自然语言期末复习笔记—最大熵模型
2017-12-26 19:57
441 查看
在这篇博客中,我们针对最大熵模型MaxEnt,最大熵马尔科夫模型MEMM,条件随机场CRF做一下介绍。
首先我们来看看MaxEnt,MaxEnt模型中最本质得思想就是我们对未知的事情不要做任何假设。也就是对未知的事情应该等概率对待,这种条件下信息熵往往是最大的。
最大熵原理指出,当我们需要对一个随机事件的概率分布进行预测时,我们的预测应当满足全部已知的条件,而对未知的情况不要做任何主观假设。在这种情况下,概率分布最均匀,预测的风险最小。因为这时概率分布的信息熵最大,所以人们称这种模型叫“最大熵模型”。我们常说,不要把所有的鸡蛋放在一个篮子里,其实就是最大熵原理的一个朴素的说法,因为当我们遇到不确定性时,就要保留各种可能性。说白了,就是要保留全部的不确定性,将风险降到最小。—-摘自《Google黑板报》作者:吴军
看到这你可能觉得那这个模型也太弱了吧,其实光假设所有未知时间是等概率,那确实很弱,但是我们会加进来很多约束条件和特征函数,接下来我们来来一一介绍。
首先我们来看看特征函数,所谓特征函数就是添加一些规则,使我们的模型功能更加强大,前面说了光凭等概率的模型,太弱了,如果真的是用那种方法的话,那我们不必要这么大费周折了,直接随缘法多好。说白了,最大熵的增强功能都是体现在特征函数上。


可以看到这些都需要算法工程师对所处理的数据有好的认识,人工添加的规则。
现在我们已经定义了特征函数,这个时候我们要有清晰的思路,我们构造特征函数是为了增强最大熵模型,那我们让特征函数成为最大熵模型的一部分,进而去影响他,增强他呢? 办法就是用增加约束条件办法。我们最大熵模型在用等概率方法的时候,要在一定约束条件下进行,到这读者可能会觉得一头雾水,又是等概率,又是约束条件。后面我们会这点进行解释,我们在这里说等概率,其实是来自于文章最开始引用吴军老师的话,其实更准确来说,我们是求最大熵,这个会在后面解释。
现在我们用特征函数来构造约束条件。

这里我需要解释以下,我们看到等式右边是真实的期望,但是出现了估计值p(x),这个是一种近似。我们这么做其实为了引出p(y/x)这样的表达。因为我们y是我们的输出,x是我们输入,我们要求得p(y/x)这样得表达式。
以上是关于特征函数,以及约束条件,现在我们来看一下一直说的事件等概率我们是怎么表示的。
就像前面说的一样,我们对未知事件不做任何先验假设,而是用等概率的方法,可以最大化的保留信息,这样的做法其实就是等价于求信息熵的最大化。
现在我们要求p(y/x),他对我们来说是未知的,我们要求他的最大信息熵
这个是条件熵的定义
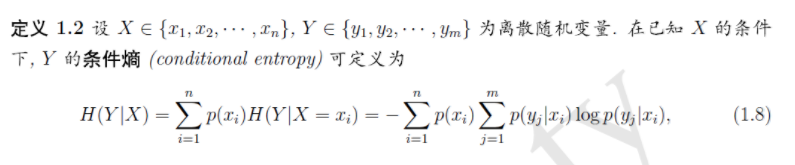
以下是我们对p(y/x)的条件熵的表达
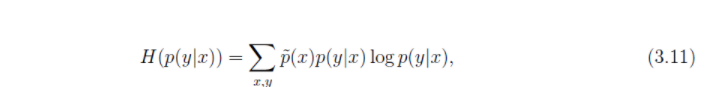
接下来,我们在约束条件下对他求最大值就OK了
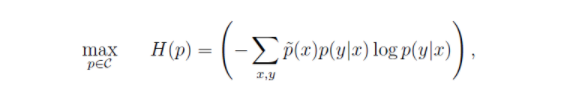

