RSelenium包抓取豆瓣电影(模拟滚动条)
2017-12-24 14:26
369 查看
关于辅助插件
SelectorGadget
SelectorGadget插件可以用來显示网页中任意元素的CSS选择器路径,帮助我们快速定位到目标内容。安装方法:
从Chrome商店直接安裝(建议使用此方式),安装完毕后在浏览器右上角显示,使用时点击图标即可
将SelectorGadget官网所提供的链接拖曳存为浏览器书签,使用时点击书签即可
Toggle JavaScript

Toggle JavaScript插件可以帮助我们快速、直观地检测网页中,哪些信息是通过AJAX (异步JavaScript和XML)加载而来的。其主要原理是拦截网页中的JavaScript,隐藏动态内容,只显示静态信息。安装方法:
从Chrome商店直接安裝,安装完毕后在浏览器右上角显示,使用时点击图标即可
JSON-handle

JSON-handle插件可以对JSON格式的内容进行浏览和编辑,以树形图样式展现JSON文档,并可实时编辑。安装方法:
从Chrome商店直接安裝,安装完毕后在浏览器右上角显示,使用时点击图标即可
思路
以豆瓣电影分类排行榜 - 剧情片为例,点击Toggle JavaScript插件,发现点击后电影信息缺失,说明缺失部分是异步加载模块:点击前正常显示
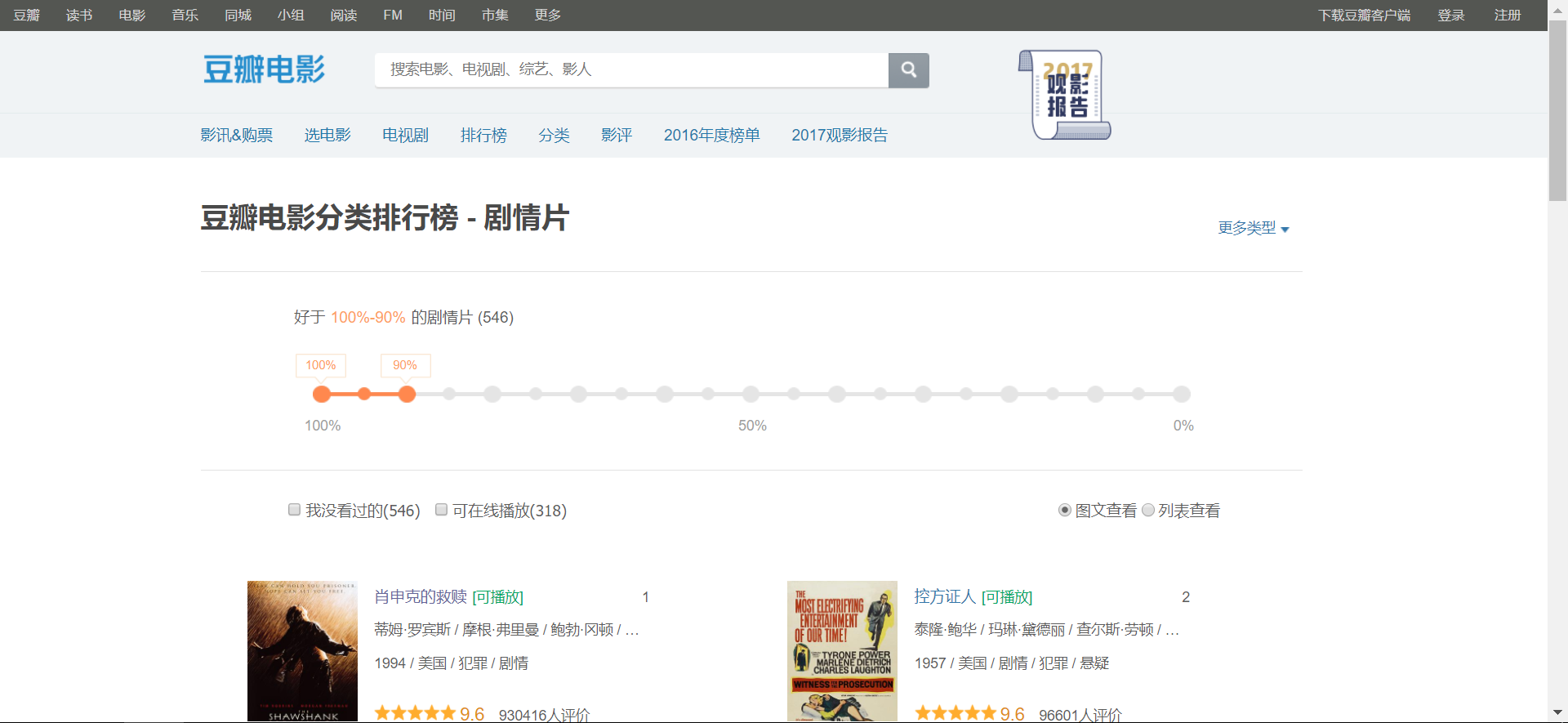
点击后信息缺失
该网站是一个典型的瀑布流网站,随着浏览器滚动下拉,页面信息不断更新。可用如下两种方式尝试抓取:
每一次下拉页面,AJAX异步加载都会请求一个新的地址,如果这些地址的变化是有规律的,就可以通过拼接地址,直接抓取。
利用RSelenium包模拟浏览器滚动条的下拉过程,下拉至页面最底端,直到所以信息都加载完毕,再从这个页面抓取所需内容。
方法一
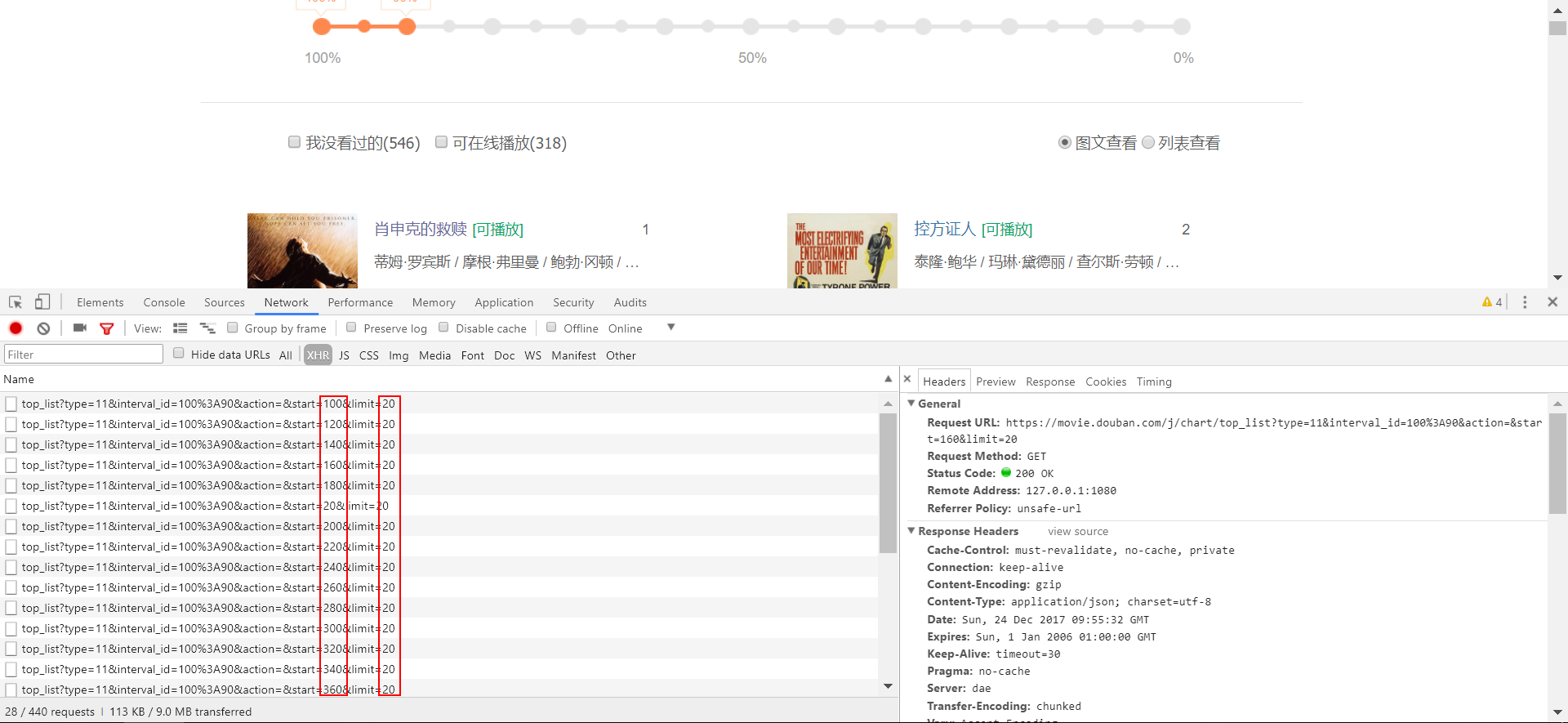
获取AJAX异步加载所请求的JSON文档,从R读取该文档:Fn+F12打开Chrome浏览器的开发者工具,找到
Network一栏,实现一次下拉更新,观察栏中的请求变化。如下图找到新的请求地址:得知其请求方式为
GET,请求内容是一个JSON文档:
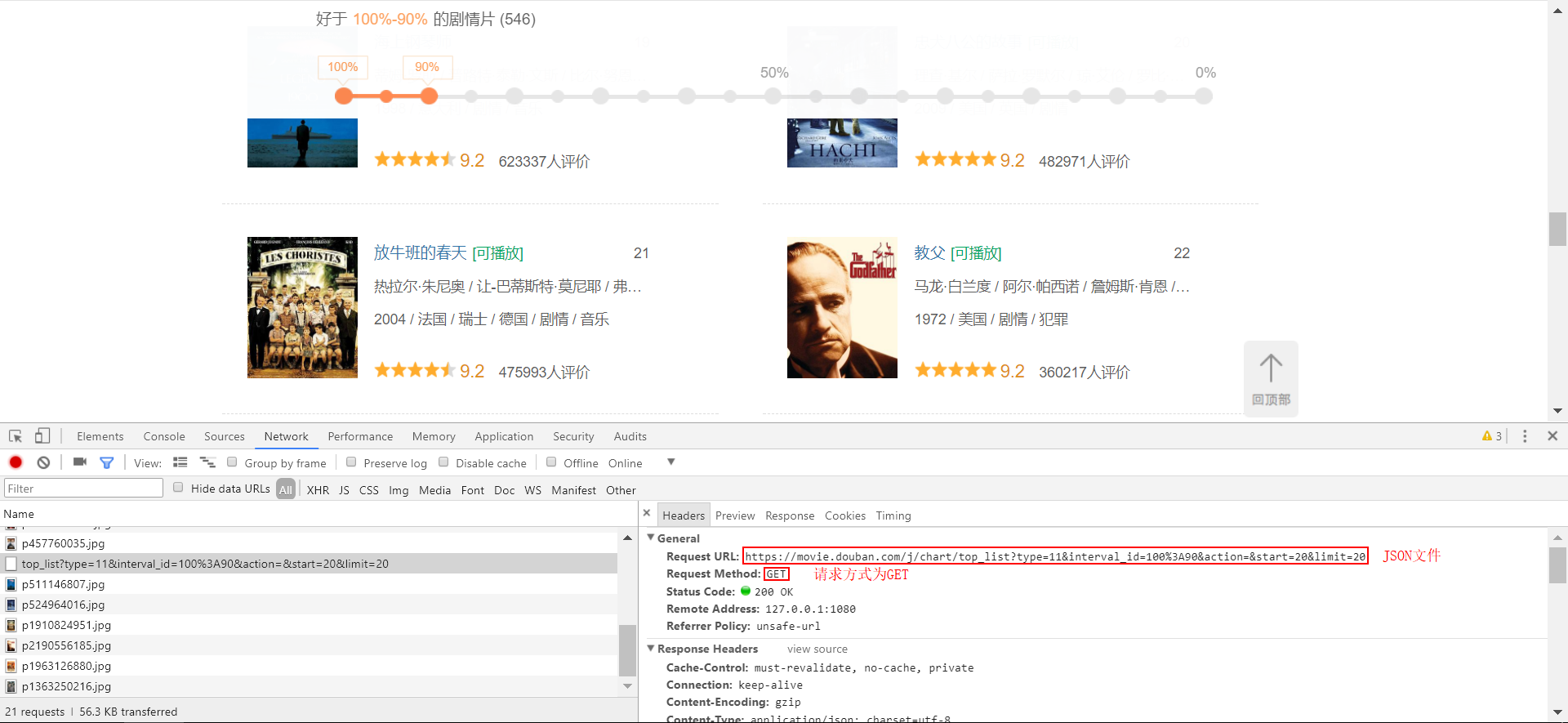
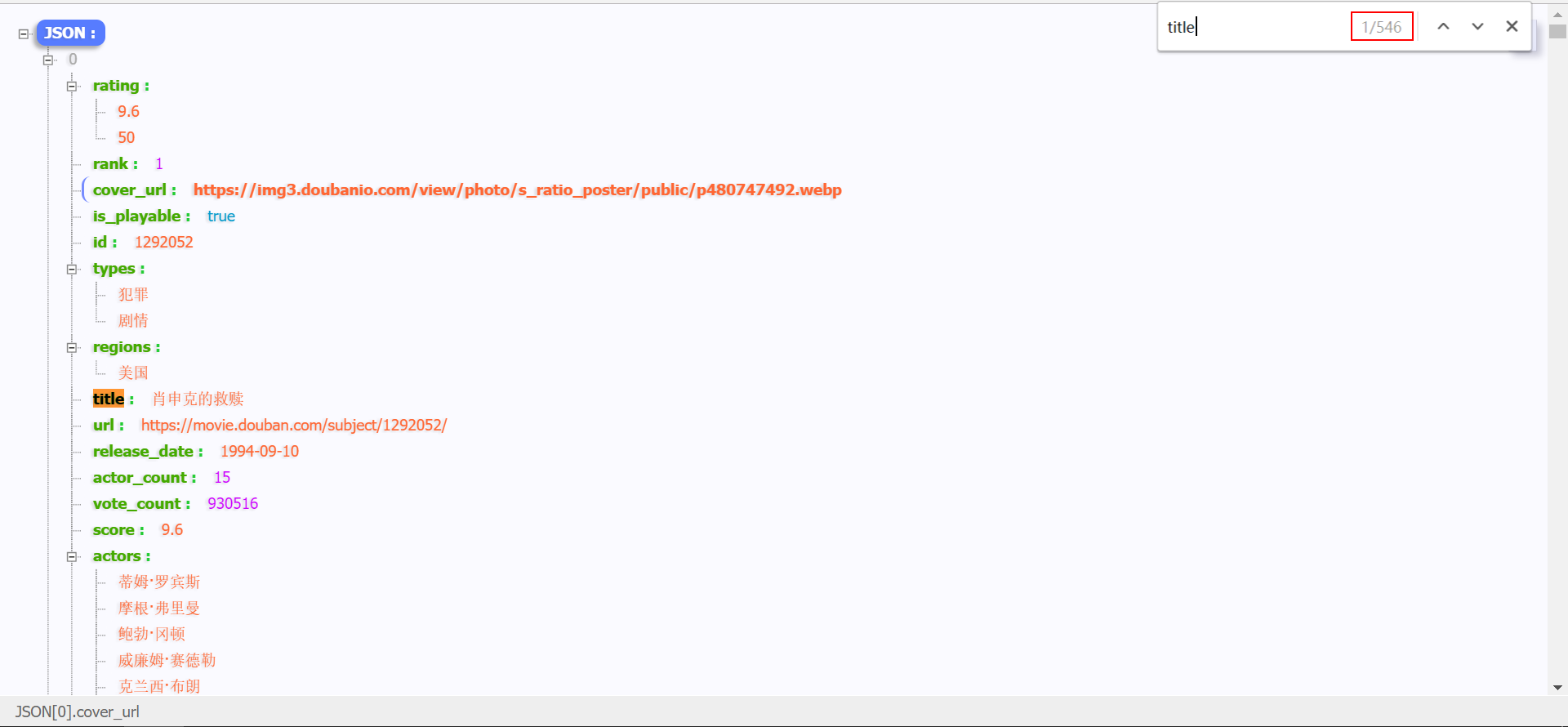
右击该请求地址,选择
