spark 的各种参数配置
2018-01-03 11:19
393 查看
https://www.jianshu.com/p/9b243c0a7410
我们知道,当在
1.1
1.2
2、创建客户端
3、设置资源、环境变量:其中包括了设置
4、设置
5、申请
当作业提交到
2、设置好相关的环境变量。
3、创建
4、在
5、在
6、等待
7、当
8、分配并启动
d90d
达到了
9、最后,
1、通过
2、而应用程序的
3、在
4、初始化完
5、
6、在
7、分配
8、最后,
9、在作业运行的时候,
10、最后有个线程会再次确认
你可以通过
【2】Spark on YARN客户端模式作业运行全过程分析
【3】Spark on YARN集群模式作业运行全过程分析
作者:wisfern
链接:https://www.jianshu.com/p/9b243c0a7410
來源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
1 spark on yarn常用属性介绍
| 属性名 | 默认值 | 属性说明 |
|---|---|---|
spark.yarn.am.memory | 512m | 在客户端模式(client mode)下, yarn应用 master使用的内存数。在集群模式( cluster mode)下,使用 spark.driver.memory代替。 |
spark.driver.cores | 1 | 在集群模式(cluster mode)下, driver程序使用的核数。在集群模式( cluster mode)下, driver程序和 master运行在同一个 jvm中,所以 master控制这个核数。在客户端模式( client mode)下,使用 spark.yarn.am.cores控制 master使用的核。 |
spark.yarn.am.cores | 1 | 在客户端模式(client mode)下, yarn应用的 master使用的核数。在集群模式下,使用 spark.driver.cores代替。 |
spark.yarn.am.waitTime | 100ms | 在集群模式(cluster
mode)下,yarn应用 master等待 SparkContext初始化的时间。在客户端模式( client mode)下, master等待 driver连接到它的时间。 |
spark.yarn.submit.file.replication | 3 | 文件上传到hdfs上去的 replication次数 |
spark.yarn.preserve.staging.files | false | 设置为true时,在 job结束时,保留 staged文件;否则删掉这些文件。 |
spark.yarn.scheduler.heartbeat.interval-ms | 3000 | Spark应用 master与 yarn resourcemanager之间的心跳间隔 |
spark.yarn.scheduler.initial-allocation.interval | 200ms | 当存在挂起的容器分配请求时,spark应用 master发送心跳给 resourcemanager的间隔时间。它的大小不能大于 spark.yarn.scheduler.heartbeat.interval-ms,如果挂起的请求还存在,那么这个时间加倍,直到到达 spark.yarn.scheduler.heartbeat.interval-ms大小。 |
spark.yarn.max.executor.failures | numExecutors * 2,并且不小于3 | 在失败应用程序之前,executor失败的最大次数。 |
spark.executor.instances | 2 | Executors的个数。这个配置和 spark.dynamicAllocation.enabled不兼容。当同时配置这两个配置时,动态分配关闭, spark.executor.instances被使用 |
spark.yarn.executor.memoryOverhead | executorMemory * 0.10,并且不小于 384m | 每个executor分配的堆外内存。 |
spark.yarn.driver.memoryOverhead | driverMemory * 0.10,并且不小于 384m | 在集群模式下,每个driver分配的堆外内存。 |
spark.yarn.am.memoryOverhead | AM memory * 0.10,并且不小于 384m | 在客户端模式下,每个driver分配的堆外内存 |
