IntelliJ IDEA + Maven环境编写第一个hadoop程序
2018-01-10 19:25
531 查看
1. 新建IntelliJ下的maven项目
点击File->New->Project,在弹出的对话框中选择Maven,JDK选择你自己安装的版本,点击Next
2. 填写Maven的
你可以根据自己的项目随便填,点击
这样就新建好了一个空的项目
这里程序名填写WordCount,我们的程序是一个通用的网上的范例,用来计算文件中单词出现的次数
3. 设置程序的编译版本
打开Intellij的Preference偏好设置,定位到Build, Execution, Deployment->Compiler->Java Compiler,
将WordCount的Target bytecode version修改为你的jdk版本(我的是1.8)
4. 配置依赖
编辑pom.xml进行配置
1) 添加apache源
在
2) 添加hadoop依赖
这里只需要用到基础依赖hadoop-core和hadoop-common;如果需要读写HDFS,
则还需要依赖hadoop-hdfs和hadoop-client;如果需要读写HBase,则还需要依赖hbase-client
在
4000
加
修改pom.xml完成后,Intellij右上角会提示Maven projects need to be Imported,点击Import Changes以更新依赖,或者点击Enable Auto Import
最后,我的完整的pom.xml如下:
5. 编写主程序
WordCount.java
6. 配置输入和输出结果文件夹
1) 添加和src目录同级的input文件夹到项目中
在input文件夹中放置一个或多个输入文件源
我的输入文件源如下:
test.segmented:
dfdfadgdgag
aadads
fudflcl
cckcer
fadf
dfdfadgdgag
fudflcl
fuck
fuck
fuckfuck
haha
aaa
2) 配置运行参数
在Intellij菜单栏中选择Run->Edit Configurations,在弹出来的对话框中点击+,新建一个Application配置。配置Main class为WordCount(可以点击右边的...选择),
Program arguments为input/ output/,即输入路径为刚才创建的input文件夹,输出为output
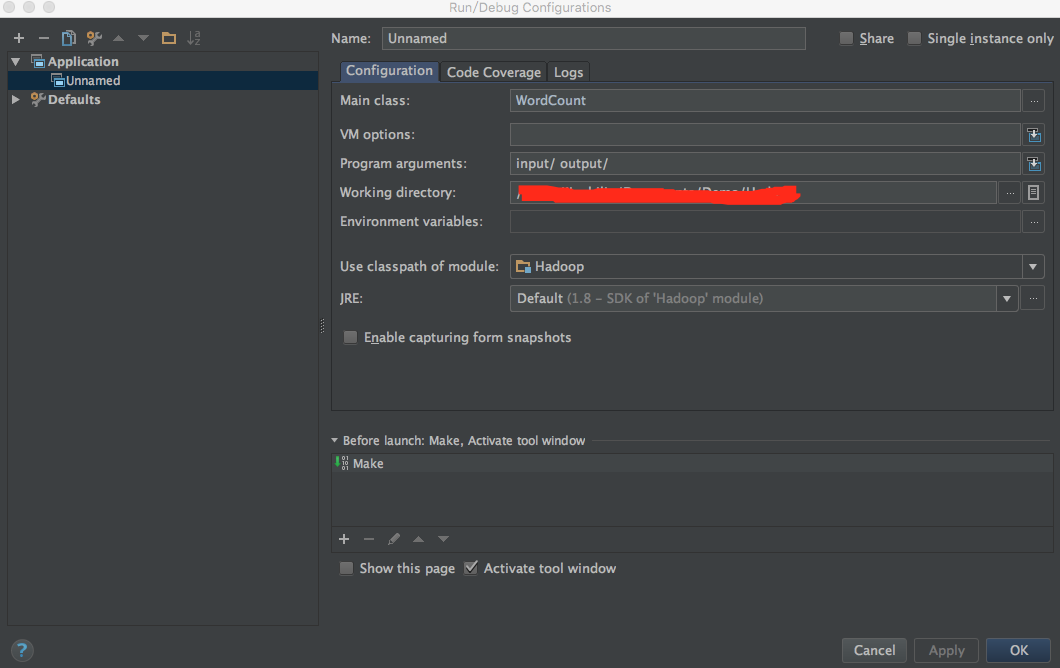
由于Hadoop的设定,下次运行时务必删除
好了,运行程序,结果如下:
aaa 1
aadads 1
cckcer 1
dfdfadgdgag 2
fadf 1
fuck 2
fuckfuck 1
fudflcl 2
haha 1
至此,一个简单的hadoop程序完成!