Open in new tab,若安装了JSON-handle插件,则网页会以相当规整的JSON文件格式呈现,可以发现文件内容全部是新加载的电影信息:
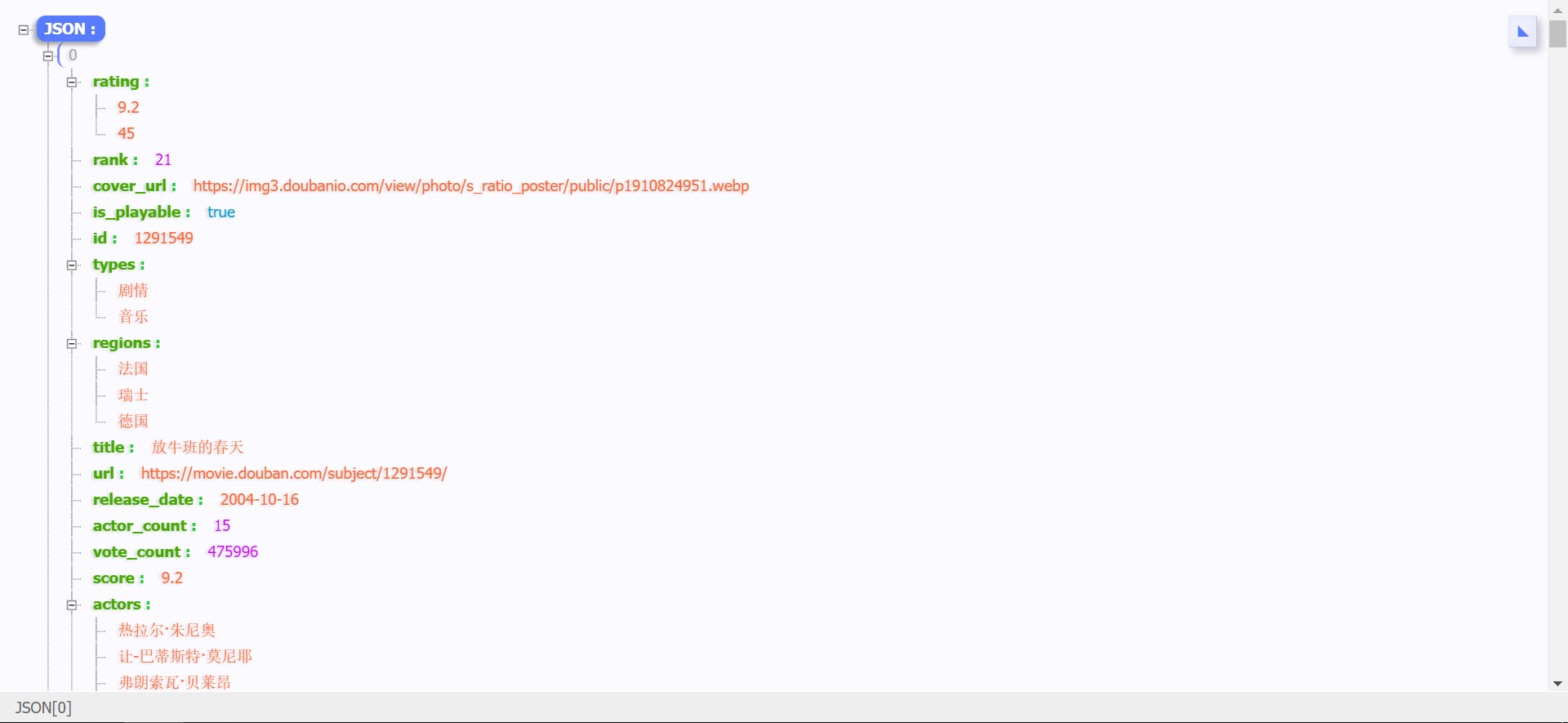
连续下拉直到信息全部加载完毕,然后在XHR菜单里查看所有的请求链接,发现地址的变化是有规律的:参数start每次递增20,参数limit不变,由此猜测每下拉一次,就会从前一个位置开始,往后继续加载20部电影:
因此稍微更改一下请求地址,令起始位置start=0,单次加载数量limit=546(共有546部电影),就能得到包含完整电影信息的JSON文档地址:
https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90&action=&start=0&limit=546
然后在R中读取该JSON文档,做数据清洗。R中能够导入、导出和处理JSON数据的组件有好几个:
其中第一个发布的组件是
rjson(Couture-Beil 2013),它在一些基于R的接口包里仍在使用;
第二个组件是
RJSONIO(Temple Lang 2013b);
最新发布的一个组件是
jsonlite(Ooms and Temple Lang 2014),它是在RJSONIO的基础上构建的,改善了R对象和JSON字符串之间的映射。
这三个组件都提供了
fromJSON(content)函数,其中content可以是:工作目录中的JSON格式的文件、getURL()函数获取的字符串、readLines()函数导入的字符串。这里分别尝试用RJSONIO和jsonlite读取,并查看前几部电影的数据格式:
RJSONIO读取结果
> library(RJSONIO) > library(magrittr) > url <- "https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90&action=&start=0&limit=546" > destination <- readLines(url, encoding = "UTF-8") %>% fromJSON() > head(destination) [[1]] [[1]]$rating [1] "9.6" "50" [[1]]$rank [1] 1 [[1]]$cover_url [1] "https://img3.doubanio.com/view/photo/s_ratio_poster/public/p480747492.jpg" [[1]]$is_playable [1] TRUE [[1]]$id [1] "1292052" [[1]]$types [1] "犯罪" "剧情" [[1]]$regions [1] "美国" [[1]]$title [1] "肖申克的救赎" [[1]]$url [1] "https://movie.douban.com/subject/1292052/" [[1]]$release_date [1] "1994-09-10" [[1]]$actor_count [1] 15 [[1]]$vote_count [1] 931091 [[1]]$score [1] "9.6" [[1]]$actors [1] "蒂姆·罗宾斯" "摩根·弗里曼" "鲍勃·冈顿" "威廉姆·赛德勒" "克兰西·布朗" "吉尔·贝罗斯" [7] "马克·罗斯顿" "詹姆斯·惠特摩" "杰弗里·德曼" "拉里·布兰登伯格" "尼尔·吉恩托利" "布赖恩·利比" [13] "大卫·普罗瓦尔" "约瑟夫·劳格诺" "祖德·塞克利拉" [[1]]$is_watched [1] FALSE [[2]] [[2]]$rating [1] "9.6" "50" [[2]]$rank [1] 2 [[2]]$cover_url [1] "https://img1.doubanio.com/view/photo/s_ratio_poster/public/p1505392928.jpg" [[2]]$is_playable [1] TRUE [[2]]$id [1] "1296141" [[2]]$types [1] "剧情"< 1e378 /span> "犯罪" "悬疑" [[2]]$regions [1] "美国" [[2]]$title [1] "控方证人" [[2]]$url [1] "https://movie.douban.com/subject/1296141/" [[2]]$release_date [1] "1957-12-17" [[2]]$actor_count [1] 9 [[2]]$vote_count [1] 96711 [[2]]$score [1] "9.6" [[2]]$actors [1] "泰隆·鲍华" "玛琳·黛德丽" "查尔斯·劳顿" "爱尔莎·兰切斯特" "约翰·威廉姆斯" "亨利·丹尼尔" [7] "伊安·沃尔夫" "托林·撒切尔" "诺玛·威登" [[2]]$is_watched [1] FALSE