首先我们来看看MaxEnt,MaxEnt模型中最本质得思想就是我们对未知的事情不要做任何假设。也就是对未知的事情应该等概率对待,这种条件下信息熵往往是最大的。
最大熵原理指出,当我们需要对一个随机事件的概率分布进行预测时,我们的预测应当满足全部已知的条件,而对未知的情况不要做任何主观假设。在这种情况下,概率分布最均匀,预测的风险最小。因为这时概率分布的信息熵最大,所以人们称这种模型叫“最大熵模型”。我们常说,不要把所有的鸡蛋放在一个篮子里,其实就是最大熵原理的一个朴素的说法,因为当我们遇到不确定性时,就要保留各种可能性。说白了,就是要保留全部的不确定性,将风险降到最小。—-摘自《Google黑板报》作者:吴军
看到这你可能觉得那这个模型也太弱了吧,其实光假设所有未知时间是等概率,那确实很弱,但是我们会加进来很多约束条件和特征函数,接下来我们来来一一介绍。
首先我们来看看特征函数,所谓特征函数就是添加一些规则,使我们的模型功能更加强大,前面说了光凭等概率的模型,太弱了,如果真的是用那种方法的话,那我们不必要这么大费周折了,直接随缘法多好。说白了,最大熵的增强功能都是体现在特征函数上。
可以看到这些都需要算法工程师对所处理的数据有好的认识,人工添加的规则。
现在我们已经定义了特征函数,这个时候我们要有清晰的思路,我们构造特征函数是为了增强最大熵模型,那我们让特征函数成为最大熵模型的一部分,进而去影响他,增强他呢? 办法就是用增加约束条件办法。我们最大熵模型在用等概率方法的时候,要在一定约束条件下进行,到这读者可能会觉得一头雾水,又是等概率,又是约束条件。后面我们会这点进行解释,我们在这里说等概率,其实是来自于文章最开始引用吴军老师的话,其实更准确来说,我们是求最大熵,这个会在后面解释。
现在我们用特征函数来构造约束条件。
这里我需要解释以下,我们看到等式右边是真实的期望,但是出现了估计值p(x),这个是一种近似。我们这么做其实为了引出p(y/x)这样的表达。因为我们y是我们的输出,x是我们输入,我们要求得p(y/x)这样得表达式。
以上是关于特征函数,以及约束条件,现在我们来看一下一直说的事件等概率我们是怎么表示的。
就像前面说的一样,我们对未知事件不做任何先验假设,而是用等概率的方法,可以最大化的保留信息,这样的做法其实就是等价于求信息熵的最大化。
现在我们要求p(y/x),他对我们来说是未知的,我们要求他的最大信息熵
这个是条件熵的定义
以下是我们对p(y/x)的条件熵的表达
接下来,我们在约束条件下对他求最大值就OK了

相关文章推荐
- 自然语言期末复习笔记—最大熵马尔科夫模型MEMM
- 自然语言期末复习笔记—神经网络语言模型NPLM
- 自然语言期末复习笔记-Formal Grammars Of English
- 自然语言期末复习笔记—Morphological Analysis
- 深度学习和自然语言处理的应用和脉络2-复杂模型,最大熵-隐马尔科夫模型-条件随机场
- 最大熵学习笔记(三)最大熵模型
- coursera NLP学习笔记之week2 语言模型
- 《统计学习方法》笔记(八)--最大熵模型
- 【高级语言程序设计期末复习No.2】数组与字符串
- 笔记:自然语言的计算机处理
- 文本语言模型的参数估计-最大似然估计、MAP及贝叶斯估计
- 【笔记】JS事件模型再复习之笔记
- 文本语言模型的参数估计-最大似然估计、MAP及贝叶斯估计
- 统计语言模型学习笔记
- 最大熵学习笔记(四)模型求解
- 深度学习-自然语言模型
- 深度学习-自然语言模型
- 【网络原理】期末复习笔记 第一章 概述
- 最大熵学习笔记(三)最大熵模型
- 机器学习入门之《统计学习方法》笔记整理——最大熵模型