活动的 Configuration。该配置包含所有Appender,覆盖上下文的Filter,LoggerConfig,并包含对StrSubstitutor的引用。在重新配置期间,两个配置对象将同时存在。一旦所有Logger重定向到新的配置,旧的配置将被停止并丢弃。Logger
如上所述,Logger是通过调用LogManager.getLogger创建的 。Logger本身不执行直接操作。它只是一个名字,并与一个LoggerConfig相关联。它扩展了 AbstractLogger 并实现了所需的方法。如果配置被修改,Logger可能会与不同的LoggerConfig关联,从而导致其行为被修改。检索Logger
使用相同名称去调用LogManager.getLogger方法将始终返回对完全相同的Logger对象的引用。如:Logger x = LogManager.getLogger("wombat");
Logger y = LogManager.getLogger("wombat");x和
y指的是完全相同的Logger对象。
Log4j环境的配置通常在应用程序初始化时完成。首选的方法是读取配置文件。这在配置中讨论。
Log4j可以很容易地通过软件组件来命名Logger。这可以通过在每个类中实例化一个Logger来完成,Logger名称等于该类的完全限定名称。这是定义Logger的有用和直接的方法。由于日志输出带有生成日志记录器的名称,因此该命名策略可以轻松识别日志消息的来源。然而,这只是一种可能的,尽管是通用的命名记录器的策略。Log4j不限制Logger命名规则。开发人员可以根据需要自由地命名Logger。
由于在拥有类之后命名“记录器”是一种常见习惯用法,所以提供了便捷方法 LogManager.getLogger()来自动使用调用类的完全限定类名作为记录器名称。
尽管如此,以类的名称来命名Logger似乎是目前已知的最好的策略。
LoggerConfig
LoggerConfig 对象是在日志记录配置中声明Logger时创建的。LoggerConfig包含一组过滤器,任何LogEvent必须经过过滤后再传递给Appender。它还包含一组Appender(应用于处理事件)的引用。日志级别
LoggerConfig将被分配一个日志级别。内置级别包括TRACE,DEBUG,INFO,WARN,ERROR和FATAL。Log4j 2还支持自定义日志级别。获得更多粒度的另一个机制是使用标记。Log4j 1.x 和 Logback 都有“级别继承”的概念。在Log4j 2中,Logger和LoggerConfig是两个不同的对象,所以这个概念的实现方式有所不同。每个Logger引用相应的LoggerConfig,这个LoggerConfig又可以引用它的父代,从而达到相同的效果。
以下是五个具有各种指定级别值的表格以及与每个Logger关联的结果级别。请注意,在所有这些情况下,如果未配置根LoggerConfig,则将为其分配默认级别。
| Logger Name | Assigned LoggerConfig | LoggerCf Level | Logger Level |
|---|---|---|---|
| root | root | DEBUG | DEBUG |
| X | root | DEBUG | DEBUG |
| X.Y | root | DEBUG | DEBUG |
| X.Y.Z | root | DEBUG | DEBUG |
| Logger Name | Assigned LoggerConfig | LoggerCf Level | Logger Level |
|---|---|---|---|
| root | root | DEBUG | DEBUG |
| X | X | ERROR | ERROR |
| X.Y | X.Y | INFO | INFO |
| X.Y.Z | X.Y.Z | WARN | WARN |
| Logger Name | Assigned LoggerConfig | LoggerCf Level | Logger Level |
|---|---|---|---|
| root | root | DEBUG | DEBUG |
| X | X | ERROR | ERROR |
| X.Y | X | ERROR | ERROR |
| X.Y.Z | X.Y.Z | WARN | WARN |
| Logger Name | Assigned LoggerConfig | LoggerCf Level | Logger Level |
|---|---|---|---|
| root | root | DEBUG | DEBUG |
| X | X | ERROR | ERROR |
| X.Y | X | ERROR | ERROR |
| X.Y.Z | X | ERROR | ERROR |
| Logger Name | Assigned LoggerConfig | LoggerCf Level | Logger Level |
|---|---|---|---|