jsonlite读取结果
> library(jsonlite) > library(magrittr) > url <- "https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90&action=&start=0&limit=546" > destination <- readLines(url, encoding = "UTF-8") %>% fromJSON() > head(destination) rating rank cover_url is_playable id 1 9.6, 50 1 https://img3.doubanio.com/view/photo/s_ratio_poster/public/p480747492.jpg TRUE 1292052 2 9.6, 50 2 https://img1.doubanio.com/view/photo/s_ratio_poster/public/p1505392928.jpg TRUE 1296141 3 9.5, 50 3 https://img3.doubanio.com/view/photo/s_ratio_poster/public/p1910813120.jpg TRUE 1291546 4 9.5, 50 4 https://img3.doubanio.com/view/photo/s_ratio_poster/public/p510861873.jpg TRUE 1292063 5 9.4, 50 5 https://img3.doubanio.com/view/photo/s_ratio_poster/public/p511118051.jpg TRUE 1295644 6 9.4, 50 6 https://img1.doubanio.com/view/photo/s_ratio_poster/public/p510876377.jpg TRUE 1292720 types regions title url release_date 1 犯罪, 剧情 美国 肖申克的救赎 https://movie.douban.com/subject/1292052/ 1994-09-10 2 剧情, 犯罪, 悬疑 美国 控方证人 https://movie.douban.com/subject/1296141/ 1957-12-17 3 剧情, 