卡尔曼滤波(Kalman Filter)原理理解和测试
2018-01-18 16:32
225 查看
Kalman Filter学原理学习
1. Kalman Filter 历史
Kalman滤波器的历史,最早要追溯到17世纪,Roger Cotes开始研究最小均方问题。但由于缺少实际案例的支撑(那个时候哪来那么多雷达啊啥的这些信号啊),Cotes的研究让人看着显得很模糊,因此在估计理论的发展中影响很小。17世纪中叶,最小均方估计(Least squares Estimation)理论逐步完善,Tobias Mayer在1750年将其用于月球运动的估计,Leonard Euler在1749年、Pierre Laplace在1787分别用于木星和土星的运动估计。Roger Boscovich在1755用最小均方估计地球的大小。1777年,77岁的Daniel Bernoulli(大名鼎鼎的伯努利)发明了最大似然估计算法。递归的最小均方估计理论是由Karl Gauss建立在1809年(好吧,他声称在1795年就完成了),当时还有Adrien Legendre在1805年完成了这项工作,Robert Adrain在1808年完成的。在1880年,丹麦的天文学家Thorvald Nicolai Thiele在之前最小均方估计的基础上开发了一个递归算法,与Kalman滤波非常相似。在某些标量的情况下,Thiele的滤波器与Kalman滤波器时等价的,Thiele提出了估计过程噪声和测量噪声中方差的方法(过程噪声和测量噪声是Kalman滤波器中关键的概念)。上面提到的这么多研究估计理论的先驱,大多是天文学家而非数学家。现在,大部分的理论贡献都源自于实际的工程。“There is nothing so practical as a good theory”,应该就是“实践是检验真理的唯一标准”之类吧。
现在,我们的控制论大Wiener终于出场了,还有那个叫Kolmogorov(柯尔莫戈洛夫)的神人。在19世纪40年代,Wiener设计了Wiener滤波器,然而,Wiener滤波器不是在状态空间进行的(这个学过Wiener滤波的就知道,它是直接从观测空间z(n)=s(n)+w(n)进行的滤波),Wiener是稳态过程,它假设测量是通过过去无限多个值估计得到的。Wiener滤波器比Kalman滤波器具有更高的自然统计特性。这些也限制其只是更接近理想的模型,要直接用于实际工程中需要足够的先验知识(要预知协方差矩阵),美国NASA曾花费多年的时间研究维纳理论,但依然没有在空间导航中看到维纳理论的实际应用。
在1950末期,大部分工作开始对维纳滤波器中协方差的先验知识通过状态空间模型进行描述。通过状态空间表述后的算法就和今天看到的Kalman滤波已经极其相似了。Johns Hopkins大学首先将这个算法用在了导弹跟踪中,那时在RAND公司工作的Peter Swerling将它用在了卫星轨道估计,Swerling实际上已经推导出了(1959年发表的)无噪声系统动力学的Kalman滤波器,在他的应用中,他还考虑了使用非线性系统动力学和和测量方程。可以这样说,Swerling和发明Kalman滤波器是失之交臂,一线之隔。在kalman滤波器闻名于世之后,他还写信到AIAA Journal声讨要获得Kalman滤波器发明的荣誉(然而这时已经给滤波器命名Kalman了)。总结其失之交臂的原因,主要是Swerling没有直接在论文中提出Kalman滤波器的理论,而只是在实践中应用。
Rudolph Kalman在1960年发现了离散时间系统的Kalman滤波器,这就是我们在今天各种教材上都能看到的,1961年Kalman和Bucy又推导了连续时间的Kalman滤波器。Ruslan Stratonovich也在1960年也从最大似然估计的角度推导出了Kalman滤波器方程。
2. Kalman Filter 白话理解
引自:Highgear一片绿油油的草地上有一条曲折的小径,通向一棵大树.一个要求被提出: 从起点沿着小径走到树下。“很简单。” A说,于是他丝毫不差地沿着小径走到了树下。现在,难度被增加了:蒙上眼。“也不难,我当过特种兵。” B说,于是他歪歪扭扭地走到了树旁。“唉,好久不练,生疏了。” (只凭自己的预测能力)。“看我的,我有 DIY 的 GPS!” C说,于是他像个醉汉似地歪歪扭扭的走到了树旁。“唉,这个 GPS 没做好,漂移太大。”(只依靠外界有很大噪声的测量)“我来试试。” 旁边一也当过特种兵的拿过 GPS, 蒙上眼,居然沿着小径很顺滑的走到了树下。(自己能预测+测量结果的反馈)
“这么厉害!你是什么人?”