spark.yarn.am.port | 随机 | Yarn应用 master监听的端口。 |
spark.yarn.queue | default | 应用提交的yarn队列的名称 |
spark.yarn.jar | none | Jar文件存放的地方。默认情况下, spark jar安装在本地,但是 jar也可以放在 hdfs上,其他机器也可以共享。 |
2 客户端模式和集群模式的区别
这里我们要区分一下什么是客户端模式(client mode),什么是集群模式(
cluster mode)。
我们知道,当在
YARN上运行
Spark作业时,每个
Spark executor作为一个
YARN容器(
container)运行。
Spark可以使得多个
Tasks在同一个容器(
container)里面运行。
yarn-cluster和
yarn-client模式的区别其实就是
Application Master进程的区别,在
yarn-cluster模式下,
driver运行在
AM(
Application Master)中,它负责向
YARN申请资源,并监督作业的运行状况。当用户提交了作业之后,就可以关掉
Client,作业会继续在
YARN上运行。然而
yarn-cluster模式不适合运行交互类型的作业。 在
yarn-client模式下,
Application Master仅仅向
YARN请求
executor,
client会和请求的
container通信来调度他们工作,也就是说
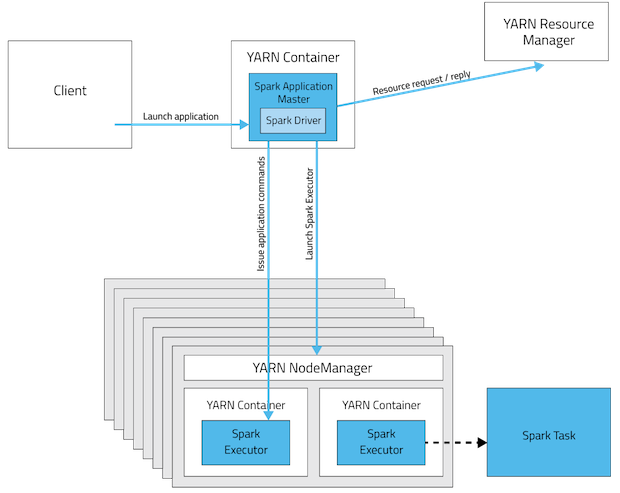
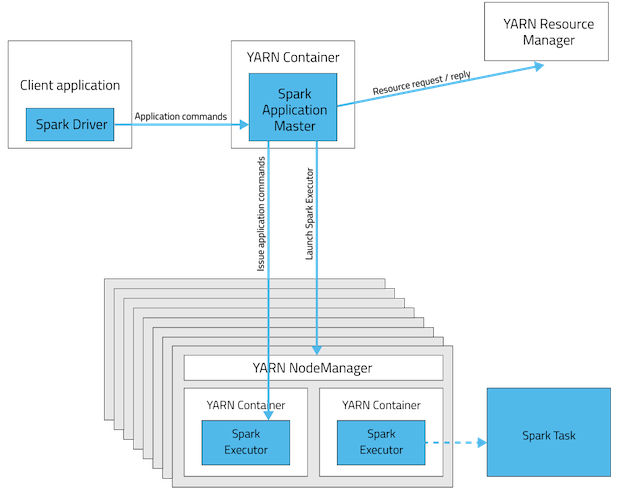
Client不能离开。下面的图形象表示了两者的区别。
1.1
1.2
2.1 Spark on YARN集群模式分析
2.1.1 客户端操作
1、根据yarnConf来初始化
yarnClient,并启动
yarnClient;
2、创建客户端
Application,并获取
Application的
ID,进一步判断集群中的资源是否满足
executor和
ApplicationMaster申请的资源,如果不满足则抛出
IllegalArgumentException;
3、设置资源、环境变量:其中包括了设置
Application的
Staging目录、准备本地资源(
jar文件、
log4j.properties)、设置
Application其中的环境变量、创建
Container启动的
Context等;
4、设置
Application提交的
Context,包括设置应用的名字、队列、
AM的申请的
Container、标记该作业的类型为
Spark;
5、申请
Memory,并最终通过
yarnClient.submitApplication向
ResourceManager提交该
Application。
当作业提交到
YARN上之后,客户端就没事了,甚至在终端关掉那个进程也没事,因为整个作业运行在
YARN集群上进行,运行的结果将会保存到
HDFS或者日志中。
2.1.2 提交到YARN集群,YARN操作
1、运行ApplicationMaster的
run方法;
2、设置好相关的环境变量。
3、创建
amClient,并启动;
4、在
Spark UI启动之前设置
Spark UI的
AmIpFilter;
5、在
startUserClass函数专门启动了一个线程(名称为
Driver的线程)来启动用户提交的
Application,也就是启动了
Driver。在
Driver中将会初始化
SparkContext;
6、等待
SparkContext初始化完成,最多等待
spark.yarn.applicationMaster.waitTries次数(默认为10),如果等待了的次数超过了配置的,程序将会退出;否则用
SparkContext初始化
yarnAllocator;
7、当
SparkContext、Driver初始化完成的时候,通过
amClient向
ResourceManager注册
ApplicationMaster;
8、分配并启动
Executeors。在启动
Executeors之前,先要通过
yarnAllocator获取到
numExecutors个
Container,然后在
Container中启动
Executeors。 如果在启动
Executeors的过程中失败的次数
d90d
达到了
maxNumExecutorFailures的次数,
maxNumExecutorFailures的计算规则如下:
// Default to numExecutors * 2, with minimum of 3
