Spark技术架构,概念及运行过程
2018-01-07 23:51
489 查看
Spark技术架构
Spark的基本概念
1 Application
2 Job
3 Stage和DAGSchedule
4 Task和TaskSchedule
5 BlockManager
6 宽依赖与窄依赖
运行过程
1 Standalone
2 yarn cluster
Master作为整个集群的控制器,负责整个集群的正常运行,Worker则相当于是计算节点,接收主节点的命令,运行Driver或Excutor,并进行状态汇报;Executor运行在Worker节点。
在Yarn运行框架下,由Yarn的ResourceManager担任Master,Excutor则运行在NodeManager的Container中。
Spark的提交运行流程:Spark作业在提交运行时,会指定master和deploy-mode两个参数,共同决定了是standalone还是yarn/mesos资源管理托管模式。
master参数包括:spark://host:port, mesos://host:port, yarn, yarn-cluster,yarn-client, local,默认为local[*]
deploy-mode参数取值为client和cluster,分别意味着driver程序运行在哪里,默认为client
master取值local
:单机运行 spark://xxx在指定集群上运行 yarn则为运行在yarn集群中,yarn-cluster和yarn-client在spark2.0已经不推荐使用了,需要通过master和deploy-mode共同指定
Spark的任务流程:
Created with Raphaël 2.1.2Client作为客户端提交应用[Master]找到一个Worker启动Driver(或者本地启动Driver)[Driver]向Master申请资源,之后将应用转化为RDD Graph[DAGScheduler]将RDD Graph转化为Stage后提交给TaskScheduler[TaskScheduler]提交给Executor执行结束
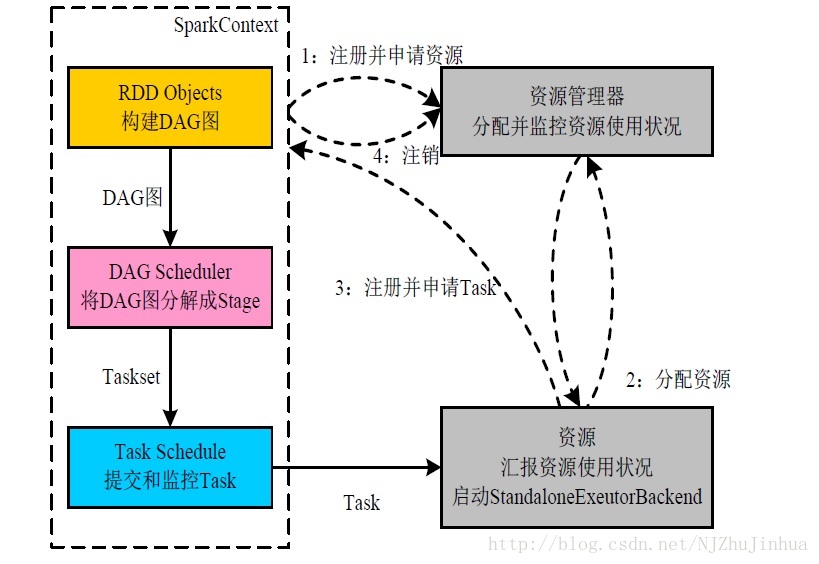
SparkContext向资源管理器(Standalone的Master)申请运行Executor资源,并启动StandaloneExecutorBackend
Executor向SparkContext注册
SparkContext启动应用程序DAG调度、Stage划分,TaskSet生成
TaskScheduler调度Taskset,将task发放给Executor运行。
Task在Executor上运行,运行完毕释放所有资源。
Spark的基本概念
1 Application
2 Job
3 Stage和DAGSchedule
4 Task和TaskSchedule
5 BlockManager
6 宽依赖与窄依赖
运行过程
1 Standalone
2 yarn cluster
1.Spark技术架构
Spark分布式内存计算平台采用的是Master-Slave架构,集群中含有Master进程的节点ClusterManager即为这里的Master,而Slave则是集群中的Work进程节点。Master作为整个集群的控制器,负责整个集群的正常运行,Worker则相当于是计算节点,接收主节点的命令,运行Driver或Excutor,并进行状态汇报;Executor运行在Worker节点。
在Yarn运行框架下,由Yarn的ResourceManager担任Master,Excutor则运行在NodeManager的Container中。
Spark的提交运行流程:Spark作业在提交运行时,会指定master和deploy-mode两个参数,共同决定了是standalone还是yarn/mesos资源管理托管模式。
master参数包括:spark://host:port, mesos://host:port, yarn, yarn-cluster,yarn-client, local,默认为local[*]
deploy-mode参数取值为client和cluster,分别意味着driver程序运行在哪里,默认为client
master取值local
:单机运行 spark://xxx在指定集群上运行 yarn则为运行在yarn集群中,yarn-cluster和yarn-client在spark2.0已经不推荐使用了,需要通过master和deploy-mode共同指定
// Set the cluster manager
val clusterManager: Int = args.master match {
case "yarn" => YARN
//yarn-client和yarn-cluster已不推荐使用
case "yarn-client" | "yarn-cluster" =>
printWarning(s"Master ${args.master} is deprecated since 2.0." +
" Please use master \"yarn\" with specified deploy mode instead.")