“卡尔曼 ! ”
“卡尔曼?!你就是卡尔曼?”众人大吃一惊。 “我是说这个 GPS 卡而慢。”
引自:Kent Zeng
假设你有两个传感器,测的是同一个信号。可是它们每次的读数都不太一样,怎么办?
取平均。
再假设你知道其中贵的那个传感器应该准一些,便宜的那个应该差一些。那有比取平均更好的办法吗?
加权平均。
怎么加权?假设两个传感器的误差都符合正态分布,假设你知道这两个正态分布的方差,用这两个方差值,(此处省略若干数学公式),你可以得到一个“最优”的权重。接下来,重点来了:假设你只有一个传感器,但是你还有一个数学模型。模型可以帮你算出一个值,但也不是那么准。怎么办?
把模型算出来的值,和传感器测出的值,(就像两个传感器那样),取加权平均。
OK,最后一点说明:你的模型其实只是一个步长的,也就是说,知道x(k),我可以求x(k+1)。
问题是x(k)是多少呢?答案:x(k)就是你上一步卡尔曼滤波得到的、所谓加权平均之后的那个对x在k时刻的最佳估计值。
于是迭代也有了。这就是卡尔曼滤波
引自:周啸
假设我养了一只猪:

一周前,这只猪的体重是46±0.5kg。注意,在这里我用了±0.5,表示其实我对这只猪一周前的体重并不是那么确定的,也就是说,46kg这个体重有0.5kg的误差。
现在,我又养了这只猪一个星期。那么我想要知道它一个星期之后多重,又大概有多少的误差?

为了得到一周后的体重,我有两种方法:一是根据我多年的养猪经验得到的猪体重公式推求出一个大概的值,另一个就是直接去称它的体重。当然,两种方法都有一定的误差。假设经验公式得到的体重是48kg,误差2kg;直接称体重得到的是49kg,误差1kg:
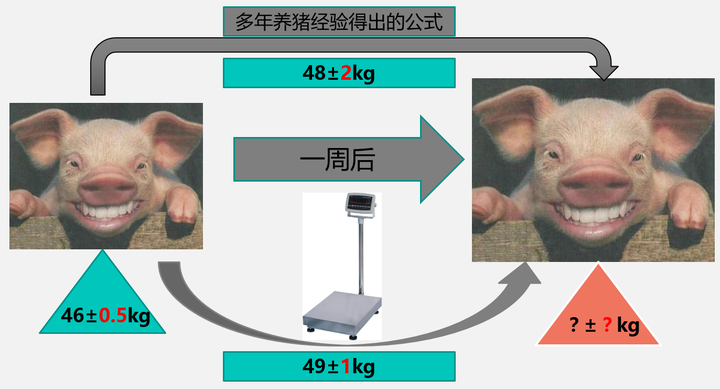
可是,我是一个处女座的人,不管是经验公式得到的值,还是直接称量得到的值,我都觉得不够准。我希望有一种方法,可以同时结合这只猪一周前的体重、用经验公式估计的值以及直接称量得到的值,综合考虑,得出一个最接近猪真实体重的,误差最小的值。这就是卡尔曼滤波要完成的任务。现在我们来把养猪的模型抽象成数学公式:
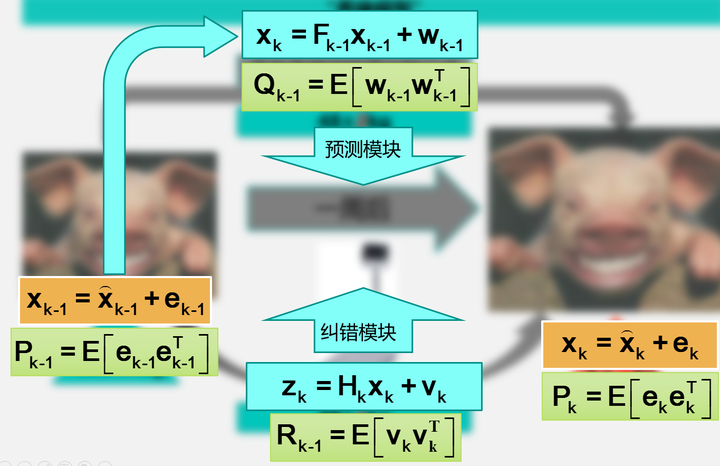
上图的左边,上一周的猪的体重,可以抽象为也k-1时刻的状态值,用k-1时刻的最优估计值加上一个误差项来表示,右边同理。其中,
P=E[ekeTk](31)(31)P=E[ekekT]
