【2017最佳机器学习论文】AlphaGo Zero最赏心悦目(一文读懂大咖论文)
2018-01-03 15:04
513 查看
原文链接:点击打开链接
摘要: 2017年,你读过的最有趣、最有价值的机器学习/人工智能论文是什么,为什么?CMU计算机学院暨机器人研究所博士邓侃,2017年在新智元开设专栏,拆解了多篇论文。他从最赏心悦目、最有实践价值和最有潜力这几个方向,给出了他的答案。
前几天与杨静老师和刘江老师,讨论
2017 年人工智能进展时,没来得及说 2017 年最值得读的论文。
“什么是最值得读的论文”,这个话题,仁者见仁智者见智。
下面,说说我个人觉得今年收获最大的论文:
最赏心悦目:Mastering
the Game of Go without Human Knowledge
最有实践价值:Attention
Is All You Need 和 One
Model To Learn Them All
最有研究潜力:Superhuman
AI for heads-up no-limit poker: Libratus beats top professionals
最赏心悦目的论文

Mastering the Game of Go without Human Knowledge 是 DeepMind
团队关于 AlphaGo Zero 的论文,发表于 Nature 期刊。
读这篇论文时,要与 DeepMind 先前讲解 AlphaGo 的另一篇论文,对照着读。那一篇论文的题目是,Mastering the Game of Go with Deep
Neural Networks and Tree Search。
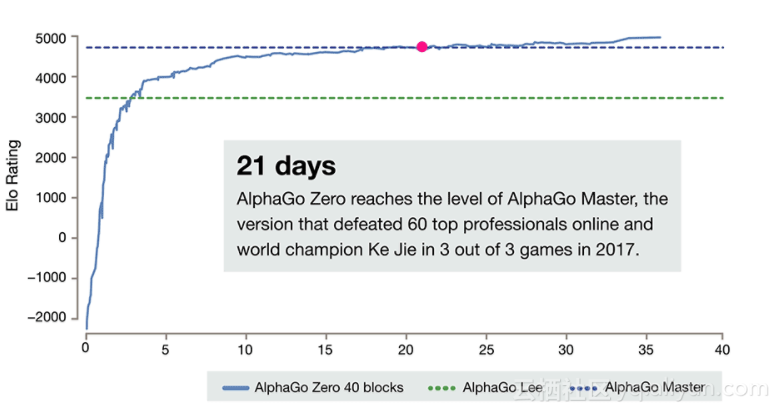
比较这两篇论文,AlphaGo Zero 比先前的版本 AlphaGo 的算法,更精炼,但是功能更强大。而且 AlphaGo Zero 的论文,写得也更精彩。尤其是叙述 AlphaGo Zero 靠自我博弈,花了多少小时,发现了围棋定式。又花了多少天,AlphaGo Zero 棋力先后战胜樊麾和李世乭等等。
最有实践价值论文(两篇)
Attention Is All You Need 和 One Model To Learn Them All 这两篇论文,都是 Google Brain
团队的作品,而且都开源了源码,使用非常方便。
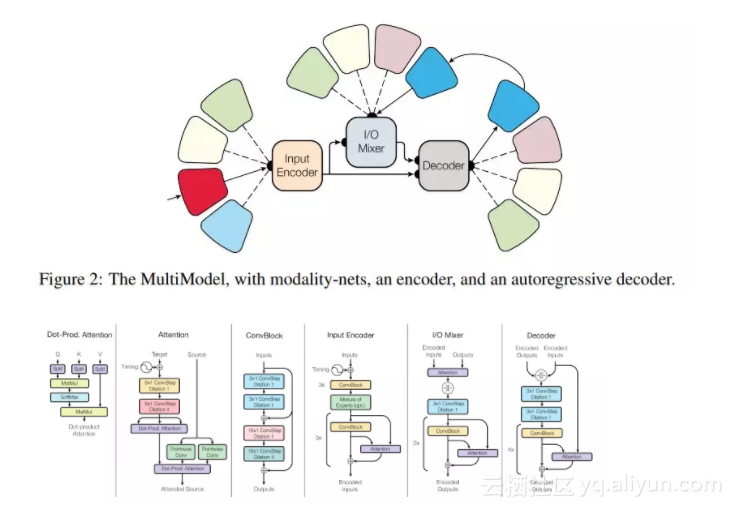
One Model to Learn Them All 论文图片
如果说深度学习,尤其是 CNN 的价值,在于用卷积算法,从原始数据中自动提炼特征,而不必像以往那样,靠人工来提炼特征。那么 Attention 的价值,在于对卷积进行反思。卷积不是提炼特征的唯一方法,而且也不一定是最佳方法。Google Brain 团队认为,Attention 在大多数场景下,可能比卷积更有效。
迄今为止,Attention 的算法大多数基于测算线性相似度。相信明年开始,会有更多的研究,着力于改造 Attention 的算法,尝试非线性相似度,甚至超越相似度,寻找更多的聚焦方式。
最有潜力研究方向