//当前真要用了其实还是当做YARN来对待
YARN
//spark://xxx 对应到STANDALONE
case m if m.startsWith("spark") => STANDALONE
case m if m.startsWith("mesos") => MESOS
case m if m.startsWith("local") => LOCAL
case _ =>
printErrorAndExit("Master must either be yarn or start with spark, mesos, local")
-1
}
// Set the deploy mode; default is client mode
var deployMode: Int = args.deployMode match {
case "client" | null => CLIENT
case "cluster" => CLUSTER
case _ => printErrorAndExit("Deploy mode must be either client or cluster"); -1
}Spark的任务流程:
Created with Raphaël 2.1.2Client作为客户端提交应用[Master]找到一个Worker启动Driver(或者本地启动Driver)[Driver]向Master申请资源,之后将应用转化为RDD Graph[DAGScheduler]将RDD Graph转化为Stage后提交给TaskScheduler[TaskScheduler]提交给Executor执行结束
2.Spark的基本概念
2.1 Application
用户写的spark程序,提交后为一个App,一个App内仅有一个SparkContext,此即App的Driver,驱动着整个App的执行。2.2 Job
一个App内有多个Action算子,这些action算子触发了RDD/Dataset的转换,每个action对应着一个Job2.3 Stage和DAGSchedule
Job的执行过程中根据shuffle的不同,分成了宽依赖和窄依赖,DAGSchedule据此讲Job分成了不同的Stage,并将其提交给TaskSchedule执行2.4 Task和TaskSchedule
Task为具体执行任务的基本单位,被TaskSchedule分发到excutor上执行2.5 BlockManager
管理App运行过程中的中间数据,如内存磁盘等,cache/persist等的管理均通过BlockManager进行维护2.6 宽依赖与窄依赖
RDD/DF等内存块均是只读的,RDD的生成(除最初创建)靠的也是老RDD的转换,所以RDD间通过这些依赖产生了关系。如果一个父RDD的每个分区只被子RDD的一个分区依赖,那这是窄依赖,相反如果子RDD的任意个分区的生成都依赖父RDD的每个分区,则为宽依赖。显而易见,宽依赖影响很大。而在连续的多个窄依赖间因都是在同一个分区内,所以可连续多次处理而不用写磁盘提高效率。DAG的Stage划分也据此讲一个Job划分为了多个Stage,保证在每个Stage内是窄依赖。3. 运行过程
3.1 Standalone
构建SparkApplication的运行环境(启动SparkContext)SparkContext向资源管理器(Standalone的Master)申请运行Executor资源,并启动StandaloneExecutorBackend
Executor向SparkContext注册
SparkContext启动应用程序DAG调度、Stage划分,TaskSet生成
TaskScheduler调度Taskset,将task发放给Executor运行。
Task在Executor上运行,运行完毕释放所有资源。
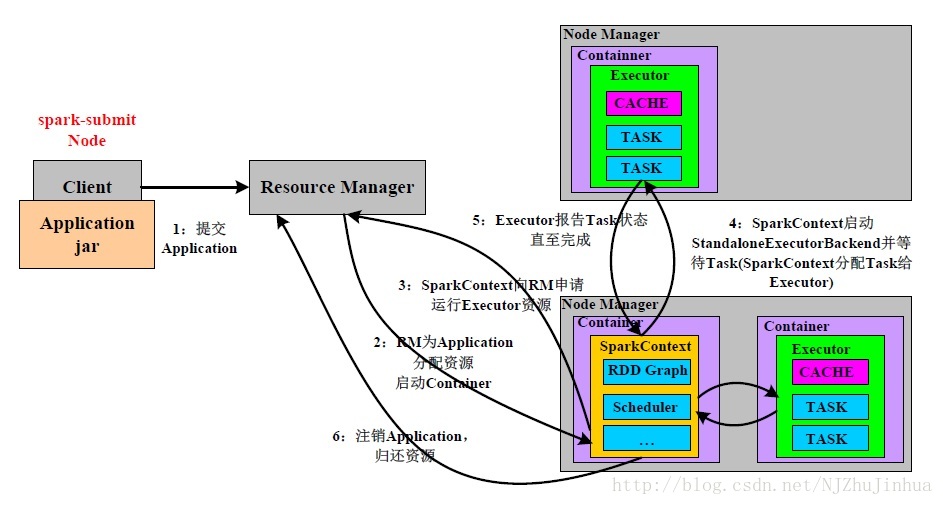
3.2 yarn cluster
图中已经很清楚了

相关文章推荐
- Spark1.0.0 运行架构基本概念
- Spark1.0.0 运行架构基本概念
- Spark1.0.0 运行架构基本概念
- Spark开发-运行架构基本概念
- Spark1.0.0 运行架构基本概念
- Spark1.0.0 运行架构基本概念
- Spark Standalone运行过程
- Spark入门实战指南——Spark运行架构
- 大型网站技术架构演变过程
- 大型网站技术架构演变过程
- Spark 2.2.0 SQL的运行过程(源码解密)
- sparkSQL1.1入门之二:sparkSQL运行架构
- 通过案例对SparkStreaming 透彻理解三板斧之三:解密SparkStreaming运行机制和架构进阶
- spark应用程序的运行架构
- 定制班第二课 -----通过案例对Spark Streaming透彻理解三板斧之二:解密SparkStreaming运行机制和架构
- Spark on YARN客户端模式作业运行全过程分析
- 从概念到底层技术,一文看懂区块链架构设计(附知识图谱)
- 第104讲: Spark Streaming电商广告点击综合案例需求分析和技术架构
- Spark运行架构
- Spark运行架构