这一项表示的是估计值的协方差。这里要说明两点:1,上图中所有的变量都是用粗体,表示这是一个向量或者一个矩阵;2,之所以用(列)向量而非一个数来表示状态值,是因为,虽然一只猪的体重可以用一个值来表示,但是在实际的应用中很多状态并不是一个数就能表示的(比如导弹在空间中的位置,同时有x、y、z三个坐标)。上图中右边表示k时刻的状态值,这个值可以通过预测模块(也就是根据经验公式估计猪的体重)和纠错模块(也就是直接去称量猪的体重值)来估计。同样,预测模块和纠错模块都有着对应的误差和误差协方差矩阵。卡尔曼滤波要做的,就是根据贝叶斯估计的相关理论,同时考虑预测模块和纠错模块的协方差,对误差小的项赋予较大的权重,对误差大的项赋予较小的权重,并使预测的误差最小。
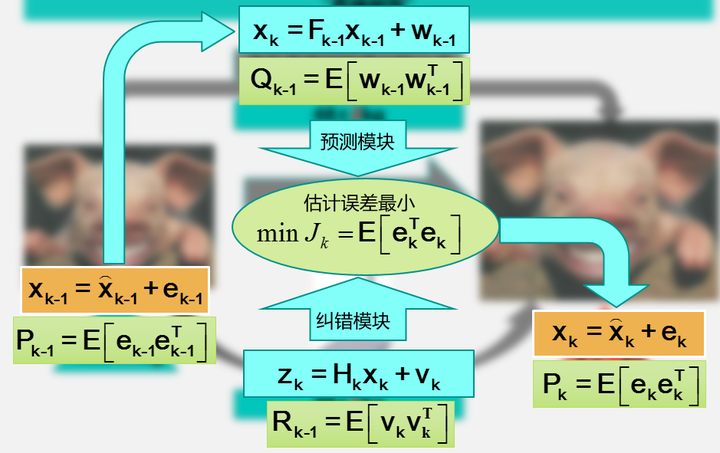
具体的实现过程如下:
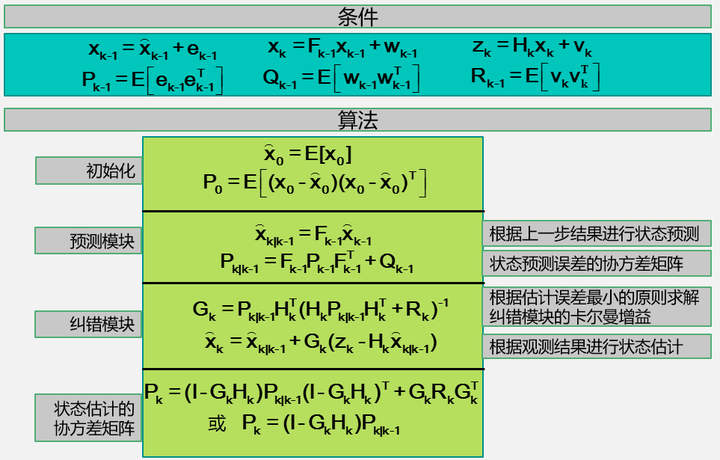
知乎肖畅的回答也很好,推荐查看,这里附上几张简略图
在t=0时刻,原始位置
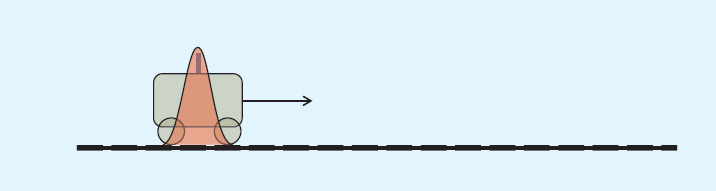
在t=1时刻,预测位置

在t=1时刻,测量位置
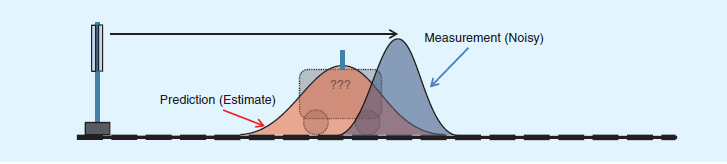
结合预测和测量

3. 先验知识
卡尔曼滤波是一种高效率的递归滤波器(自回归滤波器), 它能够从一系列的不完全及包含噪声的测量中,估计动态系统的状态。卡尔曼滤波的一个典型实例是从一组有限的,包含噪声的,对物体位置的观察序列(可能有偏差)预测出物体的位置的坐标及速度。3.1 正太分布
在概率论中,正态(或高斯)分布是一个非常普遍的连续概率分布。先来简单看一元高斯分布,其概率密度为:p(x)∼N(u,σ2)(21)(21)p(x)∼N(u,σ2)
f(x|u,σ2)=12πσ2−−−−√e−(x−u)22σ2(22)(22)f(x|u,σ2)=12πσ2e−(x−u)22σ2
其中,uu 是分布的均值或期望; σσ 是标准差; σ2σ2 是方差。下图为一元高斯的一个示意图。

再谈多元高斯分布,k维随机向量 X=[X1,X2,...,Xk]TX=[X1,X2,...,Xk]T 的多元正态分布:
X∼N(u,Σ)(23)(23)X∼N(u,Σ)
这里举例二元高斯分布,其概率密度为:

正太分布的性质
1 经过线性变换高斯分布仍然为高斯分布X∼N(μ,Σ)Y=AX+B}⇒Y∼N(Aμ+B,AΣAT)(5)(5)X∼N(μ,Σ)Y=AX+B}⇒Y∼N(Aμ+B,AΣAT)
2 高斯变量线性组合仍为高斯分布