点击File->New->Project,在弹出的对话框中选择Maven,JDK选择你自己安装的版本,点击Next
2. 填写Maven的
GroupId和
ArtifactId
你可以根据自己的项目随便填,点击
Next
这样就新建好了一个空的项目
这里程序名填写WordCount,我们的程序是一个通用的网上的范例,用来计算文件中单词出现的次数
3. 设置程序的编译版本
打开Intellij的Preference偏好设置,定位到Build, Execution, Deployment->Compiler->Java Compiler,
将WordCount的Target bytecode version修改为你的jdk版本(我的是1.8)
4. 配置依赖
编辑pom.xml进行配置
1) 添加apache源
在
project内尾部添加
<repositories> <repository> <id>apache</id> <url>http://maven.apache.org</url> </repository> </repositories>
2) 添加hadoop依赖
这里只需要用到基础依赖hadoop-core和hadoop-common;如果需要读写HDFS,
则还需要依赖hadoop-hdfs和hadoop-client;如果需要读写HBase,则还需要依赖hbase-client
在
project内尾部添
4000
加
<dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-core</artifactId> <version>1.2.1</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.7.2</version> </dependency> </dependencies>
修改pom.xml完成后,Intellij右上角会提示Maven projects need to be Imported,点击Import Changes以更新依赖,或者点击Enable Auto Import
最后,我的完整的pom.xml如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion>
<groupId>com.fun</groupId>
<artifactId>hadoop</artifactId>
<version>1.0-SNAPSHOT</version>
<repositories> <repository> <id>apache</id> <url>http://maven.apache.org</url> </repository> </repositories>
<dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-core</artifactId> <version>1.2.1</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.7.2</version> </dependency> </dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-dependency-plugin</artifactId>
<configuration>
<excludeTransitive>false</excludeTransitive>
<stripVersion>true</stripVersion>
<outputDirectory>./lib</outputDirectory>
</configuration>
</plugin>
</plugins>
</build>
</project>
5. 编写主程序
WordCount.java
/**
* Created by jinshilin on 16/12/7.
*/
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}6. 配置输入和输出结果文件夹
1) 添加和src目录同级的input文件夹到项目中
在input文件夹中放置一个或多个输入文件源
我的输入文件源如下:
test.segmented:
dfdfadgdgag
aadads
fudflcl
cckcer
fadf
dfdfadgdgag
fudflcl
fuck
fuck
fuckfuck
haha
aaa
2) 配置运行参数
在Intellij菜单栏中选择Run->Edit Configurations,在弹出来的对话框中点击+,新建一个Application配置。配置Main class为WordCount(可以点击右边的...选择),
Program arguments为input/ output/,即输入路径为刚才创建的input文件夹,输出为output
由于Hadoop的设定,下次运行时务必删除
output文件夹!
好了,运行程序,结果如下:
aaa 1
aadads 1
cckcer 1
dfdfadgdgag 2
fadf 1
fuck 2
fuckfuck 1
fudflcl 2
haha 1
至此,一个简单的hadoop程序完成!

相关文章推荐
- IntelliJ IDEA + Maven环境编写第一个hadoop程序
- IntelliJ IDEA + Maven环境编写第一个hadoop程序
- Hadoop: Intellij结合Maven本地运行和调试MapReduce程序 (无需搭载Hadoop和HDFS环境)
- 一起学Hadoop——使用IDEA编写第一个MapReduce程序(Java和Python)
- Hadoop实践(二)---集群和开发环境搭建(Intellij IDEA & Maven 开发Hadoop)
- win8下用Maven构建hadoop环境编写MapReduce程序
- Spring学习之第一个Spring MVC程序(IDEA开发环境)
- Maven项目管理(一) IntelliJ Idea+Maven环境搭建与基于命令行的基本使用
- 搭建Spring开发环境并编写第一个Spring小程序
- Eclipse里编写第一个Hadoop程序
- 用IDEA编写第一个Spring入门程序
- IntelliJ IDEA+maven+perforce+tomcat部署(web环境搭建)
- 在Idea编辑器下编写第一个Hibernate5.x程序。
- Intellij IDEA使用Maven搭建spark开发环境(scala)
- hadoop+intellij+maven实现wordcount程序
- springMVC+maven+mybatis+Intellij IDEA环境搭建
- 学海拾遗:使用idea编写你的第一个java web程序
- Intellij IDEA + Spring MVC + Maven 环境搭建
- IntelliJ IDEA的JDK环境配置和Maven依赖管理
- 搭建和编写第一个maven程序