Lucene使用(三)常用的查询规则
2017-12-25 13:33
609 查看
在上一篇Lucene使用(二)索引的增删改查中,使用的查询规则是Lucene中的多域搜索。此外,在Lucene中查询还可以使用Query的如下子类:
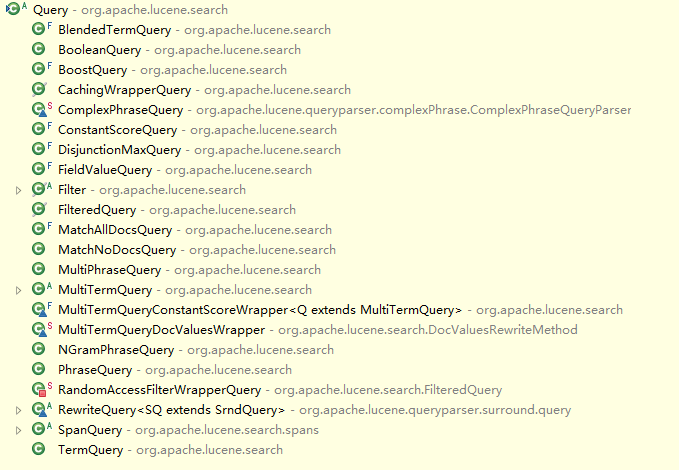
这其中,每个子类相当于一种查询规则,这里仅列举一些常用的。
新建测试类TestLucene03,并且使用上一篇中的方法添加索引数据:


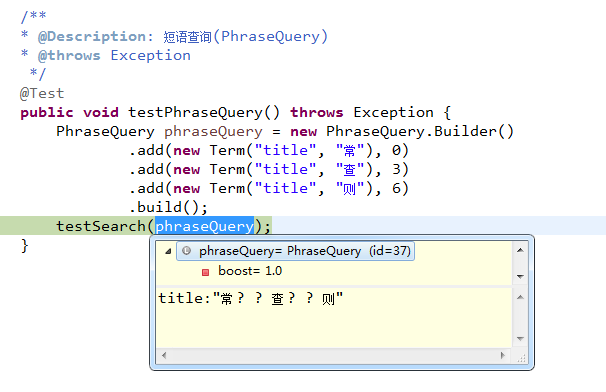
此处可见包含“常”、“查”、“则”三个词的短语 “常 ? ? 查 ? ? 则”,而三个词在该短语中的下标分别是0、3、6,继续执行,控制台打印结果如下:

