Coursera-吴恩达-机器学习-(第3周笔记)Logistic Regression and Regularization
2018-01-12 11:00
573 查看
此系列为 Coursera 网站Andrew Ng机器学习课程个人学习笔记(仅供参考)
课程网址:https://www.coursera.org/learn/machine-learning
目录
一 分类和模型表示
1-1 分类问题
1-2 分类模型的表示
1-3分类决策边界
二 逻辑回归Logistics Regression
2-1 逻辑回归的代价函数cost
2-2 用梯度下降法求解参数theta
2-3 高级优化
三 多分类问题 one vs all
四 过拟合和正则化Overfitting Regularization
4-1 过拟合overfitting
4-2 正则化Regularization
4-3 正则化在线性回归中的应用
4-3-1 带有正则化的梯度下降
4-3-2 带有正则化的正规方程
4-4 正则化在逻辑回归中的应用
邮件是垃圾邮件还是非垃圾邮件;
网上交易是的欺骗性(Y or N);
肿瘤是恶性的还是良性的。
对于这些问题,我们可以通过输出值y ϵ {0, 1} 来表示。
注意:分类结果是离散值,这是分类的根本特点。

(1)如果y的取值只有0和1,训练集画出来这这个样子(先没有绿框中的点),我们用线性回归得到1号直线,如果认为模拟直线的取值小于0.5时则预测值就为0,如果模拟直线的取值大于0.5时预测值就为1,感觉还不错。
(2)但是将绿框中的点加入后,线性回归得到的直线2,就显得不是很完美了。经过大量的实验证明,线性回归不适合这种训练集。那么怎么解决这个问题呢?
而且普通的hθ(x)函数存在函数值大于1和小于0的情况(没有意义),于是我们要构造特殊函数使0≤hθ(x)≤1。

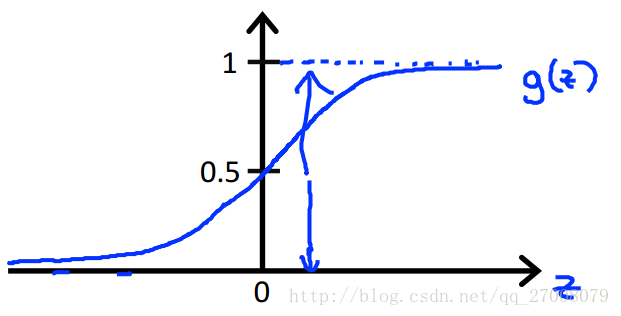
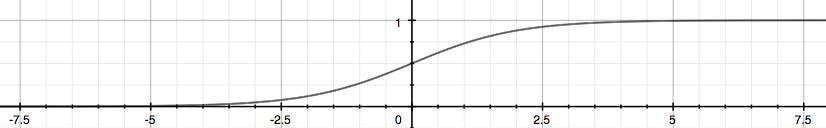
对于二类分类问题,y只有两个输出0和1,hθ(x)给出了输出y=1的概率。
用数学表达式表示:
hθ(x)=P(y=1∣x,θ)=1−P(y=0∣x,θ)



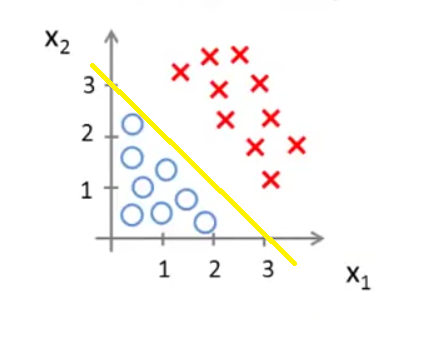
我们可以直观地看出,当(x1,x2)在这条直线的上方,则预测 y=1;当(x1,x2)在这条直线的下方,则预测 y=0。−x1+x2=3这条直线就是这里的决策边界(Decision Boundary)。它将空间分为两个区域,预测y=0和预测y=1。这条直线并不是数据集本身的属性,而是假设函数(hypothesis)和其参数θ的属性。
值得注意的是,logistic 函数g(z)的输入(θTx)并不总是线性的:
上面的决策边界−x1+x2=3属于线性决策边界,再看一个非线性决策边界的例子。假设训练数据的分布如下图所示,则可用高阶多项式进行拟合。
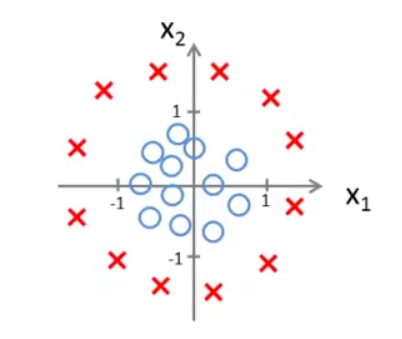

