selenium + java po模式
2018-01-10 11:00
435 查看
po模式大概介绍,大家也可以自己百度看看
Page Object模式主要是将每个页面设计为一个类class,这个类包含页面中需要测试的元素(按钮、输入框、URL、标题等)和实际操作方法,这样在写测试用例时可以通过调用页面类的方法和属性来获取页面元素和操作元素,这样优点是避免当页面元素的ID或位置改变时需要更改测试用例代码的情况。当页面元组定位发生改变时只要通过更改页面类的属性即可。
框架目录结构
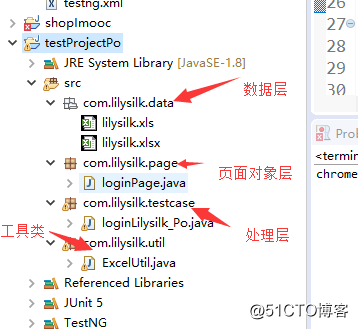
loginPage.java
case层即处理层
loginLilysilk_Po.java
工具类
ExcelUtil.java
data层即数据层
遇到的问题:
问题1:org.apache.poi.openxml4j.exceptions.OLE2NotOfficeXmlFileException: The supplied data appears to be in the OLE2 Format. You are calling the part of POI that deals with OOXML (Office Open XML) Documents. You need to call a different part of POI to process this data (eg HSSF instead of XSSF)

像这个报错就是所用的XSSF是支持excel2007版本以上的,支持格式为xlsx,如果想要支持2003版本的xls,需要将XSSF换成HSSF的
问题2:部分jar包没有,需要导入,按照报错内容导入jar包就好
Page Object模式主要是将每个页面设计为一个类class,这个类包含页面中需要测试的元素(按钮、输入框、URL、标题等)和实际操作方法,这样在写测试用例时可以通过调用页面类的方法和属性来获取页面元素和操作元素,这样优点是避免当页面元素的ID或位置改变时需要更改测试用例代码的情况。当页面元组定位发生改变时只要通过更改页面类的属性即可。
框架目录结构
loginPage.java
package com.lilysilk.page;
import org.apache.poi.util.SuppressForbidden;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.support.FindBy;
/**
* 定位语句与测试代码封装
* */
public class loginPage {
//登录页面
@FindBy(className="touXiang")
private WebElement uloginPage;
//用户名输入框
@FindBy(xpath="//div[@class='userLogin']/div[1]/input[@id='email']")
private WebElement uName;
//密码输入框
@FindBy(xpath="//div[@class='userLogin']/div[2]/input[@id='password']")
private WebElement uPwd;
//登录按钮
@FindBy(id="loginButton")
private WebElement loginBtn;
//点击跳转登录页面
public void goLoginPage() {
uloginPage.click();
}
//输入用户名
public void loginName(String username) {
System.out.println(username);
uName.clear();
uName.sendKeys(username);
}
//输入密码
public void loginPwd(String password) {
System.out.println(password);
uPwd.clear();
uPwd.sendKeys(password);
}
//点击登录
public void loginBtn() {
loginBtn.click();
}
}case层即处理层
loginLilysilk_Po.java
package com.lilysilk.testcase;
import java.util.concurrent.TimeUnit;
import org.junit.*;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
import org.openqa.selenium.firefox.FirefoxDriver;
import org.openqa.selenium.support.PageFactory;
import org.testng.annotations.AfterMethod;
import org.testng.annotations.BeforeMethod;
import com.lilysilk.page.loginPage;
import com.lilysilk.util.ExcelUtil;
public class loginLilysilk_Po {
public static WebDriver driver;
@Test
public void loginlily() throws Exception{
//定义测试用例路径
String excelPath="E:\\javaDemo\\testProjectPo\\src\\com\\lilysilk\\data\\lilysilk.xlsx";
//读取测试用例sheet页
ExcelUtil.setExcelFile(excelPath,"login");
//打开浏览器
String BrowserName=ExcelUtil.getCellData(1,4);
//修改浏览器语言
ChromeOptions op=new ChromeOptions();
op.addArguments("--lang=en-US");
//equals比较时,要比较大小写是否相同,equalsIgnoreCase,忽略了大小写,ignore就是忽略的意思
if(BrowserName.equalsIgnoreCase("chrome")){
//初始化浏览器实例
driver=new ChromeDriver(op);
}else {
driver=new FirefoxDriver(op);
}
//浏览器最大化
driver.manage().window().maximize();
//打开网址
driver.get(ExcelUtil.getCellData(2, 4));
//初始化page页面(注意:要放在打开浏览器之后)
loginPage loginPage=PageFactory.initElements(driver, loginPage.class);