X1∼N(μ1,σ21)X2∼N(μ2,σ22)}⇒p(X1+X2)∼N(μ1+μ2,σ21+σ22+2ρσ1σ2)(6)(6)X1∼N(μ1,σ12)X2∼N(μ2,σ22)}⇒p(X1+X2)∼N(μ1+μ2,σ12+σ22+2ρσ1σ2)
3 两个相互独立的高斯变量的乘积,仍然为高斯分布
X1∼N(μ1,σ21)X2∼N(μ2,σ22)}⇒p(X1)⋅p(X2)∼N(σ22σ21+σ22μ1+σ21σ21+σ22μ2,σ21σ22σ21+σ22)(7)(7)X1∼N(μ1,σ12)X2∼N(μ2,σ22)}⇒p(X1)⋅p(X2)∼N(σ22σ12+σ22μ1+σ12σ12+σ22μ2,σ12σ22σ12+σ22)
3.2 中心极限定理
Wiki百科, 在概率论中,中心极限定理(CLT)证明,在大多数情况下,当独立的随机变量被加上时,它们正确的归一化和趋于正态分布(非正式的“ 钟形曲线 ”),即使原始变量本身不是正常分布。该定理是概率论中的一个关键概念,因为它意味着适用于正态分布的概率统计方法可以适用于涉及其他类型分布的许多问题。例如,假设获得的样本包含大量的观测值,每个观测值都是以不依赖于其他观测值的方式随机生成的,并且计算观测值的算术平均值。如果此过程被执行许多次,中心极限定理说,平均的计算值将被分布根据正态分布。一个简单的例子是,如果一个硬币多次翻转在一系列翻转中获得给定数量的头部的概率将接近正态曲线,其平均值等于每个系列中翻转总数的一半。(在无限次翻转的限制下,它将等于一条正常曲线。)
中心极限定理有许多变体。在其通常的形式中,随机变量必须是相同的分布。
3.3 协方差
Wiki百科, 在概率论和统计学中,协方差是两个随机变量的联合变异性的量度。如果一个变量的较大值主要与另一个变量的较大值相对应,并且对于较小值也是如此,即变量倾向于显示相似的行为,则协方差是正的。在相反情况下,当一个变量的值越大,主要对应于其他的,即,更小的值,变量往往显示相反的行为,协方差是负的。因此,协方差的符号显示了线性关系的趋势之间的变量。协方差的大小不容易解释,因为它不是标准化的,因此取决于变量的大小。定义:具有有限二次矩的两个联合分布的 实值随机变量 X和Y之间的协方差定义为它们与其各自期望值的偏差的期望乘积。
cov(X,Y)=E[(X−E[X])][Y−E[Y]](24)(24)cov(X,Y)=E[(X−E[X])][Y−E[Y]]
其中,E[X]E[X] 是所述预期值的XX,也被称为的平均值XX。协方差也有时表示σXYσXY或σ(X,Y)σ(X,Y),以类似于方差。通过使用期望的线性特性,可以将其简化为其产品的期望值减去期望值的乘积.
cov(X,Y)=E[XY]−E[X]E[Y](25)(25)cov(X,Y)=E[XY]−E[X]E[Y]
