Backpropagation Algorithm Implementation
2018-01-06 23:02
369 查看
数据来源:http://yann.lecun.com/exdb/mnist/
以下代码实现了一个三层的神经网络,其激活函数为sigmod function。笔者运行了多次都遇到了sigmod梯度消失,模型预测效果蛮差。读者也可试试其它激活函数。阅读本程序可助于深入理解神经网络和反向传播算法。
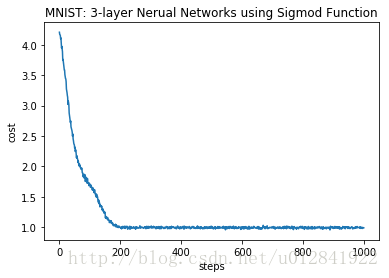
以下代码实现了一个三层的神经网络,其激活函数为sigmod function。笔者运行了多次都遇到了sigmod梯度消失,模型预测效果蛮差。读者也可试试其它激活函数。阅读本程序可助于深入理解神经网络和反向传播算法。
import os
import numpy as np
import random
from mnist import MNIST
fro
4000
m sklearn.preprocessing import LabelBinarizer
mndata = MNIST('mnist/')
training_images, training_labels = mndata.load_training()
training_labels = LabelBinarizer().fit_transform(np.array(training_labels))
training_images = np.array(training_images)
training_images = training_images/255
testing_images, testing_labels = mndata.load_testing()
testing_labels = LabelBinarizer().fit_transform(np.array(testing_labels))
testing_images = np.array(testing_images)
testing_images = testing_images/255def sigmod(x):
return 1/(1+np.exp(-x))
def linear_act(x):
return x
def d_sigmod(y):
return y*(1-y)
def d_linear_act(x):
x[True] = 1
return x
class NerualNetwork():
def __init__(self,layers,lr=0.1):
self.layers = layers
self.num_of_layers = np.shape(layers)[0]
self.lr = lr
self.W = [np.nan]
self.b = [np.nan]
self.a_last = np.array([])
for i in range(self.num_of_layers-1):
self.W.append(np.random.random((layers[i+1],layers[i]))*2-1)
self.b.append(np.random.random((layers[i+1],1))*2-1)
def forword_propagation(self,X):
s = [np.nan]
a = [X]
for l in range(1,self.num_of_layers-1):
s.append(np.dot(self.W[l],a[l-1])+self.b[l])
a.append(sigmod(s[l]))
s.append(np.dot(self.W[self.num_of_layers-1],a[self.num_of_layers-2])+self.b[self.num_of_layers-1])
a.append(sigmod(s[self.num_of_layers-1]))
return s,a
def predict(self,X):
s,a = self.forword_propagation(X)
prediction = a[-1]
return prediction
def back_propagation(self,s,a,Y):
d_a_last = -2*(Y-a[-1])/self.layers[-1]
d_s_last = np.dot(np.diag(d_sigmod(a[-1][:,0])), d_a_last[:,0].reshape(10,1))
for m in range(1,np.shape(Y)[1]):
d_s_last = np.append(d_s_last,
np.dot(np.diag(d_sigmod(a[-1][:,m])), d_a_last[:,m].reshape(10,1)), 1)
ds = [d_s_last]
for i in list(reversed(range(self.num_of_layers-2))):
d_s_hide = np.dot(np.diag(d_sigmod(a[i+1][:,0])),
np.dot(self.W[i+2].T,ds[-1][:,0].reshape(self.layers[i+2],1)))
for m in range(1,np.shape(Y)[1]):
d_s_hide = np.append(d_s_hide,
np.dot(np.diag(d_sigmod(a[i+1][:,m])),
np.dot(self.W[i+2].T,ds[-1][:,m].reshape(self.layers[i+2],1))), 1)
ds.append(d_s_hide)
ds.append(np.nan)
ds = list(reversed(ds))
with open('ds.txt','a') as f_ds:
for l in range(1,self.num_of_layers):
f_ds.write('\nLayer '+str(l)+'\n')
f_ds.write('\nds:'+str(np.shape(ds[l]))+'\n')
f_ds.write(str(ds[l])+'\n')
self.update_param(a,ds)
def update_param(self,a,ds):
for i in range(1,self.num_of_layers):
