Spark集群数据处理速度慢(数据本地化问题)
2018-01-18 18:15
447 查看
SparkStreaming拉取Kafka中数据,处理后入库。整个流程速度很慢,除去代码中可优化的部分,也在spark集群中找原因。
发现:
集群在处理数据时存在移动数据与移动计算的区别,也有些其他叫法,如:数据本地化、计算本地化、任务本地化等。
自己简单理解:
假设集群有6个节点,来了一批数据共12条,数据被均匀的分布在了每个节点,也就是每个节点2条。现在要开始处理这些数据。
一种情况是:某数据由哪个节点处理被随机的分配,类似A节点存了数据1和数据2却可能被要求处理C节点的数据5和数据6,C节点的数据5和数据6就被备份到A节点,而A节点的数据又要备份到其他某一节点用于被处理。集群节点间存在大量数据移动,影响了速度。
另一种情况:某节点自身储存的数据就由自身来处理,比如A节点存储了数据1和数据2,那么数据1和数据2就由A节点来计算,C节点存储了数据5和数据6,那么数据5和数据6就由C节点来计算。这也就避免了数据的移动。
当然实际要比我描述的复杂得多,我的理解肯定也有不对的地方。
浏览器打开spark 8080端口master界面,图中红色箭头处如果显示各机器IP地址那就很有可能会造成移动数据的问题。
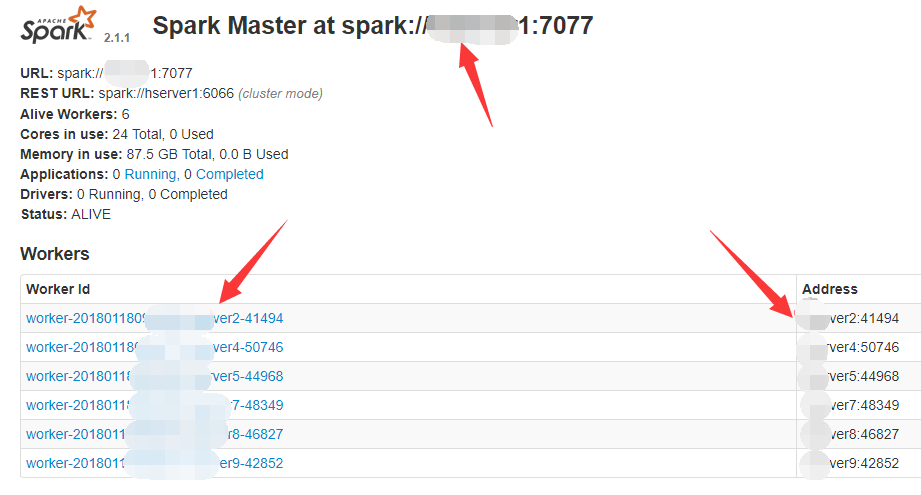
解决:
先停止spark集群,在master机器用 start-master.sh 启动,然后分别在每一台worker机器用 start-slave.sh -h 本机hostname spark://master机器hostname:7077 启动。
过程中可能遇到很多问题,多注意每台机器上的几个文件中的内容是否有问题:/etc/hosts, spark中conf文件夹中spark-env.sh和slaves

相关文章推荐
- Spark生态之Alluxio学习23--alluxio-0.7.1解决数据本地化的问题
- 大数据集群遇到的问题(Hadoop、Spark、Hive、kafka、Hbase、Phoenix)
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十五)Structured Streaming:同一个topic中包含一组数据的多个部分,按照key它们拼接为一条记录(以及遇到的问题)。
- 大数据 IMF 传奇 spark -history在分布式 集群 的安装部署 及问题解决
- 记一次Spark集群查询速度变慢的问题调查
- hadoop spark 大数据集群环境搭建(一)
- ASP.NET中使用数据处理插入数据注意的问题
- hadoop的集群配置,原创解决了好多个问题(spark+hadoop+scala集群配置)
- spark集群从HDFS中读取数据并计算
- 集群间 Hive 数据 迁移 问题
- 大数据:Spark Storage(一) 集群下的区块管理
- hadoop 集群环境Sqoop 将数据导入mysql问题 many connection errors; unblock with 'mysqladmin flush-hosts'
- spark中遇到的数据倾斜问题
- Josephu 问题解决策略:数组与链表的融合,十倍速度的差距(百万级数据)
- spark streaming job数据输出数目不准确问题排查记录
- spark streaming 读取kafka数据问题
- MysqlNDBcluster集群数据操作可能出现的问题
- 关于在Spark集群中读取本地文件抛出找不到文件异常的问题
- spark集群详细搭建过程及遇到的问题解决(四)
- spark集群搭建整理之解决亿级人群标签问题