此时的决策边界为一个圆心在原点,半径为1的圆,当(x1,x2)位于圆外部,我们可以预测y=1;当(x1,x2)位于圆内部,我们可以预测y=0。

我们仍然采用之前的符号定义:



因此,在逻辑回归中,需要另寻一个代价函数,使其是凸函数(单弓形),如下图,这样就可以使用梯度下降法找到全局最小值。

我们选择如下的代价函数来表示单个样本的代价:

这个函数看起来很复杂。下面我们通过画出它的图像来解释选择它的原因。
1、当y=1,Cost(hθ(x),y) 关于hθ(x)的图像:

注意横坐标为hθ(x),而hθ(x)的取值范围为(0,1),所以图像只取(0,1)段。
我们可以看出,当hθ(x)=1,则假设函数预测结果与事实一致,Cost=0;当hθ(x)=0,则预测结果与事实不符,Cost=∞,说明要通过一个很大的代价 Cost→∞ 来惩罚学习算法。
2、当y=1,Cost(hθ(x),y) 关于hθ(x)的图像:

横坐标为hθ(x),而hθ(x)的取值范围为(0,1),所以图像只取(0,1)段。
同理,若y=0,而hθ(x)=1,将通过一个很大的代价 Cost→∞ 来惩罚学习算法。
以上说明在求解参数θ时,当选择合适的代价函数(代价函数转化为一个凸函数),我们就可以将问题转化为凸优化问题(convex optimization problem),方便我们求解全局最小值。
简化代价函数

回忆我们之前的梯度下降共公式:

我们回忆之前所讲的线性回归中梯度下降的更新公式,你会发现,线性回归和逻辑回归的梯度下降更新公式是一样的。(视频中并未说明为什么,但是推导出的结果确实如此)
但我们需要注意,两个公式中 hθ(x) 是不同的,线性回归中, hθ(x)=θTx,而逻辑回归中,hθ(x)=11+e−θTx,所以两者的梯度下降还是不同的。
梯度下降更新公式用向量表示(代码实现时常用到):
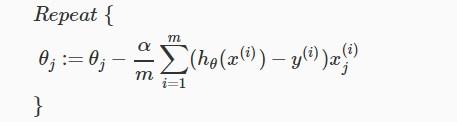
我们之前所讲的梯度下降常见两个问题的解决方法以及特征缩放对于逻辑回归也是适用的,在此不再赘述。