爱情, 同性 中国大陆, 香港 霸王别姬 https://movie.douban.com/subject/1291546/ 1993-01-01 4 剧情, 喜剧, 爱情, 战争 意大利 美丽人生 https://movie.douban.com/subject/1292063/ 1997-12-20 5 剧情, 动作, 犯罪 法国 这个杀手不太冷 https://movie.douban.com/subject/1295644/ 1994-09-14 6 剧情, 爱情 美国 阿甘正传 https://movie.douban.com/subject/1292720/ 1994-06-23 actor_count vote_count score 1 15 931091 9.6 2 9 96711 9.6 3 19 673141 9.5 4 19 438535 9.5 5 16 883135 9.4 6 7 751023 9.4 actors 1 蒂姆·罗宾斯, 摩根·弗里曼, 鲍勃·冈顿, 威廉姆·赛德勒, 克兰西·布朗, 吉尔·贝罗斯, 马克·罗斯顿, 詹姆斯·惠特摩, 杰弗里·德曼, 拉里·布兰登伯格, 尼尔·吉恩托利, 布赖恩·利比, 大卫·普罗瓦尔, 约瑟夫·劳格诺, 祖德·塞克利拉 2 泰隆·鲍华, 玛琳·黛德丽, 查尔斯·劳顿, 爱尔莎·兰切斯特, 约翰·威廉姆斯, 亨利·丹尼尔, 伊安·沃尔夫, 托林·撒切尔, 诺玛·威登 3 张国荣, 张丰毅, 巩俐, 葛优, 英达, 蒋雯丽, 吴大维, 吕齐, 雷汉, 尹治, 马明威, 费振翔, 智一桐, 李春, 赵海龙, 李丹, 童弟, 沈慧芬, 黄斐 4 罗伯托·贝尼尼, 尼可莱塔·布拉斯基, 乔治·坎塔里尼, 朱斯蒂诺·杜拉诺, 赛尔乔·比尼·布斯特里克, 玛丽萨·帕雷德斯, 霍斯特·布赫霍尔茨, 利迪娅·阿方西, 朱利亚娜·洛约迪切, 亚美利哥·丰塔尼, 彼得·德·席尔瓦, 弗朗西斯·古佐, 拉法埃拉·莱博罗尼, 克劳迪奥·阿方西, 吉尔·巴罗尼, 马西莫·比安奇, 恩尼奥·孔萨尔维, 吉安卡尔洛·科森蒂诺, 阿伦·克雷格 5 让·雷诺, 娜塔莉·波特曼, 加里·奥德曼, 丹尼·爱罗, 彼得·阿佩尔, 迈克尔·巴达鲁科, 艾伦·格里尼, 伊丽莎白·瑞根, 卡尔·马图斯维奇, 弗兰克·赛格, 麦温, 乔治·马丁, 罗伯特·拉萨多, 亚当·布斯奇, 马里奥·托迪斯科, 萨米·纳塞利 6 汤姆·汉克斯, 罗宾·怀特, 加里·西尼斯, 麦凯尔泰·威廉逊, 莎莉·菲尔德, Michael Conner Humphreys, 海利·乔·奥斯蒙 is_watched 1 FALSE 2 FALSE 3 FALSE 4 FALSE 5 FALSE 6 FALSE