private val maxNumExecutorFailures = sparkConf.getInt("spark.yarn.max.executor.failures",
sparkConf.getInt("spark.yarn.max.worker.failures", math.max(args.numExecutors * 2, 3)))那么这个Application将失败,将
Application Status标明为
FAILED,并将关闭
SparkContext。其实,启动
Executeors是通过
ExecutorRunnable实现的,而
ExecutorRunnable内部是启动
CoarseGrainedExecutorBackend的。
9、最后,
Task将在
CoarseGrainedExecutorBackend里面运行,然后运行状况会通过
Akka通知
CoarseGrainedScheduler,直到作业运行完成。
2.2 Spark on YARN客户端模式分析
和yarn-cluster模式一样,整个程序也是通过
spark-submit脚本提交的。但是
yarn-client作业程序的运行不需要通过
Client类来封装启动,而是直接通过反射机制调用作业的
main函数。下面是流程。
1、通过
SparkSubmit类的
launch的函数直接调用作业的
main函数(通过反射机制实现),如果是集群模式就会调用
Client的
main函数。
2、而应用程序的
main函数一定都有个
SparkContent,并对其进行初始化;
3、在
SparkContent初始化中将会依次做如下的事情:设置相关的配置、注册
MapOutputTracker、BlockManagerMaster、BlockManager,创建
taskScheduler和
dagScheduler;
4、初始化完
taskScheduler后,将创建
dagScheduler,然后通过
taskScheduler.start()启动
taskScheduler,而在
taskScheduler启动的过程中也会调用
SchedulerBackend的
start方法。 在
SchedulerBackend启动的过程中将会初始化一些参数,封装在
ClientArguments中,并将封装好的
ClientArguments传进
Client类中,并
client.runApp()方法获取
Application ID。
5、
client.runApp里面的做的和上章客户端进行操作那节类似,不同的是在里面启动是
ExecutorLauncher(
yarn-cluster模式启动的是
ApplicationMaster)。
6、在
ExecutorLauncher里面会初始化并启动
amClient,然后向
ApplicationMaster注册该
Application。注册完之后将会等待
driver的启动,当
driver启动完之后,会创建一个
MonitorActor对象用于和
CoarseGrainedSchedulerBackend进行通信(只有事件
AddWebUIFilter他们之间才通信,
Task的运行状况不是通过它和
CoarseGrainedSchedulerBackend通信的)。 然后就是设置
addAmIpFilter,当作业完成的时候,
ExecutorLauncher将通过
amClient设置
Application的状态为
FinalApplicationStatus.SUCCEEDED。
7、分配
Executors,这里面的分配逻辑和
yarn-cluster里面类似。
8、最后,
Task将在
CoarseGrainedExecutorBackend里面运行,然后运行状况会通过
Akka通知
CoarseGrainedScheduler,直到作业运行完成。
9、在作业运行的时候,
YarnClientSchedulerBackend会每隔1秒通过
client获取到作业的运行状况,并打印出相应的运行信息,当
Application的状态是
FINISHED、FAILED和
KILLED中的一种,那么程序将退出等待。
10、最后有个线程会再次确认
Application的状态,当
Application的状态是
FINISHED、FAILED和
KILLED中的一种,程序就运行完成,并停止
SparkContext。整个过程就结束了。
3 spark submit 和 spark shell参数介绍
| 参数名 | 格式 | 参数说明 |
|---|---|---|
| --master | MASTER_URL | 如spark://host:port |