对于梯度下降法我们可以在octive中使用如下高级函数

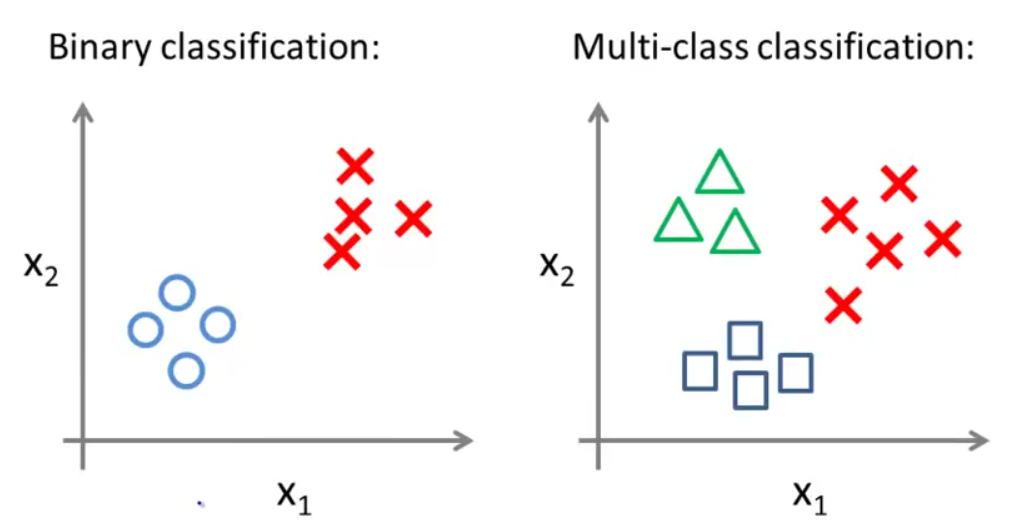
举例,一个二类分类问题的数据集分布如下图左所示,一个多类分类问题的数据集分布如下图右所示(用不同的符号表示不同的类别):
在之前所讲的二类分类问题中,我们可以使用逻辑回归用直线将数据集一分为二为正类和负类。那么我们如何用一对多(one vs all)的分类思想解决多分类问题?
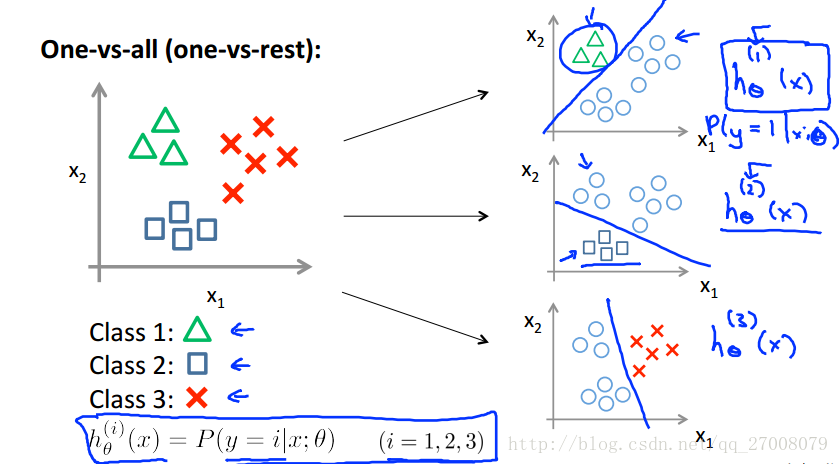
用上图右数据集举例说明。图中数据一共有三类,我们可以将其转化为三个二分类问题。在每一个两类分类问题中,把待识别的类别当作正类别,其余合为一类作为负类别。如下图:

总结:
One vs all:
Train a logistic regression classifier h(i)θ(x) for each class to predict the probability that y=i .
To make a prediction on a new x, pick the class that maximizes h(i)θ(x):maxi(h(i)θ(x))
这一小节内容会为大家解释什么是过拟合问题,并且介绍一种可以改善或减少过度拟合问题的技术——正则化技术( regularization)。
(1)欠拟合(underfitting)
欠拟合(underfitting)也称为高偏差(high bias)。即,拟合出的假设函数在训练数据集上不能很好地拟合数据, h(i)θ(x)和 y 的偏差比较大,如下图(左为线性回归欠拟合,右为逻辑回归欠拟合)
(2)适度拟合(just right)
即,拟合出的假设函数在训练数据集上能较好的反映输出和输入的关系,hθ(x)和y的偏差不大,如下图(左为线性回归适度拟合,右为逻辑回归适度拟合)
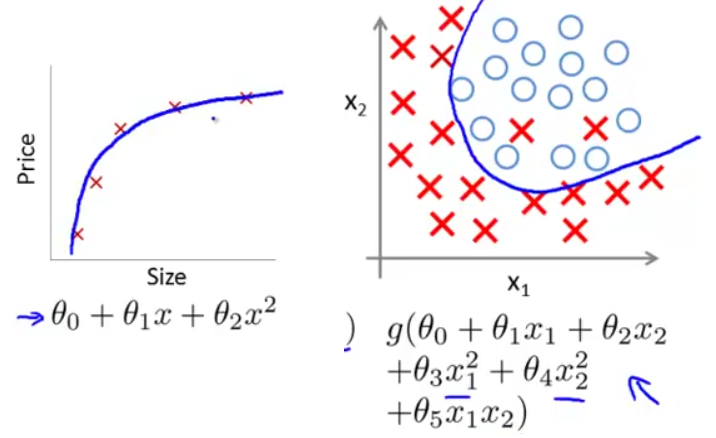
(3)过拟合(overfitting)
过拟合(overfitting)也称为高方差(high variance)。即,由于特征变量太多,导致学习到的假设函数太过适合于训练数据集,甚至J(θ)≈0,导致无法泛化(generalize)到新的数据样本,如下图(左为线性回归过拟合,右为逻辑回归过拟合)。
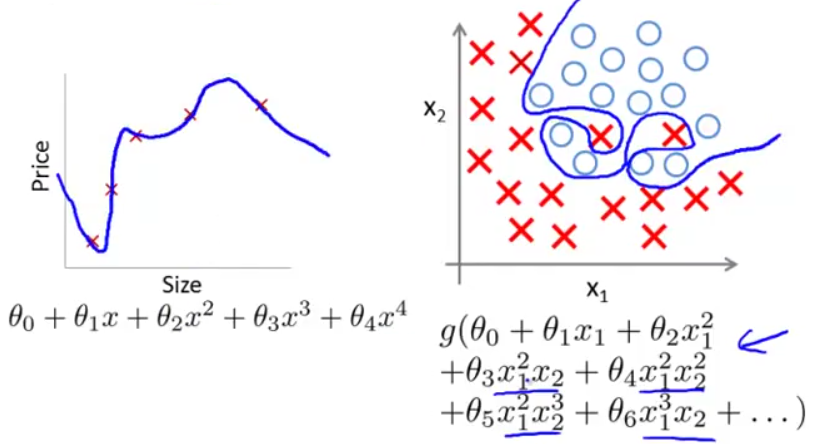
这(过拟合)对于训练数据集来说当然是好的,但我们的最终目的不是让假设函数完美适配训练数据,而是让它去预测新的问题。过拟合带来的问题是假设函数很精准地适配了训练数据,但是却无法泛化到新的例子,对新的输入无法很好地预测其输出。
泛化能力:指一个假设模型能够应用于新样本(没有出现在训练集)的能力。
当我们遇到过拟合(overfitting)问题时,我们应该如何解决呢?
前面通过绘制假设函数曲线我们可以选择合适的多项式阶次,但当特征变量变得很多时,画图本身就变得很难。这里给出两种规避过拟合的方法:
★ 减少特征变量的数量
我们可以人工选择保留或舍弃哪些变量,也可以通过模型选择算法(model selection algorithm)自动选择采用哪种特征变量。
★正则化(regularization)
即,保留所有特征变量,但要减小 θj 的数量级或值。



正则化的两个目标:
① 更好的拟合训练数据,使假设函数很好的适应训练集
② 保持 θ 参数值较小,避免过拟合
正则化参数λ的影:
① λ 如果太小,则相当于正则化项没起到作用,无法控制过拟合;
② λ如果太大,则除了θ0,其余的参数都会约等于0,相当于去掉了那些项,使hθ(x)=θ0,毫无疑问这会得不偿失地导致欠拟合。
(在之后的课程中我们会讲一些择 λ 参数的算法
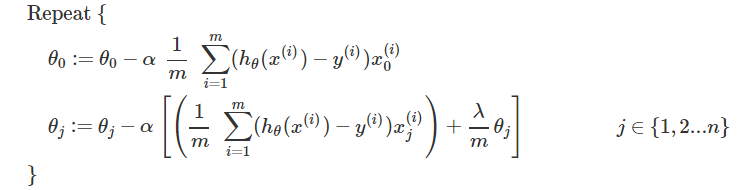
除 θ0外, θj的表达式中,中括号中的部分为对带有正则化项的代价函数 J(θ)求偏导的结果。这个式子还可以写成下面的形式:



L是一个对角线为0,1,1,1,⋯,1,其余全为0的(n+1)×(n+1)维矩阵。事实上,带有正则化的正规方程加上 (λ⋅L) 后,还可解决之前 XTX 不可逆的问题。
利用正则化,即使是在较小的数据集里有很多特征,也可以更好地进行线性回归。
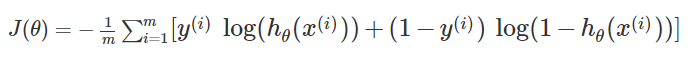
我们可以通过在后面添加如下一项来进行正则化:

带有正则化的梯度下降:

注意,虽然这里,逻辑回归的正则化后梯度下降公式与线性回归相同,但由于假设函数不同,两者并不是一样的。
课程网址:https://www.coursera.org/learn/machine-learning
Week 3 —— Logistic Regression and Regularization
目录
Week 3 Logistic Regression and Regularization目录
一 分类和模型表示
1-1 分类问题
1-2 分类模型的表示
1-3分类决策边界
二 逻辑回归Logistics Regression
2-1 逻辑回归的代价函数cost
2-2 用梯度下降法求解参数theta
2-3 高级优化
三 多分类问题 one vs all
四 过拟合和正则化Overfitting Regularization
4-1 过拟合overfitting
4-2 正则化Regularization
4-3 正则化在线性回归中的应用
4-3-1 带有正则化的梯度下降
4-3-2 带有正则化的正规方程
4-4 正则化在逻辑回归中的应用
一 分类和模型表示
1-1 分类问题
先来谈谈二分类问题。课程中先给出了几个例子。邮件是垃圾邮件还是非垃圾邮件;
网上交易是的欺骗性(Y or N);
肿瘤是恶性的还是良性的。
对于这些问题,我们可以通过输出值y ϵ {0, 1} 来表示。
注意:分类结果是离散值,这是分类的根本特点。
1-2 分类模型的表示
通过上次的课程,我们可以想到利用假设函数y=hθ(x)来预测分类。(1)如果y的取值只有0和1,训练集画出来这这个样子(先没有绿框中的点),我们用线性回归得到1号直线,如果认为模拟直线的取值小于0.5时则预测值就为0,如果模拟直线的取值大于0.5时预测值就为1,感觉还不错。
(2)但是将绿框中的点加入后,线性回归得到的直线2,就显得不是很完美了。经过大量的实验证明,线性回归不适合这种训练集。那么怎么解决这个问题呢?
而且普通的hθ(x)函数存在函数值大于1和小于0的情况(没有意义),于是我们要构造特殊函数使0≤hθ(x)≤1。
对于二类分类问题,y只有两个输出0和1,hθ(x)给出了输出y=1的概率。
用数学表达式表示:
hθ(x)=P(y=1∣x,θ)=1−P(y=0∣x,θ)
1-3分类决策边界
我们可以直观地看出,当(x1,x2)在这条直线的上方,则预测 y=1;当(x1,x2)在这条直线的下方,则预测 y=0。−x1+x2=3这条直线就是这里的决策边界(Decision Boundary)。它将空间分为两个区域,预测y=0和预测y=1。这条直线并不是数据集本身的属性,而是假设函数(hypothesis)和其参数θ的属性。
值得注意的是,logistic 函数g(z)的输入(θTx)并不总是线性的:
上面的决策边界−x1+x2=3属于线性决策边界,再看一个非线性决策边界的例子。假设训练数据的分布如下图所示,则可用高阶多项式进行拟合。
此时的决策边界为一个圆心在原点,半径为1的圆,当(x1,x2)位于圆外部,我们可以预测y=1;当(x1,x2)位于圆内部,我们可以预测y=0。
二 逻辑回归(Logistics Regression)
2-1 逻辑回归的代价函数cost
前面提到决策边界由假设函数和参数θ决定,那么我们如何求解参数θ?在线性回归中,我们利用代价函数(cost function)来求θ,在逻辑回归中仍然适用。我们仍然采用之前的符号定义:
因此,在逻辑回归中,需要另寻一个代价函数,使其是凸函数(单弓形),如下图,这样就可以使用梯度下降法找到全局最小值。
我们选择如下的代价函数来表示单个样本的代价:
这个函数看起来很复杂。下面我们通过画出它的图像来解释选择它的原因。
1、当y=1,Cost(hθ(x),y) 关于hθ(x)的图像:
注意横坐标为hθ(x),而hθ(x)的取值范围为(0,1),所以图像只取(0,1)段。
我们可以看出,当hθ(x)=1,则假设函数预测结果与事实一致,Cost=0;当hθ(x)=0,则预测结果与事实不符,Cost=∞,说明要通过一个很大的代价 Cost→∞ 来惩罚学习算法。
2、当y=1,Cost(hθ(x),y) 关于hθ(x)的图像:
横坐标为hθ(x),而hθ(x)的取值范围为(0,1),所以图像只取(0,1)段。
同理,若y=0,而hθ(x)=1,将通过一个很大的代价 Cost→∞ 来惩罚学习算法。
以上说明在求解参数θ时,当选择合适的代价函数(代价函数转化为一个凸函数),我们就可以将问题转化为凸优化问题(convex optimization problem),方便我们求解全局最小值。
简化代价函数
2-2 用梯度下降法求解参数θ
与线性回归相同,我们的目标是找到使代价函数J(θ)最小的参数θ。回忆我们之前的梯度下降共公式:
我们回忆之前所讲的线性回归中梯度下降的更新公式,你会发现,线性回归和逻辑回归的梯度下降更新公式是一样的。(视频中并未说明为什么,但是推导出的结果确实如此)
但我们需要注意,两个公式中 hθ(x) 是不同的,线性回归中, hθ(x)=θTx,而逻辑回归中,hθ(x)=11+e−θTx,所以两者的梯度下降还是不同的。
梯度下降更新公式用向量表示(代码实现时常用到):