最后选择jsonlite来读取,完整代码如下:
library(jsonlite) library(magrittr) url <- "https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90&action=&start=0&limit=546" destination <- readLines(url, encoding = "UTF-8") %>% fromJSON() title <- destination$title score <- destination$score release_date <- destination$release_date movie_url <- destination$url cover_url <- destination$cover_url types <- destination$types %>% paste0() regions <- destination$regions %>% paste0() actors <- destination$actors %>% paste0() is_playable <- destination$is_playable is_watched <- destination$is_watched movieinfo <- data.frame(title, score, release_date, movie_url, cover_url, types, regions, actors, is_playable, is_watched) # 由于types、regions、actors三个变量的值不唯一,带有多个向量,故考虑用paste0()将其合并为字符串 View(movieinfo) write.csv(movieinfo, row.names = FALSE, "movieinfo.csv")
查看数据:
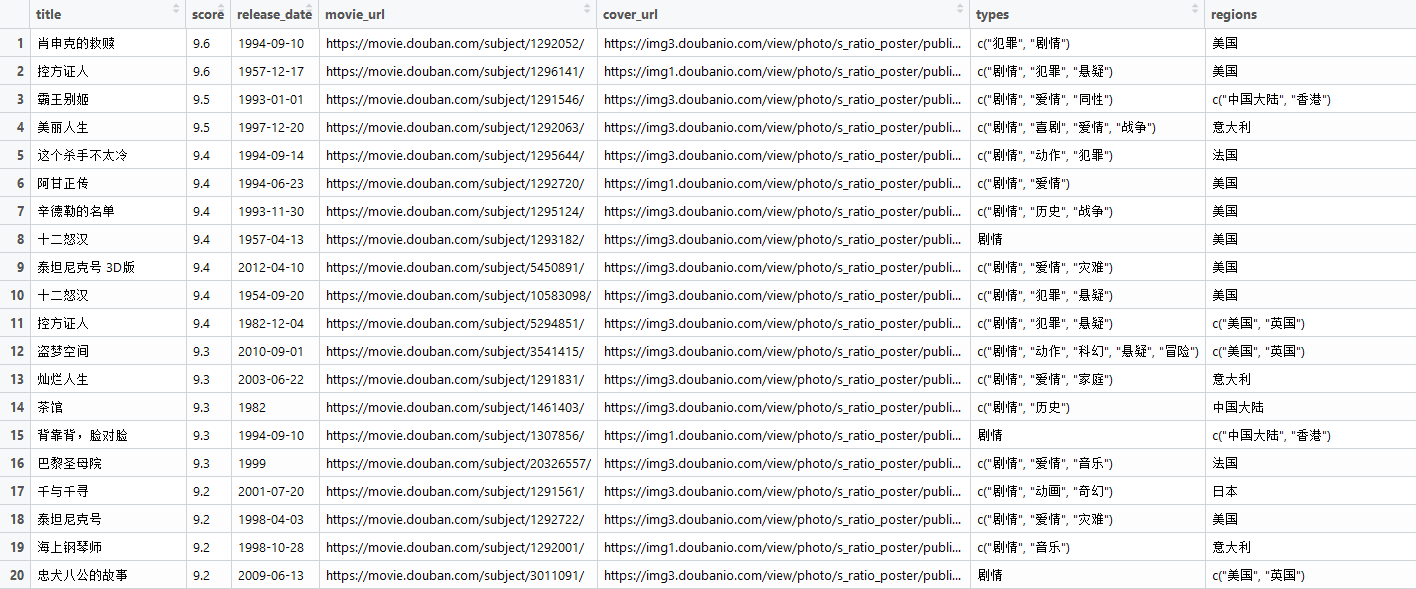
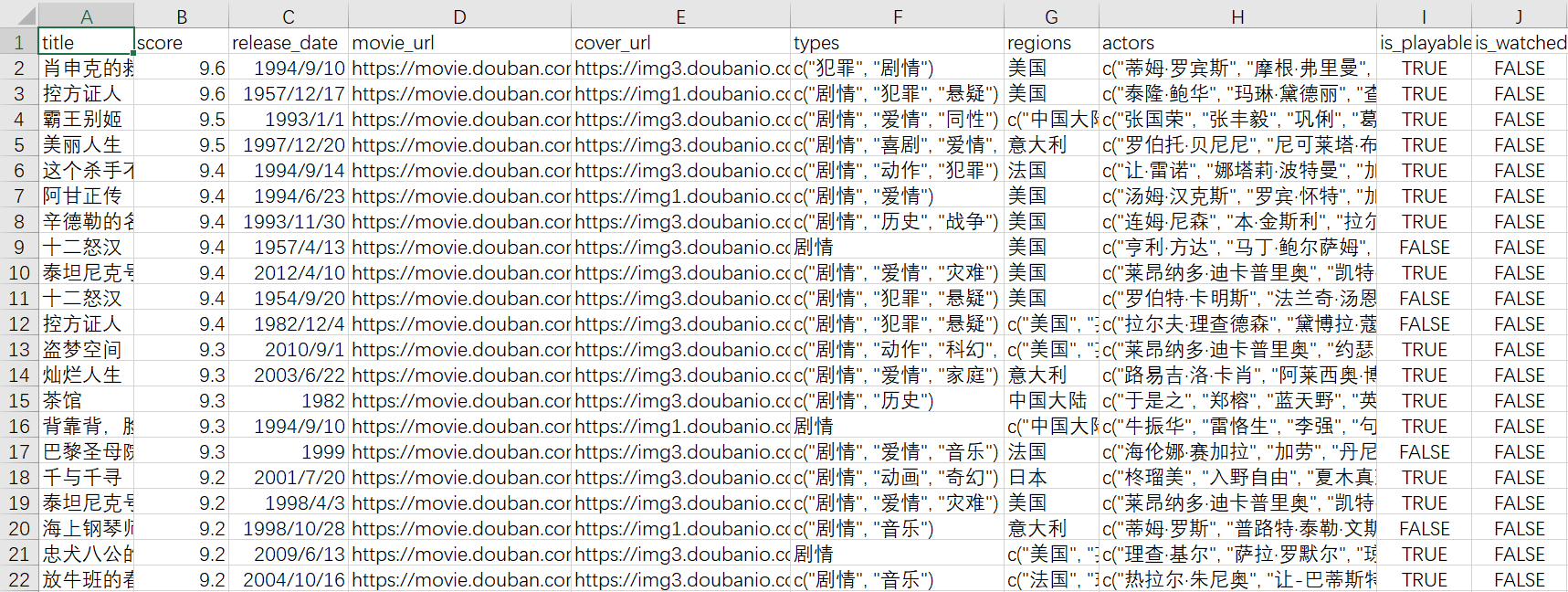
方法二
直接访问豆瓣电影分类排行榜 - 剧情片,通过RSelenium模拟滚动条下拉过程,将整个页面加载出来,再分别提取所需信息:library(RSelenium)