| root | root | DEBUG | DEBUG |
| X | X | ERROR | ERROR |
| X.Y | X.Y | INFO | INFO |
| X.YZ | X | ERROR | ERROR |
| Logger Name | Assigned LoggerConfig | LoggerCf Level | Logger Level |
|---|---|---|---|
| root | root | DEBUG | DEBUG |
| X | X | ERROR | ERROR |
| X.Y | X.Y | ERROR | |
| X.Y.Z | X.Y | ERROR |
级别过滤原理
下表说明了级别过滤的工作原理。在表中,垂直标题显示LogEvent的级别,而水平标题显示与相应的LoggerConfig关联的级别。交叉点标识是否允许LogEvent进行进一步处理(YES)或丢弃(NO)。| Event Level | LoggerConfig Level | ||||||
| TRACE | DEBUG | INFO | WARN | ERROR | FATAL | OFF | |
| ALL | YES | YES | YES | YES | YES | YES | NO |
| TRACE | YES | NO | NO | NO | NO | NO | NO |
| DEBUG | YES | YES | NO | NO | NO | NO | NO |
| INFO | YES | YES | YES | NO | NO | NO | NO |
| WARN | YES | YES | YES | YES | NO | NO | NO |
| ERROR | YES | YES | YES | YES | YES | NO | NO |
| FATAL | YES | YES | YES | YES | YES | YES | NO |
| OFF | NO | NO | NO | NO | NO | NO | NO |
Filter
除了上述的自动日志级别过滤之外,Log4j还提供过滤器,可以在控制权传递给任何LoggerConfig之前应用;或在控制权传递给LoggerConfig之后但在调用任何Appender之前应用;或在控制权传递给LoggerConfig之后,但在调用特定的Appender之前应用;以及给每个Appender添加过滤。以与防火墙过滤器非常相似的方式,每个过滤器可以返回三个结果之一:Accept,
Deny或
Neutral。
Accept的响应意味着不应该调用其他过滤器,并且事件将被处理。
Deny的回应意味着事件应该立即被忽略,控制权应该返回给调用者。
Neutral的响应表示该事件应该传递给其他过滤器。如果没有其他过滤器,事件将被处理。
注:一个事件可能被一个过滤器接受,但事件仍然可能不会被记录。这种情况发生在事件被pre-LoggerConfig过滤器接受,但是被LoggerConfig过滤器拒绝,或被所有Appender拒绝。
Appender
根据logger选择性地启用或禁用记录请求的能力只是Log4j的其中一个作用。Log4j允许记录请求打印到多个目的地。在Log4j中,输出目标被称为 Appender。目前,控制台,文件,远程套接字服务器,Apache Flume,JMS,远程UNIX Syslog守护程序以及各种数据库API都有其对应的appender。更多详细信息,请参阅Appender部分 。一个Logger可以连接多个Appender。可以通过调用当前配置的addLoggerAppender方法将Appender添加到Logger中 。如果与Logger名称匹配的LoggerConfig不存在,则将创建一个LoggerConfig,将Appender附加到该LoggerConfig,然后所有Logger被通知去更新其LoggerConfig引用。
对于给定的logger,每个启用的记录请求将被转发给Logger的LoggerConfig中的所有appender以及LoggerConfig父级的Appender。 换句话说,Appender是从LoggerConfig层次继承的。例如,如果将控制台appender添加到根日志记录器,则所有启用的日志记录请求将至少在控制台上打印。如果此时一个file appender添加到名为C的LoggerConfig,那启用日志请求时C和C的子级将在一个文件和在控制台上打印。可以重写此默认行为,通过在配置文件的Logger声明中设置
additivity = "false",可使Appender累积功能不再具有可加性。
以下总结了Appender可加性的规则。
Appender的可加性
Logger L的日志语句的输出将传递到LoggerConfig L 自身 和 祖先中关联的所有Appender。这就是“appender additivity”的意思。
但是,如果与Logger L关联的LoggerConfig祖先 P,将其可加性标志设为
false,那么L的输出将被传递到LoggerConfig L和它的祖先直至P(包括P)中所有的appender,但不会传递至P的祖先中所关联的Appenders 。