我们之前所讲的梯度下降常见两个问题的解决方法以及特征缩放对于逻辑回归也是适用的,在此不再赘述。
2-3 高级优化
对于梯度下降法我们可以在octive中使用如下高级函数
三 多分类问题: one vs all
这一部分我们主要讲一下如何用逻辑回归解决多类别分类问题。这里,我们采用一种“一对多”(one vs all)的分类算法。举例,一个二类分类问题的数据集分布如下图左所示,一个多类分类问题的数据集分布如下图右所示(用不同的符号表示不同的类别):
在之前所讲的二类分类问题中,我们可以使用逻辑回归用直线将数据集一分为二为正类和负类。那么我们如何用一对多(one vs all)的分类思想解决多分类问题?
用上图右数据集举例说明。图中数据一共有三类,我们可以将其转化为三个二分类问题。在每一个两类分类问题中,把待识别的类别当作正类别,其余合为一类作为负类别。如下图:
总结:
One vs all:
Train a logistic regression classifier h(i)θ(x) for each class to predict the probability that y=i .
To make a prediction on a new x, pick the class that maximizes h(i)θ(x):maxi(h(i)θ(x))
四 过拟合和正则化(Overfitting & Regularization)
前面我们已经讲了线性回归和逻辑回归,它们能够有效地解决许多问题,但当将它们应用于某些特定的机器学习应用时,我们会遇到过拟合问题(overfitting),会导致结果特别差。这一小节内容会为大家解释什么是过拟合问题,并且介绍一种可以改善或减少过度拟合问题的技术——正则化技术( regularization)。
4-1 过拟合(overfitting)
在利用训练数据拟合假设函数时,可能会有如下图三种情况:(1)欠拟合(underfitting)
欠拟合(underfitting)也称为高偏差(high bias)。即,拟合出的假设函数在训练数据集上不能很好地拟合数据, h(i)θ(x)和 y 的偏差比较大,如下图(左为线性回归欠拟合,右为逻辑回归欠拟合)
(2)适度拟合(just right)
即,拟合出的假设函数在训练数据集上能较好的反映输出和输入的关系,hθ(x)和y的偏差不大,如下图(左为线性回归适度拟合,右为逻辑回归适度拟合)
(3)过拟合(overfitting)
过拟合(overfitting)也称为高方差(high variance)。即,由于特征变量太多,导致学习到的假设函数太过适合于训练数据集,甚至J(θ)≈0,导致无法泛化(generalize)到新的数据样本,如下图(左为线性回归过拟合,右为逻辑回归过拟合)。
这(过拟合)对于训练数据集来说当然是好的,但我们的最终目的不是让假设函数完美适配训练数据,而是让它去预测新的问题。过拟合带来的问题是假设函数很精准地适配了训练数据,但是却无法泛化到新的例子,对新的输入无法很好地预测其输出。
泛化能力:指一个假设模型能够应用于新样本(没有出现在训练集)的能力。
当我们遇到过拟合(overfitting)问题时,我们应该如何解决呢?
前面通过绘制假设函数曲线我们可以选择合适的多项式阶次,但当特征变量变得很多时,画图本身就变得很难。这里给出两种规避过拟合的方法:
★ 减少特征变量的数量
我们可以人工选择保留或舍弃哪些变量,也可以通过模型选择算法(model selection algorithm)自动选择采用哪种特征变量。
★正则化(regularization)
即,保留所有特征变量,但要减小 θj 的数量级或值。
4-2 正则化(Regularization)
正则化的两个目标:
① 更好的拟合训练数据,使假设函数很好的适应训练集
② 保持 θ 参数值较小,避免过拟合
正则化参数λ的影:
① λ 如果太小,则相当于正则化项没起到作用,无法控制过拟合;
② λ如果太大,则除了θ0,其余的参数都会约等于0,相当于去掉了那些项,使hθ(x)=θ0,毫无疑问这会得不偿失地导致欠拟合。
(在之后的课程中我们会讲一些择 λ 参数的算法
4-3 正则化在线性回归中的应用
对于线性回归的求解,我们之前推导了两种学习算法:一种基于梯度下降;一种基于正规方程。4-3-1 带有正则化的梯度下降
为了惩罚除了 θ0以外的所有参数,我们将梯度下降的公式修改为如下形式:除 θ0外, θj的表达式中,中括号中的部分为对带有正则化项的代价函数 J(θ)求偏导的结果。这个式子还可以写成下面的形式:
4-3-2 带有正则化的正规方程
我们将输入输出用矩阵和向量表示出来:L是一个对角线为0,1,1,1,⋯,1,其余全为0的(n+1)×(n+1)维矩阵。事实上,带有正则化的正规方程加上 (λ⋅L) 后,还可解决之前 XTX 不可逆的问题。
利用正则化,即使是在较小的数据集里有很多特征,也可以更好地进行线性回归。
4-4 正则化在逻辑回归中的应用
回忆我们之前讲的逻辑回归的代价函数:我们可以通过在后面添加如下一项来进行正则化:
带有正则化的梯度下降:
注意,虽然这里,逻辑回归的正则化后梯度下降公式与线性回归相同,但由于假设函数不同,两者并不是一样的。

