SQuAD文本理解挑战赛十大模型解读
2018-01-16 14:24
615 查看
引言
教机器学会阅读是近期自然语言处理领域的研究热点之一,也是人工智能在处理和理解人类语言进程中的一个长期目标。得益于深度学习技术和大规模标注数据集的发展,用端到端的神经网络来解决阅读理解任务取得了长足的进步。
本文是一篇机器阅读理解的综述文章,主要聚焦于介绍公布在 SQuAD(Stanford Question Answering Dataset)榜单上的各类模型,并进行系统地对比和总结。
SQuAD 简介
SQuAD 是由 Rajpurkar 等人 [1] 提出的一个最新的阅读理解数据集。该数据集包含 10 万个(问题,原文,答案)三元组,原文来自于 536 篇维基百科文章,而问题和答案的构建主要是通过众包的方式,让标注人员提出最多 5 个基于文章内容的问题并提供正确答案,且答案出现在原文中。
SQuAD 和之前的完形填空类阅读理解数据集如 CNN/DM [2],CBT [3] 等最大的区别在于:SQuAD 中的答案不在是单个实体或单词,而可能是一段短语,这使得其答案更难预测。
SQuAD 包含公开的训练集和开发集,以及一个隐藏的测试集,其采用了与 ImageNet 类似的封闭评测的方式,研究人员需提交算法到一个开放平台,并由 SQuAD 官方人员进行测试并公布结果。
我有几张阿里云幸运券分享给你,用券购买或者升级阿里云相应产品会有特惠惊喜哦!把想要买的产品的幸运券都领走吧!快下手,马上就要抢光了。
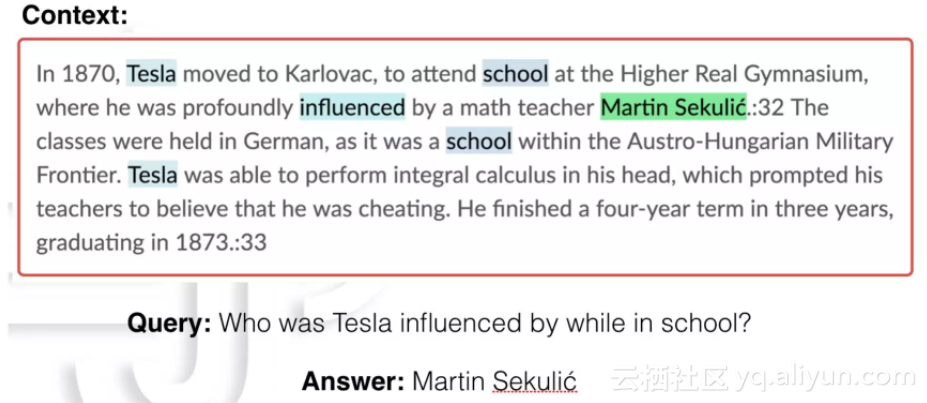
△ 图1:一个(问题,原文,答案)三元组
模型
自从 SQuAD 数据集公布以来,大量具有代表性的模型纷纷涌现,极大地促进了机器阅读理解领域的发展,下面就 SQuAD 榜单上代表性的模型进行介绍。
总的来说,由于 SQuAD 的答案限定于来自原文,模型只需要判断原文中哪些词是答案即可,因此是一种抽取式的 QA 任务而不是生成式任务。
几乎所有做 SQuAD 的模型都可以概括为同一种框架:Embed 层,Encode 层,Interaction 层和 Answer 层。
Embed 层负责将原文和问题中的 tokens 映射为向量表示;Encode 层主要使用 RNN 来对原文和问题进行编码,这样编码后每个 token 的向量表示就蕴含了上下文的语义信息;Interaction 层是大多数研究工作聚焦的重点,该层主要负责捕捉问题和原文之间的交互关系,并输出编码了问题语义信息的原文表示,即 query-aware 的原文表示;最后 Answer 层则基于 query-aware 的原文表示来预测答案范围。
原文链接
教机器学会阅读是近期自然语言处理领域的研究热点之一,也是人工智能在处理和理解人类语言进程中的一个长期目标。得益于深度学习技术和大规模标注数据集的发展,用端到端的神经网络来解决阅读理解任务取得了长足的进步。
本文是一篇机器阅读理解的综述文章,主要聚焦于介绍公布在 SQuAD(Stanford Question Answering Dataset)榜单上的各类模型,并进行系统地对比和总结。
SQuAD 简介
