详解KMP字符串匹配算法
2018-01-09 17:15
225 查看
字符串匹配
字符串匹配一般是指在较长的一个字符串A中查找是否含有较短字符串B、B在A中的位置的过程。最容易想到、也是最长用的一种办法是暴力匹配。String.contains() 用的就是这种方法,应该说这种简单的方法用的还是特广泛的。
KMP算法
KMP算法俗称“看毛片”算法,通过计算next[] 数组的方法加速匹配过程。
next[] 数组:
首先要明白几个概念,字符串中的字符的前置字符串(如果有),后置字符串。很容易理解,前置字符串就是这个字符前面的一段字符串、后置字符串就是这个字符后面的一串字符串。
next[i] 数组的定义,它反映的是i位置上的字符串,它的前置字符串的最长相同的前缀和后缀字符串的长度。前置字符串应该不陌生,上面图像中 “abcdksid” 就是字符“g”的前置字符串,最长相同前缀和后缀字符串的长度,因为“abcdksid”没有相同的前缀和后缀,所有g处next[]的值为0。例如,“abcdabc”,为3,“abcdefa”,为1。
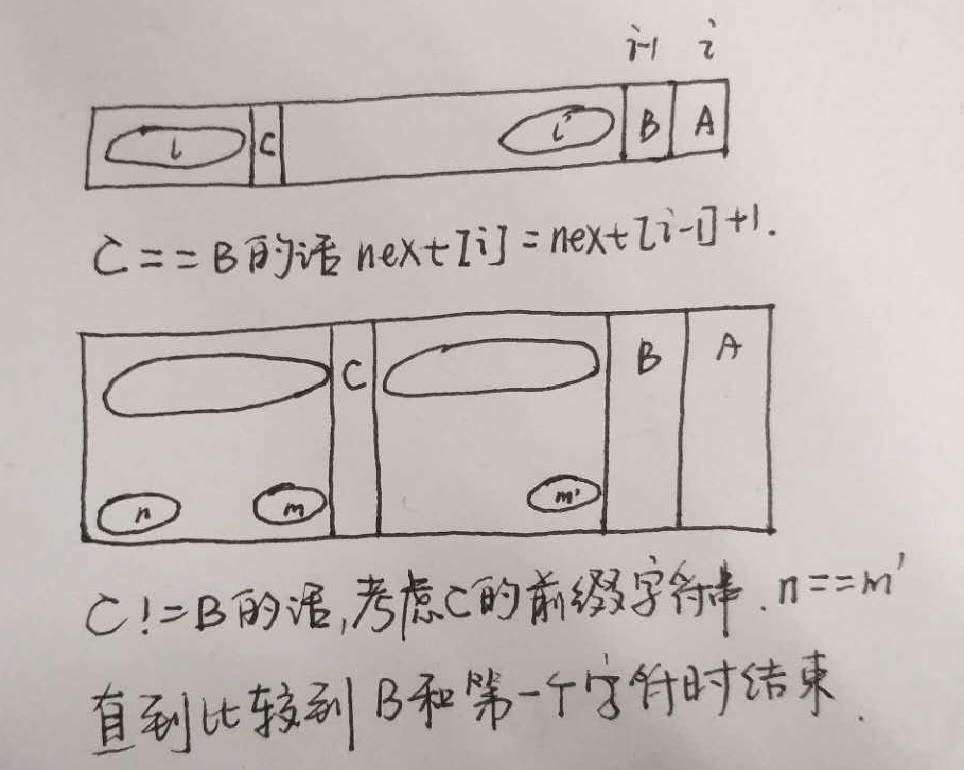
next[i]数组的计算。它是通过遍历该字符串的每个位置,算出每个位置处的值。第0个字符因为没有前缀字符串,定义next[0]=-1; 第1个字符因为其前缀字符串只有一个字符,next数组的定义要求任何子串的后缀不能包括第一个字符,也就是说没有所谓的相同的前缀字符串和后缀字符串,该处的值也定义为0,next[1]=0。后续next[i]值的计算,是根据前面位置处next[0] – next[i-1]的值计算出来的,如果str[i-1]==str[next[i-1]],则next[i]=next[i-1]+1。否则,比较str[i-1]与str[next[next[i-1]]]。形象说明可以参考下图:
具体代码如下:
public static int[] getNextArray(char[] ms){
if(ms.length==1){
return new int[] {-1};
}
int[] next=new int[ms.length];
next[0]=-1;
next[1]=0;
int pos=2;
int cn=0;
while(pos<next.length){
if(ms[pos-1]==ms[cn]){
next[pos++]=++cn;
}else if(cn>0){
cn=next[cn];
}else{
next[pos++]=0;
}
}
return next;
}这里cn一直指向可能最长相同字符串的最后一个字母。左老师这段代码相当精髓。
KMP遍历方法:
求出next数组之后,就可以根据next数组的值,在待匹配字符串上进行快速匹配。和暴力字符串匹配方法(String.contains()就是用的暴力匹配)类似,只不过运用到了next数组的值,跳过了一些匹配环节。这里最关键的一个问题是,为什么在跳过的那部分匹配中不可能找到相匹配的字符串。具体证明可以用下面的图说明,证明运用了反证法(有很多问题正面证明有困难的时候,往往反证法就会比较有用了)。
上图是一次匹配过程,目的是在上面字符串中找到下面字符串所在的位置(如果有的话),第一次匹配的时候,在A,B处发现匹配失败,也就是说A、B前面的字符串都是相同的。KMP算法会直接向右移动A处next值的长度进行下一次匹配,现在来证明这个的合理性。假设向右移动x字符串长度的位置(小于A处next值),根据上图的推理得出矛盾。
具体代码如下:
public int getIndexOf(String s,String m){
if(s==null || m==null || m.length()<1 || s.length()<m.length()){
return -1;
}
char[] ss=s.toCharArray();
char[] ms=m.toCharArray();
int si=0;
int mi=0;
int[] next=getNextArray(ms);
while(si<ss.length&&mi<ms.length){
if(ss[si]==ms[mi]){
si++;
mi++;
}else if(next[mi]==-1){
si++;
}else{
mi=next[mi];
}
}
return mi==ms.length? si-mi:-1;
}(特别感谢 左程云 老师,他讲的算法特别透彻)