相关文章推荐
- Coursera-吴恩达-机器学习-(第1周笔记)Introduction and Linear Regression
- coursera-斯坦福-机器学习-吴恩达-第6周笔记-算法改进and机器学习系统设计
- coursera-斯坦福-机器学习-吴恩达-第3周笔记-逻辑回归
- coursera机器学习笔记之“Bayesian statistics and Regularization”
- Coursera台大机器学习技法课程笔记05-Kernel Logistic Regression
- Coursera-吴恩达-机器学习-(第2周笔记)Linear Regression with Multiple Variables
- 3、机器学习-Logistic Regression and Regularization
- [机器学习笔记]二:Classification and logistic regression(分类和逻辑回归)
- Coursera公开课笔记: 斯坦福大学机器学习第七课“正则化(Regularization)”
- Coursera公开课笔记: 斯坦福大学机器学习第七课“正则化(Regularization)”
- 吴恩达Coursera深度学习课程 DeepLearning.ai 提炼笔记(3-1)-- 机器学习策略(1)
- 吴恩达Coursera机器学习课程笔记-定义分类
- 林轩田--机器学习技法--SVM笔记5--核逻辑回归(Kernel+Logistic+Regression)
- coursera 吴恩达 -- 第一课 神经网络和深度学习 :第二周课后习题 Logistic Regression with a Neural Network mindset
- Stanford机器学习-- 逻辑回归和过拟合问题的解决 logistic Regression & Regularization
- Coursera-吴恩达-机器学习-(编程练习5)Bias and Variance(对应第6周课程)
- Coursera-吴恩达-机器学习-(第10周笔记)大数据训练
- 课程笔记|吴恩达Coursera机器学习 Week1 笔记-机器学习基础
- 斯坦福CS229机器学习课程笔记 part2:分类和逻辑回归 Classificatiion and logistic regression
- 吴恩达机器学习笔记2-Linear_Regression_with_One_Variable