SQuAD 是由 Rajpurkar 等人 [1] 提出的一个最新的阅读理解数据集。该数据集包含 10 万个(问题,原文,答案)三元组,原文来自于 536 篇维基百科文章,而问题和答案的构建主要是通过众包的方式,让标注人员提出最多 5 个基于文章内容的问题并提供正确答案,且答案出现在原文中。
SQuAD 和之前的完形填空类阅读理解数据集如 CNN/DM [2],CBT [3] 等最大的区别在于:SQuAD 中的答案不在是单个实体或单词,而可能是一段短语,这使得其答案更难预测。
SQuAD 包含公开的训练集和开发集,以及一个隐藏的测试集,其采用了与 ImageNet 类似的封闭评测的方式,研究人员需提交算法到一个开放平台,并由 SQuAD 官方人员进行测试并公布结果。
我有几张阿里云幸运券分享给你,用券购买或者升级阿里云相应产品会有特惠惊喜哦!把想要买的产品的幸运券都领走吧!快下手,马上就要抢光了。
△ 图1:一个(问题,原文,答案)三元组
模型
自从 SQuAD 数据集公布以来,大量具有代表性的模型纷纷涌现,极大地促进了机器阅读理解领域的发展,下面就 SQuAD 榜单上代表性的模型进行介绍。
总的来说,由于 SQuAD 的答案限定于来自原文,模型只需要判断原文中哪些词是答案即可,因此是一种抽取式的 QA 任务而不是生成式任务。
几乎所有做 SQuAD 的模型都可以概括为同一种框架:Embed 层,Encode 层,Interaction 层和 Answer 层。
Embed 层负责将原文和问题中的 tokens 映射为向量表示;Encode 层主要使用 RNN 来对原文和问题进行编码,这样编码后每个 token 的向量表示就蕴含了上下文的语义信息;Interaction 层是大多数研究工作聚焦的重点,该层主要负责捕捉问题和原文之间的交互关系,并输出编码了问题语义信息的原文表示,即 query-aware 的原文表示;最后 Answer 层则基于 query-aware 的原文表示来预测答案范围。
原文链接

相关文章推荐
- SQuAD文本理解挑战赛十大模型解读
- SQuAD文本理解挑战赛十大模型解读
- 【十大算法实现之naive bayes】朴素贝叶斯算法之文本分类算法的理解与实现
- 深入理解盒子——模型文本垂直居中的N种方法 单行/多行文字(未知高度/固定高度)
- springMVC模型驱动set,get再加工理解
- 通俗理解LDA主题模型
- 【图像理解】自动生成图像的文本描述
- 【技术外文翻译】解读Keras在ImageNet中的应用:详解5种主要的图像识别模型
- 解读ember的应用模型
- 模型的偏差与方差的理解
- 辨异 —— 机器学习概念辨异、模型理解
- 深入理解Java虚拟机笔记--JVM内存模型及溢出问题总结
- [我们是这样理解语言的-1]文本分析平台
- 初步理解和使用Excel对象模型
- 《传统企业,互联网在踢门》书评 - 更容易理解的互联网+解读
- CSS3新标准选择器 框模型 背景和边框 文本效果 2D/3D 转换 动画 多列布局 用户界面
- iOS CoreData详解(六)深入理解数据模型
- 用一两句话说一下你对“盒模型”这个概念的理解,和它都涉及到哪些css属性
- 有关基于模型的设计(MBD)一些概念和理解(zz)
- 对流式计算模型的理解