这其中,每个子类相当于一种查询规则,这里仅列举一些常用的。
新建测试类TestLucene03,并且使用上一篇中的方法添加索引数据:
package net.xxpsw.demo.lucene.test;
import java.util.ArrayList;
import java.util.List;
import org.junit.Test;
import net.xxpsw.demo.lucene.bean.Article;
import net.xxpsw.demo.lucene.dao.LuceneDao;
public class TestLucene03 {
private LuceneDao luceneDao = new LuceneDao();
@Test
public void testAdd() throws Exception {
List<Article> articles = new ArrayList<Article>();
articles.add(new Article(1, "Lucene使用(一)简单索引的创建和检索", "xxpsw", "简单索引的创建和检索", "http://blog.csdn.net/xxpsw/article/details/78751630"));
articles.add(new Article(2, "Lucene使用(二)索引的增删改查", "xxpsw", "索引的增删改查", "http://blog.csdn.net/xxpsw/article/details/78794363"));
articles.add(new Article(3, "Lucene使用(三)常用的查询规则", "xxpsw", "常用的查询规则", "http://blog.csdn.net/xxpsw/article/details/78891779"));
luceneDao.addIndex(articles);
}
}新建测试方法testSearch用以在控制台打印查询结果:private void testSearch(Query query) throws Exception {
List<Article> articlelist = new ArrayList<Article>();
IndexSearcher indexSearcher = LuceneUtils.getIndexSearcher();
TopDocs topDocs = indexSearcher.search(query, 100);
Article article = null;
ScoreDoc scoreDocs[] = topDocs.scoreDocs;
for (int i = 0; i < scoreDocs.length; i++) {
int docID = scoreDocs[i].doc;
Document document = indexSearcher.doc(docID);
article = ArticleUtils.documentToArticle(document);
articlelist.add(article);
}
Gson gson = new GsonBuilder().setPrettyPrinting().create();
System.out.println(gson.toJson(articlelist));
}1. 查询所有(MatchAllDocsQuery)
使用MatchAllDocsQuery可以构建一个没有任何条件的Query,用于返回所有的文档,新建方法testMatchAllDocsQuery:/**
* @Description: 查询所有(MatchAllDocsQuery)
* @throws Exception
*/
@Test
public void testMatchAllDocsQuery() throws Exception {
4000
MatchAllDocsQuery matchAllDocsQuery = new MatchAllDocsQuery();
testSearch(matchAllDocsQuery);
}执行测试方法,控制台打印如下:2. 精确查询(TermQuery)
使用TermQuery可以根据指定的字段值精确查询文档,新建测试方法testTermQuery:/**
* @Description: 精确查询(TermQuery)
* @throws Exception
*/
@Test
public void testTermQuery() throws Exception {
TermQuery termQuery = new TermQuery(new Term("title", "常"));
testSearch(termQuery);
}由于默认分词器对中文的分词是单个汉字,所以此处使用单个汉字进行查询,测试结果如下:3. 短语查询(PhraseQuery)
使用PhraseQuery可以构建包含若干个词的短语模板,然后根据该短语模板匹配合适的文档,新建测试方法testPhraseQuery:/**
* @Description: 短语查询(PhraseQuery)
* @throws Exception
*/
@Test
public void testPhraseQuery() throws Exception {
PhraseQuery phraseQuery = new PhraseQuery.Builder()
.add(new Term("title", "常"), 0)
.add(new Term("title", "查"), 3)
.add(new Term("title", "则"), 6)
.build();
testSearch(phraseQuery);
}为了方便观察,在testSearch(phraseQuery)处加上断点,debug模式执行测试方法,断点信息如下:此处可见包含“常”、“查”、“则”三个词的短语 “常 ? ? 查 ? ? 则”,而三个词在该短语中的下标分别是0、3、6,继续执行,控制台打印结果如下:
4. 通配符查询(WildcardQuery)
WildcardQuery是MultiTermQuery的一个子类,使用WildcardQuery可以实现通配符查询,具体来说,?代表单个字母,*代表0或多个字母,新建测试方法testWildcardQuery:/**
* @Description: 通配符查询(WildcardQuery)
* @throws Exception
*/
@Test
public void testWildcardQuery() throws Exception {
WildcardQuery wildcardQuery = new WildcardQuery(new Term("author", "x*?"));
testSearch(wildcardQuery);
}执行测试方法,结果如下:5. 模糊查询(FuzzyQuery)
FuzzyQuery是MultiTermQuery的一个子类,使用FuzzyQuery可以简单地识别两个近似的词,实现相似度匹配,新建测试方法testFuzzyQuery:/**
* @Description: 模糊查询(FuzzyQuery)
* @throws Exception
*/
@Test
public void testFuzzyQuery() throws Exception {
FuzzyQuery fuzzyQuery = new FuzzyQuery(new Term("author", "xxp11"), 2);
testSearch(fuzzyQuery);
}此处author的正确值是xxpsw,而与之相匹配的查询值是xxp11,此处允许2个错误字符,因此是可以查询出相关文档的。一般来说,错误字符的数量取值为0、1、2三者中的一个。执行测试方法,控制台打印如下:6. 范围查询(NumericRangeQuery)
NumericRangeQuery是MultiTermQuery的一个子类,使用NumericRangeQuery可以实现数字类型的数据查询,新建测试方法testNumericRangeQuery:/**
* @Description: 范围查询(NumericRangeQuery)
* @throws Exception
*/
@Test
public void testNumericRangeQuery() throws Exception {
// (字段名称,最小值,最大值,是否包含最小值,是否包含最大值)
NumericRangeQuery<?> newIntRange = NumericRangeQuery.newIntRange("id", 2, 3, false, true);
testSearch(newIntRange);
}执行测试方法,结果如下:7. 布尔查询(BooleanQuery)
使用BooleanQuery可以建立多个Query之间的联系,从而实现满足多个条件的复杂查询,新建测试方法testBooleanQuery:/**
* @Description: 布尔查询(BooleanQuery)
* @throws Exception
*/
@Test
public void testBooleanQuery() throws Exception {
TermQuery query01 = new TermQuery(new Term("title", "一"));
TermQuery query02 = new TermQuery(new Term("title", "三"));
BooleanQuery booleanQuery = new BooleanQuery.Builder()
.add(query01, Occur.SHOULD)
.add(query02, Occur.SHOULD)
.build();
testSearch(booleanQuery);
}指示Query使用场景的枚举包含Occur.MUST,Occur.SHOULD,Occur.MUST_NOT。一般来说,MUST和MUST连用表示取多个查询结果的交集,SHOULD和SHOULD连用表示取多个查询结果的并集,MUST和MUST_NOT连用表示查询结果中不包含MUST_NOT子句所对应的查询结果。执行测试方法,打印结果如下:

相关文章推荐
- Lucene使用项向量进行模糊查询
- Ajax常用的几个函数及Alexa查询的几个查询接口及使用方法
- 常用ACE锁的类型分析及使用规则
- Lucene使用正则表达式查询
- 常用PHP中花括号使用规则详解
- 数据库SQL中的分钟表示应该使用MI(非常重要的一个问题,以前一直认为和java中一样,用mm就可以表示);校对规则(查询时区分大小写)
- ORACLE用户常用数据字典的查询使用方法
- 使用org.apache.lucene创建和查询索引核心代码详解
- Git的初次使用 ; Git常用命令查询 ; Git push ; Git pull 2011-12-16 17:32 在介绍安装和简单使用前,先看一下百度百科中的简介吧: ———————————
- 智能查询功能lucene使用情况及遇到的问题
- lucene使用教程3 --常用类的对象
- lucene使用教程4 --常用类的对象之IndexSearcher
- lucene使用教程5 --常用类的对象之IndexReader
- Wireshark抓包工具使用教程以及常用抓包规则
- lucene-使用Highlighter高亮显示查询项
- Git的初次使用 ; Git常用命令查询 ; Git push ; Git pull 2011-12-16 17:32 在介绍安装和简单使用前,先看一下百度百科中的简介吧: ———————————
- ORACLE用户常用数据字典的查询使用方法
- 使用org.apache.lucene创建和查询索引核心代码详解
- ORACLE用户常用数据字典的查询使用方法
- ORACLE用户常用数据字典的查询使用方法(转载收集)