记录器默认情况下将其可加性标志设置为
true。
| Logger Name | Added Appenders | Activity Flag | Output Targets | Comment |
|---|---|---|---|---|
| root | A1 | 不适用 | A1 | 根记录器没有父对象,所以可加性不适用于它。 |
| x | A-x1, A-x2 | true | A1, A-x1, A-x2 | “x”和root的Appenders。 |
| x.y | 无 | true | A1, A-x1, A-x2 | “x”和root的Appenders,没有配置Appender的logger是不常见的。 |
| x.y.z | A-xyz1 | true | A1, A-x1, A-x2, A-xyz1 | “x.y.z”、”x”和root的Appenders。 |
| security | A-sec | false | A-sec | 由于可加性标志设置为false,所以没有appender的积累。 |
| security.access | 无 | true | A-sec | 只有”security”的appender,因为”security”中的可加性标志被设置为false。 |
Layout
多数情况下,用户希望不仅自定义输出目标,而且还要自定义输出格式。这是通过将Layout与Appender关联来实现的 。布局负责根据用户的意愿格式化LogEvent,而appender负责将格式化的输出发送到目的地。所述的PatternLayout,是log4j分发标准的一部分,能让用户根据类似于C语言的printf函数的转换模式来指定输出格式。
例如,具有转换模式“%r [%t]%-5p%c - %m%n”的PatternLayout将输出类似于:
176 [main] INFO org.foo.Bar - Located nearest gas station.
第一个字段是程序启动以来经过的毫秒数。第二个字段是处理日志请求的线程。第三个字段是日志语句的级别。第四个字段是与日志请求关联的logger的名称。“ - ”后面的文字是该陈述的讯息。
Log4j 为各种用例(如JSON,XML,HTML和Syslog(包括新的RFC 5424版本))提供了许多不同的布局。其他appender(如数据库连接器)将填充指定的字段而不是特定的文本布局。
同样重要的是,log4j将根据用户指定的标准呈现日志消息的内容。例如,如果您经常需要记录当前项目中使用的对象类型Oranges,则可以创建一个接受Orange实例的OrangeMessage类并将其传递给Log4j,以便在将Orange对象格式化为合适的字节数组时需要。
StrSubstitutor和StrLookup
该 StrSubstitutor 类和 StrLookup 接口是从Apache Commons Lang中借用的,然后加以修改来支持评估LOGEVENTS。另外 Interpolator 类是从Apache Commons Configuration借用来允许StrSubstitutor评估来自多个StrLookups的变量。它也被修改为支持评估LogEvents。上述代码提供了一种机制,允许配置引用来自系统属性,配置文件,LogEvent中的ThreadContext Map,StructuredData的变量。如果组件能够处理它,则可以在处理配置时或处理每个事件时解析变量。请参阅 Lookups 了解更多信息。原文链接:Architecture
译文链接:http://blog.csdn.net/why_still_confused/article/details/79097136
版权声明:本文为博主原创翻译文章,若要转载请注明文章出处

相关文章推荐
- WCF服务端运行时架构体系详解[下篇]
- Oracle Golden Gate体系架构详解
- Oracle Golden Gate体系架构详解(转载)
- Oracle Golden Gate体系架构详解
- HDFS追本溯源:体系架构详解
- java程序员菜鸟进阶(五)oracle基础详解(五)oracle数据库体系架构详解
- Oracle Golden Gate体系架构详解(转载)
- WCF客户端运行时架构体系详解
- OracleDBA+性能优化8日游笔记——第二天(二)之Oracle体系架构详解
- Chapter 1.2:WCF体系架构详解
- WCF服务端运行时架构体系详解2
- 融云 iOS消息体系架构详解
- WCF客户端运行时架构体系详解[上篇]
- WCF服务端运行时架构体系详解[上篇]
- HDFS追本溯源:体系架构详解
- WCF服务端运行时架构体系详解[续篇]
- InnoDb 体系架构和特性详解 (Innodb存储引擎读书笔记总结)
- Java后台架构篇--Struts2.0体系结构图以及详解
- HDFS追本溯源:体系架构详解
- java程序员菜鸟进阶(五)oracle基础详解(五)oracle数据库体系架构详解