loginPage.goLoginPage();
loginPage.loginName("112233@qq.com");
loginPage.loginPwd("112233@qq.com");
loginPage.loginBtn();
}
@BeforeMethod
public static void beforeMethod(){
}
@AfterMethod
public static void afterMethod(){
driver.close();
}
}工具类
ExcelUtil.java
package com.lilysilk.util;
import java.io.FileInputStream;
import org.apache.poi.xssf.usermodel.XSSFCell;
import org.apache.poi.xssf.usermodel.XSSFSheet;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
/**
*
*@Comments : 导入导出Excel工具类
*此类事实现操作指定的excel文件中的指定sheet页、
*读取指定的单元格内容、获取sheet中最后一行的行号的功能
*
*
**/
public class ExcelUtil {
private static XSSFSheet ExcelWSheet;
private static XSSFWorkbook ExcelWBook;//excel文件对象
private static XSSFCell ExcelCell;//单元格对象
//舍得需要操作的excel的文件路径和sheet名称
//在读,写excel文件时,均需先调用此方法,设定要操作的excel的路径和sheet名称
public static void setExcelFile(String Path,String SheetName) {
FileInputStream ExcelFile;
try {
//实例化excel文件的FileInputStream对象
ExcelFile=new FileInputStream(Path);
//实例化EXCEL文件的execlWXSSFWorkbook对象
ExcelWBook =new XSSFWorkbook(ExcelFile);
//实例化 XSSFCell 对象,指定excel文件中的sheet名称,后续用于sheet中行、列和单元格的操作
ExcelWSheet=ExcelWBook.getSheet(SheetName);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
/**
* @param rowNum行 colNum列
**/
//读取excel文件中指定的单元格的函数,此函数只支持扩展名为.xlsx的excel文件
public static String getCellData(int rowNum,int colNum)throws Exception {
try {
//通过函数参数知道单元格的行号与列号,获取指定的单元格对象
ExcelCell=ExcelWSheet.getRow(rowNum).getCell(colNum);
//如果单元格的内容为字符串类型,则使用getStringCellValue方法来获取单元格内容
//如果单元格的内容为数字类型, 则使用getNumericCellValue方法来获取单元格内容
String CellData =ExcelCell.getCellType()==XSSFCell.CELL_TYPE_STRING?ExcelCell.getStringCellValue()+"":String.valueOf(Math.round(ExcelCell.getNumericCellValue()));
return CellData;
}
catch(Exception e){
e.printStackTrace();
//读取遇到异常,则返回空字符串
return "错了";
}
}
//获取excel文件的最后一行的行号
public static int getLastRowNum() {
//函数返回sheet的最后一行行号
return ExcelWSheet.getLastRowNum();
}
}data层即数据层
遇到的问题:
问题1:org.apache.poi.openxml4j.exceptions.OLE2NotOfficeXmlFileException: The supplied data appears to be in the OLE2 Format. You are calling the part of POI that deals with OOXML (Office Open XML) Documents. You need to call a different part of POI to process this data (eg HSSF instead of XSSF)
像这个报错就是所用的XSSF是支持excel2007版本以上的,支持格式为xlsx,如果想要支持2003版本的xls,需要将XSSF换成HSSF的
问题2:部分jar包没有,需要导入,按照报错内容导入jar包就好

相关文章推荐
- [Android测试] AS+Appium+Java+Win 自动化测试之九:PO模式的实例与ReportNg测试报告
- Appium+Java+PO+testng 设计模式
- Selenium的PO模式(Page Object Model)|(Selenium Webdriver For Python)
- java+selenium自动化测试 ——pageobject模式
- Selenium的PO模式(Page Object Model)[python版]
- Python3-Selenium3使用PO设计模式(Page Object)实现简单的页面登录操作
- Selenium Page Object(PO)设计模式
- Selenium的PO模式
- Selenium的PO模式(Page Object Model)|(Selenium Webdriver For Python)
- Python Selenium设计模式 - PO设计模式
- Selenium的PO模式(Page Object Model)[python版]
- selenium+Java等待模式(显式等待+隐式等待)
- JAVA 正则表达式的三种模式: 贪婪, 勉强和占有的讨论
- java 单例模式
- java设计模式总结篇--行为型模式(1)
- javaDB两种网络模式
- Java-DAO模式
- Java设计模式圣经连载之(00)-前言
- Java设计模式——装饰者模式
- java设计模式之组合模式