sum_of_gradient_w = np.dot(ds[i][:,0].reshape(self.layers[i],1),
a[i-1][:,0].reshape(self.layers[i-1],1).T)
sum_of_gradient_b = ds[i][:,0].reshape(self.layers[i],1)
for m in range(1,np.shape(ds[i])[1]):
sum_of_gradient_w += np.dot(ds[i][:,m].reshape(self.layers[i],1),
a[i-1][:,m].reshape(self.layers[i-1],1).T)
sum_of_gradient_b += ds[i][:,m].reshape(self.layers[i],1)
self.W[i] -= self.lr*sum_of_gradient_w/(np.shape(ds[i])[1])
self.b[i] -= self.lr*sum_of_gradient_b/(np.shape(ds[i])[1])
def train(self,X,Y,epochs=10000, batch_size=500):
if os.path.isfile('parameters.txt'):
os.remove('parameters.txt')
if os.path.isfile('activations.txt'):
os.remove('activations.txt')
if os.path.isfile('costs.txt'):
os.remove('costs.txt')
if os.path.isfile('ds.txt'):
os.remove('ds.txt')
for i in range(epochs):
sample_index = random.sample(list(range(np.shape(Y)[1])), batch_size)
X_in_batch = X[:,sample_index]
Y_in_batch = Y[:,sample_index]
if i > 200:
self.lr /= 10
self.train_in_batch(X_in_batch,Y_in_batch,i)
def train_in_batch(self,X,Y,i):
s,a = self.forword_propagation(X)
if 1:
with open('parameters.txt','a') as f_parameters:
f_parameters.write('\n\nAt iteration:'+str(i)+'\n')
for l in range(1,self.num_of_layers):
f_parameters.write('\nLayer '+str(l)+'\n')
f_parameters.write('\nW:'+str(np.shape(self.W[l]))+'\n')
f_parameters.write(str(self.W[l])+'\n')
f_parameters.write('\nb:'+str(np.shape(self.b[l]))+'\n')
f_parameters.write(str(self.b[l])+'\n')
with open('activations.txt','a') as f_activations:
f_activations.write('\n\nAt iteration:'+str(i)+'\n')
for l in range(0,self.num_of_layers):
f_activations.write('\nLayer '+str(l)+'\n')
f_activations.write('\ns:'+str(np.shape(s[l]))+'\n')
f_activations.write(str(s[l])+'\n')
f_activations.write('\na:'+str(np.shape(a[l]))+'\n')
f_activations.write(str(a[l])+'\n')
with open('ds.txt','a') as f_ds:
f_ds.write('\n\nAt iteration:'+str(i)+'\n')
self.a_last = a[-1]
cost = np.zeros((1,1))
for j in range(np.shape(Y)[1]):
residual = Y[:,j].reshape(10,1)-self.a_last[:,j].reshape(10,1)
cost += np.dot(residual.T,residual)
with open('costs.txt','a') as f_costs:
f_costs.write(str(cost/(np.shape(Y)[1]))+'\n')
self.back_propagation(s,a,Y)training_X = training_images.T training_Y = training_labels.T testing_X = testing_images.T testing_Y = testing_labels.T nn = NerualNetwork(np.array([784,196,49,10])) nn.train(training_X,training_Y,epochs=1000)
import matplotlib.pyplot as plt
%matplotlib inline
with open('costs.txt') as f:
y = []
for eachline in f:
y.append(float(eachline[3:][:-3]))
x = range(len(y))
plt.figure()
plt.plot(x,y)
plt.title('MNIST: 3-layer Nerual Networks using Sigmod Function')
plt.xlabel('steps')
plt.ylabel('cost')testing_Y[:,list(range(5))]