| --deploy-mode | DEPLOY_MODE | Client或者master,默认是client |
| --class | CLASS_NAME | 应用程序的主类 |
| --name | NAME | 应用程序的名称 |
| --jars | JARS | 逗号分隔的本地jar包,包含在driver和executor的classpath下 |
| --packages | 包含在driver和executor的classpath下的jar包逗号分隔的”groupId:artifactId:version”列表 | |
| --exclude-packages | 用逗号分隔的”groupId:artifactId”列表 | |
| --repositories | 逗号分隔的远程仓库 | |
| --py-files | PY_FILES | 逗号分隔的”.zip”,”.egg”或者“.py”文件,这些文件放在python app的PYTHONPATH下面 |
| --files | FILES | 逗号分隔的文件,这些文件放在每个executor的工作目录下面 |
| --conf | PROP=VALUE | 固定的spark配置属性 |
| --properties-file | FILE | 加载额外属性的文件 |
| --driver-memory | MEM | Driver内存,默认1G |
| --driver-java-options | 传给driver的额外的Java选项 | |
| --driver-library-path | 传给driver的额外的库路径 | |
| --driver-class-path | 传给driver的额外的类路径 | |
| --executor-memory | MEM | 每个executor的内存,默认是1G |
| --proxy-user | NAME | 模拟提交应用程序的用户 |
| --driver-cores | NUM | Driver的核数,默认是1。这个参数仅仅在standalone集群deploy模式下使用 |
| --supervise | Driver失败时,重启driver。在mesos或者standalone下使用 | |
| --verbose | 打印debug信息 | |
| --total-executor-cores | NUM | 所有executor总共的核数。仅仅在mesos或者standalone下使用 |
| --executor-core | NUM | 每个executor的核数。在yarn或者standalone下使用 |
| --driver-cores | NUM | Driver的核数,默认是1。在yarn集群模式下使用 |
| --queue | QUEUE_NAME | 队列名称。在yarn下使用 |
| --num-executors | NUM | 启动的executor数量。默认为2。在yarn下使用 |
spark-submit --help或者
spark-shell --help来查看这些参数。
参考文献
【1】Spark:Yarn-cluster和Yarn-client区别与联系【2】Spark on YARN客户端模式作业运行全过程分析
【3】Spark on YARN集群模式作业运行全过程分析
作者:wisfern
链接:https://www.jianshu.com/p/9b243c0a7410
來源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

相关文章推荐
- 各种Java技术框架数据库连接池的配置参数
- Spark配置参数
- Spark 性能相关参数配置详解-shuffle篇
- sparksql参数配置
- Hadoop、Spark、Hbase常用配置参数总结
- Spark 性能相关参数配置详解-shuffle篇
- Spark性能相关参数配置 之 Shuffle 相关
- 大数据Spark “蘑菇云”行动第99课:Hive性能调优之企业级Mapper和Reducer调优深度细节解密 参数配置
- Spark 性能相关参数配置详解-任务调度篇
- Spark 性能相关参数配置详解-Storage篇
- Spark性能相关参数配置
- Spark配置参数详解
- Spark 性能相关参数配置详解-压缩与序列化篇
- Spark 性能相关参数配置详解
- Spark性能相关参数配置
- Spark 性能相关参数配置详解-任务调度篇
- Spark配置参数
- Spark性能相关参数配置
- Spark 性能相关参数配置详解
- Java虚拟机-JVM各种参数配置大全详细