library(rvest)
shell("java -jar D:/R/library/Rwebdriver/selenium-server-standalone-3.7.1.jar",
wait = FALSE, invisible = FALSE)
# 启动selenium服务器,shell()适用于Windows操作系统,其作用是从R中调用系统命令,相当于在cmd中输入指令
# 参数wait声明R是否需要等待系统命令执行完毕(这里不需要等待,因为selenium服务器必须和R同时运行)
# 参数invisible声明是否在屏幕上显示cmd窗口
url <- "https://movie.douban.com/typerank?type_name=%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action="
remDr <- remoteDriver(browserName = "chrome")
remDr$open()
remDr$navigate(url)
# 打开Chrome浏览器并连接到指定页面
last_height = 0
repeat {
remDr$executeScript("window.scrollTo(0,document.body.scrollHeight);",
list(remDr$findElement("css", "body")))
Sys.sleep(2)
new_height = remDr$executeScript("return document.body.scrollHeight",
list(remDr$findElement("css", "body")))
if(unlist(last_height) == unlist(new_height)) {
break
} else {
last_height = new_height
}
}
# 使用函数executeScript执行一个JavaScript片段,模拟滚动条向下拉取页面,单次拉取长度=页面剩余高度
# 循环拉取,每次拉取都记录新的总高度,直到总高度不再变化(即页面加载不出新内容),则停止下拉操作
destination <- remDr$getPageSource()[[1]] %>% read_html()
# 页面信息全部加载完毕,获取页面内容
title <- destination %>% html_nodes(".movie-name-text a") %>%