3.4 隐含马尔科夫模型
这里引用吴军老师《数学之美》,很不幸我没找到相关的网页。大家可以去看书,很好理解。篇幅太长。这里简单说下。先看如下图所示的典型通信模型示意图。

其中S1,S2,S3,⋯S1,S2,S3,⋯表示信息源发出的信号,比如手机发送的信号。O1,O2,O3,⋯O1,O2,O3,⋯是接收器(比如PC或者手机)接收到的信号。通信中的解码就是根据接收到的信号O1,O2,O3,⋯O1,O2,O3,⋯还原为发送的信号S1,S2,S3,⋯S1,S2,S3,⋯ 。
在通信中,如何如何将O1,O2,O3,⋯O1,O2,O3,⋯还原为发送的信号S1,S2,S3,⋯S1,S2,S3,⋯,只需要从所有的源信息中找到最可能产出观测信号的那一个信号。用概率论的语言来描述,就是在已O1,O2,O3,⋯O1,O2,O3,⋯的情况下,求得令条件概率P(S1,S2,S3,⋯|O1,O2,O3,⋯)P(S1,S2,S3,⋯|O1,O2,O3,⋯)达到最大值的那个信息串S1,S2,S3,⋯S1,S2,S3,⋯,即:
S1,S2,S3,⋯=ArgMaxP(S1,S2,S3,⋯|O1,O2,O3,⋯)(29)(29)S1,S2,S3,⋯=ArgMaxP(S1,S2,S3,⋯|O1,O2,O3,⋯)
其中Arg是参数Argument的缩写,表示能获得最大值的那个信息串S1,S2,S3,⋯S1,S2,S3,⋯。
可是怎么求呢?利用贝叶斯公式间接求:
P(O1,O2,O3,⋯|S1,S2,S3,⋯)⋅P(S1,S2,S3,⋯)P(O1,O2,O3,⋯)(30)(30)P(O1,O2,O3,⋯|S1,S2,S3,⋯)⋅P(S1,S2,S3,⋯)P(O1,O2,O3,⋯)
其中,P(O1,O2,O3,⋯|S1,S2,S3,⋯)P(O1,O2,O3,⋯|S1,S2,S3,⋯)表示信息S1,S2,S3,⋯S1,S2,S3,⋯在传输后变成O1,O2,O3,⋯O1,O2,O3,⋯的可能性;而P(S1,S2,S3,⋯)P(S1,S2,S3,⋯)表示本身是一个合乎情理的句子,同样P(O1,O2,O3,⋯)P(O1,O2,O3,⋯)表示说话的人产生的信息O1,O2,O3,⋯O1,O2,O3,⋯的合理性。
再来考虑如何简化,一旦信息产生了他就不会改变了,这时P(O1,O2,O3,⋯)P(O1,O2,O3,⋯)就是一个可以忽略的常数了。然后剩下的项就可以使用Hidden Markov Model来估计了。
图略
两个假设:
1. 马尔科夫假设:任意时刻的状态只依赖于其前一个时刻的状态,即sisi的状态只依赖于si−1si−1。
