机器学习算法原理总结系列---算法基础之(9)多元回归分析(Multiple Regression)
2017-12-30 17:19
786 查看
一、原理详解
与简单线性回归区别(simple linear regression)多个自变量(x)
多元回归模型
y=β0+β1x1+β2x2+ … +βpxp+ε
其中:β0,β1,β2… βp是参数
ε是误差值
多元回归方程
E(y)=β0+β1x1+β2x2+ … +βpxp
估计多元回归方程:
y_hat=b0+b1x1+b2x2+ … +bpxp
一个样本被用来计算β0,β1,β2… βp的点估计b0, b1, b2,…, bp
估计流程 (与简单线性回归类似)
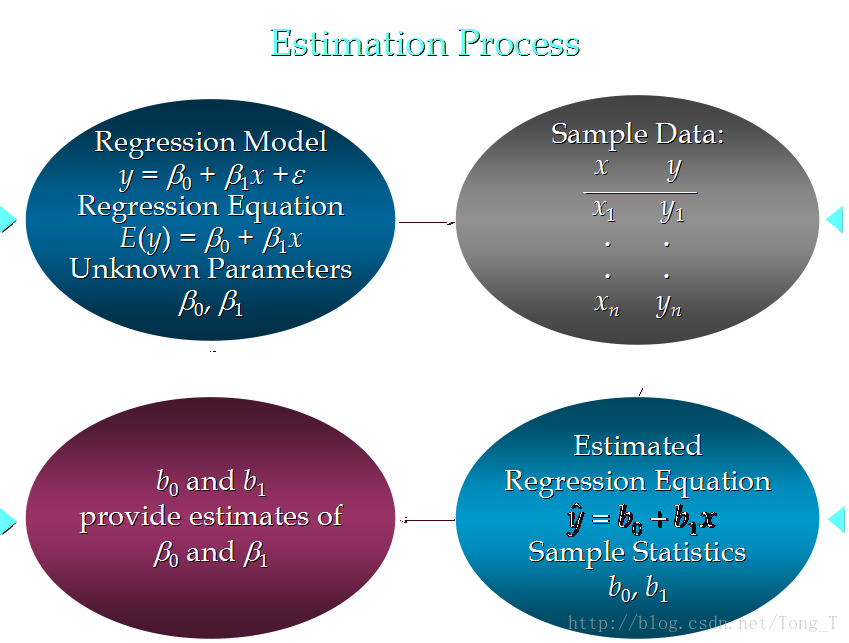
估计方法
使sum of squares最小

运算与简单线性回归类似,涉及到线性代数和矩阵代数的运算
例子
一家快递公司送货:X1: 运输里程 X2: 运输次数 Y:总运输时间
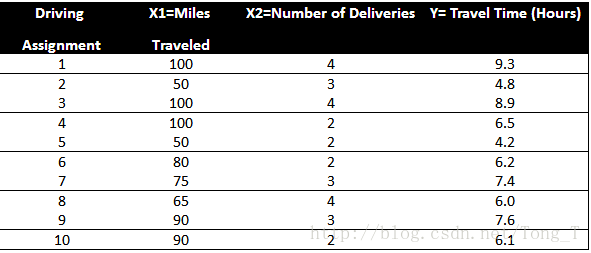
Time = b0+ b1*Miles + b2 * Deliveries
Time = -0.869 + 0.0611 Miles + 0.923 Deliveries
描述参数含义
b0: 平均每多运送一英里,运输时间延长0.0611 小时
b1: 平均每多一次运输,运输时间延长 0.923 小时
预测
如果一个运输任务是跑102英里,运输6次,预计多少小时?
Time = -0.869 +0.0611 102+ 0.923 6
= 10.9 (小时)
如果自变量中有分类型变量(categorical data) , 如何处理?
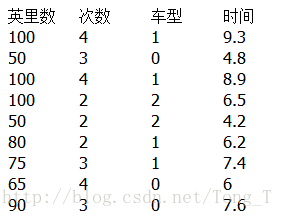
使用ont-hot的编码方式,将分类型变量转化为0,1的形式。
关于误差的分布
误差ε是一个随机变量,均值为0
ε的方差对于所有的自变量来说相等
所有ε的值是独立的
ε满足正态分布,并且通过β0+β1x1+β2x2+ … +βpxp反映y的期望值
二、代码实现
任务依然是上面的例子实现,保存一个csv文件显示为: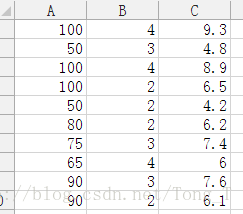
from numpy import genfromtxt
from sklearn import linear_model
import numpy as np
dataPath = r"delivery_analyze.csv"
deliveryData = genfromtxt(dataPath, delimiter=',')
print("data")
print(deliveryData)
X = deliveryData[:, :-1]
Y = deliveryData[:, -1]
print("X:")
print(X)
print("Y: ")
print(Y)
regr = linear_model.LinearRegression()
regr.fit(X, Y)
print("coefficients")
print(regr.coef_)
print("intercept: ")
print(regr.intercept_)
xPred = [102, 6]
yPred = regr.predict(np.array(xPred).reshape(1, -1))
print("predicted y: ")
print(yPred)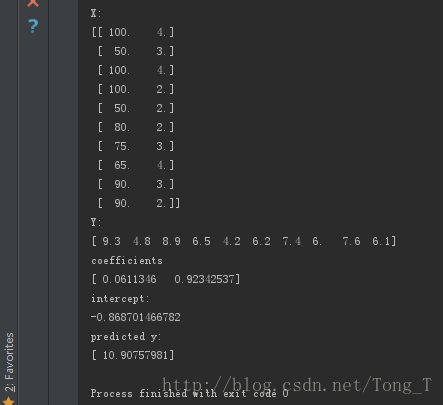

相关文章推荐
- 机器学习算法原理总结系列---算法基础之(8)简单线性回归(Simple Linear Regression)
- 机器学习算法原理总结系列---算法基础之(7)神经网络(Neural Network)
- 机器学习算法原理总结系列---算法基础之(12)层次聚类(hierarchical clustering)
- 机器学习算法原理总结系列---算法基础之(4)最邻近规则分类(K-Nearest Neighbor)
- 机器学习算法原理总结系列---算法基础之(5)朴素贝叶斯(Naive Bayesian)
- 机器学习算法原理总结系列---算法基础之(6)支持向量机(Support Vectors Machine)
- 机器学习算法原理总结系列---算法基础之(3)随机森林(Random Forest)
- 佛爷芸: 机器学习算法原理总结系列---算法基础之(1)机器学习介绍
- 机器学习算法原理总结系列---算法基础之(11)聚类K均值(Clustering K-means)
- 机器学习算法原理总结系列---算法基础之(2)决策树(Decision Tree)
- 机器学习算法原理总结系列---算法基础之(2)决策树(Decision Tree)
- 机器学习算法原理总结系列---算法基础之(10)非线性回归(Logistic Regression)
- 机器学习算法原理总结系列---算法基础之(13)模糊C均值聚类(Fuzzy C-means Clustering)
- 基础算法系列总结:回溯算法(解火力网问题)
- 基础算法系列总结:贪心算法
- 算法基础:基本排序算法原理、实现与总结
- java基础解析系列(四)---LinkedHashMap的原理及LRU算法的实现
- <基础原理进阶>机器学习算法python实现【1】--分类简谈&KNN算法
- 基础算法系列总结:动态规划(解公司外包成本问题)
- java基础解析系列(四)---LinkedHashMap的原理及LRU算法的实现