array([[0, 0, 0, 1, 0], [0, 0, 1, 0, 0], [0, 1, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 1], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [1, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0]])
nn.predict(testing_X[:,list(range(5))])
array([[ 0.08852091, 0.07712739, 0.24558161, 0.24253024, 0.09615363], [ 0.06009189, 0.01842345, 0.02953039, 0.10981609, 0.12261026], [ 0.42194989, 0.26216405, 0.0929229 , 0.26748772, 0.22785839], [ 0.06863829, 0.07286736, 0.17960174, 0.18293914, 0.0487555 ], [ 0.02216657, 0.12481555, 0.21624219, 0.04304522, 0.04131497], [ 0.03851181, 0.03991082, 0.0137592 , 0.01167841, 0.0100367 ], [ 0.08333821, 0.33273348, 0.100765 , 0.11475403, 0.23539435], [ 0.00238281, 94d3 0.00640189, 0.00788065, 0.02162292, 0.00926097], [ 0.03512258, 0.00634047, 0.00719783, 0.00774136, 0.00957267], [ 0.17760028, 0.27654505, 0.02500085, 0.11724239, 0.08195934]])
training_Y[:,list(range(5))]
array([[0, 1, 0, 0, 0], [0, 0, 0, 1, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 1, 0, 0], [1, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 1]])
nn.predict(training_X[:,list(range(5))])
array([[ 0.14088619, 0.43447728, 0.00969862, 0.11855052, 0.3753252 ], [ 0.07504254, 0.18396886, 0.01375044, 0.02276849, 0.17391514], [ 0.18822948, 0.24832705, 0.48081013, 0.13560714, 0.13318023], [ 0.10294189, 0.28654818, 0.14425579, 0.14219287, 0.040433 ], [ 0.06517029, 0.08686016, 0.14041424, 0.38237368, 0.14986737], [ 0.0906671 , 0.04954782, 0.01434389, 0.00715321, 0.01533208], [ 0.15485006, 0.04465222, 0.01622938, 0.18944488, 0.24251637], [ 0.10819804, 0.01239158, 0.03952334, 0.01231031, 0.00277187], [ 0.05063162, 0.01122012, 0.04046127, 0.01782585, 0.02276523], [ 0.34232939, 0.01950765, 0.18545528, 0.05277625, 0.03637404]])

相关文章推荐
- Neural networks and the backpropagation algorithm
- UFLDL Tutorial深度学习基础——学习总结:稀疏自编码器(二)反向传播算法(Backpropagation Algorithm)
- Backpropagation Algorithm记录
- BP反向传播算法是如何工作的How the backpropagation algorithm works
- Deep learning---------------Back propagation Algorithm(BP algorithm)
- chapter2 How the backpropagation algorithm works
- 一步一步分析讲解神经网络基础-backpropagation algorithm
- How the backpropagation algorithm works
- [神经网络]2.2/2.3-How the backpropagation algorithm works-The two assumptions we need...(翻译)
- CHAPTER 2 How the backpropagation algorithm works
- 一文弄懂神经网络中的反向传播法(Backpropagation algorithm)
- Backpropagation Algorithm 的梯度
- [神经网络]2.1-How the backpropagation algorithm works-Warm up: a fast matrix-based approach ...(翻译)
- 神经网络二:浅谈反向传播算法(backpropagation algorithm)为什么会很快
- 神经网络和深度学习(二)——BP(Backpropagation Algorithm, 反向传播算法)
- 9-2 backpropagation algorithm 反向传播算法
- 人工神经网络 backpropagation algorithm
- 9 - 2 - Backpropagation Algorithm (12 min)
- CheeseZH: Stanford University: Machine Learning Ex4:Training Neural Network(Backpropagation Algorithm)
- UFLDL 笔记 02 Backpropagation Algorithm 反向传播及初始值设置