2. 独立输出假设:任意时刻的观测只依赖于当前时刻的装填,即oioi的状态只依赖于sisi。
在继续之前,我们需要了解隐马尔可夫链的状态转移以及观测序列的生成过程,假设隐藏状态空间(未知的输入信号状态)包含NN个状态(s1,s2,s3,⋯,sN)(s1,s2,s3,⋯,sN),此时隐马尔可夫链可以形象描述为一个多段图GG(学过算法的都知道),每一层包含NN个节点,每个节点表示状态空间中的一个状态sisi,相邻层之间的节点全连接,那么从第一层到最后一层(假设包含TT层)的路径也就有NT−1条,每一条路径(记为PP)都会包含T个节点,每一条路径都会以P(O1,O2,O3,⋯|S1,S2,S3,⋯)P(O1,O2,O3,⋯|S1,S2,S3,⋯)生成一个观测序列。
我们此时已知变量有:多段图GG的初始状态;节点之间的转移概率;观测序列中节点的生成概率;我们的问题是如何根据这个结构以及观测序列来得到一个最优路径(概率最大路径)
我们可以使用维特比算法来得到最优路径,实质上是一个简单的动态规划问题。
4. Kalman Filter 详述
4.1 模型
卡尔曼滤波模型理论建立在线性代数和隐含马尔可夫模型。其基本动态系统可以用一个马尔可夫链表示,该马尔可夫链建立在一个被高斯噪声(即正态分布的噪声)干扰的线性算子上的。系统的状态可以用一个元素为实数的向量表示。 随着离散时间的每一个增加,这个线性算子就会作用在当前状态上,产生一个新的状态,并也会带入一些噪声,同时系统的一些已知的控制器的控制信息也会被加入。同时,另一个受噪声干扰的线性算子产生出这些隐含状态的可见输出。模型图如下图所示:

4.2 模型假设
系统的状态方程是线性的;观测方程是线性的;
过程噪声符合零均值高斯分布;
观测噪声符合零均值高斯分布;
满足以上4点假设,一直在线性变化的空间中操作高斯分布,状态的概率密度符合高斯分布。卡尔曼滤波是一种递归的估计,只要获知上一时刻状态的估计值以及当前状态的观测值就可以计算出当前状态的估计值,因此不需要记录观测或者估计的历史信息。
卡尔曼滤波器的递归过程:
1) 估计时刻kk 的状态:
X(k)=A∗X(k−1)+B∗u(k)(13)(13)X(k)=A∗X(k−1)+B∗u(k)
u(k)u(k) ,是系统输入,ll维向量,表示kk时刻的输入;
X(k)X(k),nn维向量,表示kk时刻观测状态的均值;
AA,n∗nn∗n矩阵,表示状态从k−1k−1到kk在没有输入影响时转移方式;
BB,n∗nn∗n矩阵,表示u(k)u(k)如何影响x(k)x(k).