Superhuman AI for heads-up no-limit poker: Libratus beats top professionals 是 CMU 团队讲述人工智能德扑系统 Libratus 的论文,发表于 Science
期刊。
德扑面临着隐信息和反欺诈两个难题,比围棋更接近于真实世界的博弈。
AlphaGo 用深度强化学习,完美地解决了围棋的问题。接下去的悬念,是深度强化学习能否解决隐信息和反欺诈两个难题。有趣的是,Libratus 没有用深度强化学习,却相当漂亮地解决了这两个难题。明年的悬念是,DeepMind 的同事们,能否用深度强化学习来超越 Libratus?
摘要: 2017年,你读过的最有趣、最有价值的机器学习/人工智能论文是什么,为什么?CMU计算机学院暨机器人研究所博士邓侃,2017年在新智元开设专栏,拆解了多篇论文。他从最赏心悦目、最有实践价值和最有潜力这几个方向,给出了他的答案。
前几天与杨静老师和刘江老师,讨论
2017 年人工智能进展时,没来得及说 2017 年最值得读的论文。
“什么是最值得读的论文”,这个话题,仁者见仁智者见智。
下面,说说我个人觉得今年收获最大的论文:
最赏心悦目:Mastering
the Game of Go without Human Knowledge
最有实践价值:Attention
Is All You Need 和 One
Model To Learn Them All
最有研究潜力:Superhuman
AI for heads-up no-limit poker: Libratus beats top professionals
最赏心悦目的论文
Mastering the Game of Go without Human Knowledge 是 DeepMind
团队关于 AlphaGo Zero 的论文,发表于 Nature 期刊。
读这篇论文时,要与 DeepMind 先前讲解 AlphaGo 的另一篇论文,对照着读。那一篇论文的题目是,Mastering the Game of Go with Deep
Neural Networks and Tree Search。
比较这两篇论文,AlphaGo Zero 比先前的版本 AlphaGo 的算法,更精炼,但是功能更强大。而且 AlphaGo Zero 的论文,写得也更精彩。尤其是叙述 AlphaGo Zero 靠自我博弈,花了多少小时,发现了围棋定式。又花了多少天,AlphaGo Zero 棋力先后战胜樊麾和李世乭等等。
最有实践价值论文(两篇)
Attention Is All You Need 和 One Model To Learn Them All 这两篇论文,都是 Google Brain
团队的作品,而且都开源了源码,使用非常方便。
One Model to Learn Them All 论文图片
如果说深度学习,尤其是 CNN 的价值,在于用卷积算法,从原始数据中自动提炼特征,而不必像以往那样,靠人工来提炼特征。那么 Attention 的价值,在于对卷积进行反思。卷积不是提炼特征的唯一方法,而且也不一定是最佳方法。Google Brain 团队认为,Attention 在大多数场景下,可能比卷积更有效。
迄今为止,Attention 的算法大多数基于测算线性相似度。相信明年开始,会有更多的研究,着力于改造 Attention 的算法,尝试非线性相似度,甚至超越相似度,寻找更多的聚焦方式。
最有潜力研究方向
Superhuman AI for heads-up no-limit poker: Libratus beats top professionals 是 CMU 团队讲述人工智能德扑系统 Libratus 的论文,发表于 Science
期刊。
德扑面临着隐信息和反欺诈两个难题,比围棋更接近于真实世界的博弈。
AlphaGo 用深度强化学习,完美地解决了围棋的问题。接下去的悬念,是深度强化学习能否解决隐信息和反欺诈两个难题。有趣的是,Libratus 没有用深度强化学习,却相当漂亮地解决了这两个难题。明年的悬念是,DeepMind 的同事们,能否用深度强化学习来超越 Libratus?

相关文章推荐
- 一文读懂机器学习必备系统:Linux(附常用命令&高级命令)
- 机器学习和深度学习引用量最高的20篇论文(2014-2017)
- 机器学习科普文章:“一文读懂机器学习,大数据/自然语言处理/算法全有了”
- 【NIPS最佳论文引发深度学习论战】AlphaZero能击败冷扑大师吗?No(Science论文)
- 一文读懂机器学习,大数据、自然语言处理、算法全有了……
- 一文读懂深度学习与机器学习的差异
- 一文读完GitHub30+篇顶级机器学习论文(附摘要和论文下载地址)
- 【NIPS最佳论文引发深度学习论战】AlphaZero能击败冷扑大师吗?No(Science论文)
- 一文读懂机器学习,大数据/自然语言处理/算法全有了……
- 一文读懂机器学习,大数据/自然语言处理/算法全有了……
- 一文读懂机器学习,大数据/自然语言处理/算法
- 一文读懂AlphaGo背后的强化学习
- 一文读懂机器学习、数据科学、深度学习和统计学之间的区别
- 一文读懂机器学习
- 一文读懂机器学习,大数据/自然语言处理/算法全有了
- 一文读懂机器学习,大数据/自然语言处理/算法全有了
- 一文读懂机器学习
- 一文读懂机器学习,大数据/自然语言处理/算法全有了……
- 一文读懂机器学习
- 一文读懂机器学习,大数据/自然语言处理/算法全有了……