2) 计算误差相关矩阵PP, 度量估计值的精确程度:
P(k)=A∗P(k−1)∗AT+Q(14)(14)P(k)=A∗P(k−1)∗AT+Q
PkPk,n∗nn∗n方差矩阵,表示kk时刻被观测的nn个状态的方差。
Q=E(W2j)Q=E(Wj2) 是系统噪声的协方差阵,即系统框图中的WjWj的协方差阵, QQ 应该是不断变化的,为了简化,当作一个常数矩阵。
3) 计算卡尔曼增益:
K(k)=P(k)∗HT∗(H∗P(k)∗HT+R)−1(15)(15)K(k)=P(k)∗HT∗(H∗P(k)∗HT+R)−1
这里R=E(V2j)R=E(Vj2), 是测量噪声的协方差(阵), 即系统框图中的 VjVj 的协方差, 为了简化,也当作一个常数矩阵;
HH,m∗nm∗n矩阵,表示状态x(k)x(k)如何被转换为观测z(k)z(k)。
由于我们的系统一般是单输入单输出,所以RR是一个1×11×1的矩阵,即一个常数,上面的公式可以简化为:
K=P(k)∗HT(H∗P(k)∗HT+R)(16)(16)K=P(k)∗HT(H∗P(k)∗HT+R)
4) 状态变量反馈的误差量:
e=Z(k)–H∗X(k)(17)(17)e=Z(k)–H∗X(k)
这里的 Z(k)Z(k) 是带噪声的测量量
5) 更新误差相关矩阵PP
P(k)=P(k)–K∗H∗P(k)(18)(18)P(k)=P(k)–K∗H∗P(k)
6) 更新状态变量:
X(k)=X(k)+K∗e=X(k)+K∗(Z(k)–H∗X(k))(19)(19)X(k)=X(k)+K∗e=X(k)+K∗(Z(k)–H∗X(k))
7) 最后的输出:
Y(k)=H∗X(k)(20)(20)Y(k)=H∗X(k)
5. Kalman Filter 测试
6. 总结
REFERENCE
1 http://bbs.21ic.com/icview-292853-1-1.html2 http://blog.csdn.net/xiahouzuoxin/article/details/39582483
3 http://blog.csdn.net/yangtrees/article/details/8075911
4 http://www.cnblogs.com/ycwang16/p/5999034.html
5 http://blog.csdn.net/heyijia0327/article/details/17487467
6 http://blog.csdn.net/heyijia0327/article/details/17667341
7 https://en.wikipedia.org/wiki/Kalman_filter
Paper:http://www.cl.cam.ac.uk/~rmf25/papers/Understanding%20the%20Basis%20of%20the%20Kalman%20Filter.pdf

相关文章推荐
- Kalman filter卡尔曼滤波的原理说明
- Kalman Filter : 理解卡尔曼滤波的三重境界
- 更好理解贝叶斯定律(Bayes Law)和卡曼滤波器(Kalman Filter)原理
- 卡尔曼滤波原理快速理解
- 软件测试行业的个人理解 6 - 浅谈自动化测试原理
- js异步操作和理解,以及js函数运行原理分享。。
- JAVA简单工厂模式(从现实生活角度理解代码原理)
- 交叉测试的理解
- 测试相关理解(一)等价类划分法
- 理解指尖上的浏览场景:从一次眼动测试说起
- 【转】性能测试设计和LR原理的探讨
- 理解HTTP session原理及应用
- 理解了DirectShow播放原理(转载)
- 深入理解 Spring 事务原理
- JMS中的MDB原理及测试
- 百度Cafe原理--Android自动化测试框架学习
- 关于jsonp(~~原理和理解)
- HashMap实现原理、深入理解
- 理解SQL Server中索引的概念,原理