html_text() %>% .[1:546]
score <- destination %>% html_nodes(".rating_num") %>%
html_text() %>% .[1:546]
year.region.type <- destination %>% html_nodes(".movie-misc") %>%
html_text() %>% .[1:546]
movie_url <- destination %>% html_nodes(".movie-name-text a") %>%
html_attr("href") %>% .[1:546]
movieinfo <- data.frame(title, score, year.region.type, movie_url)
# 提取title、score、year.region.type、movie_url4个字段
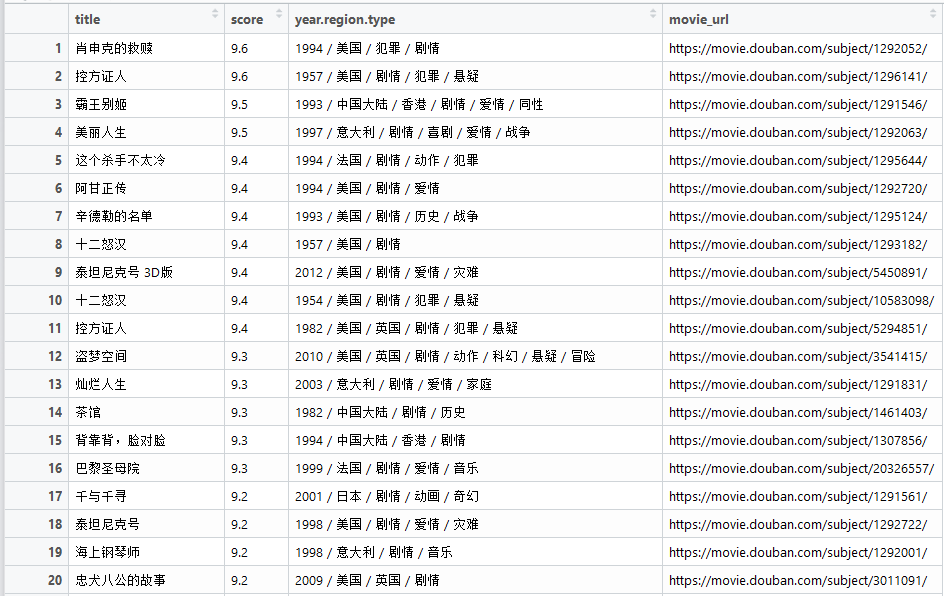
View(movieinfo)
write.csv(movieinfo, row.names = FALSE, "movieinfo.csv")
# View()函数查看数据并导出到本地
remDr$close()
# 关闭浏览器查看数据:
总结
对于异步加载的网页,方法一通过观察每次请求的新地址,直接获得JSON文档,再读入R中,优点是获取的信息相当完整,不必花费太多功夫做数据清洗;缺点是当遇到复杂网站,新的请求地址无规律可循,或者需要抓取多个页面,无法一一观察每个页面的请求规律,方法一自动化程度较低。方法二则是模拟浏览器的滚动条,每拉取一次,加载一部分信息,通过循环拉取,将页面所有信息全部加载出来,再读取完整的页面内容,做字段提取。在本案例中,方法二的优势不太明显,有点小题大做。因为只需抓取一个页面,并且关键字段(数据清洗)需要一个个提取,这里仅作为模拟浏览器滚动条的一次简单尝试。
使用方法二时,当页面信息全部加载完毕,用
getPageSource()获取整个页面内容,开始提取字段以后,发现字段信息有重复(如下,共546部电影,从第547开始double重复),emmmm…不得其解。由于已知共有546部电影,所以用
.[1:546]提取前546个结果。但用方法二在蚂蜂窝用户界面尝试提取酒店信息时,没有出现字段重复,代码和结果附后。
# 豆瓣电影,提取电影名称,有重复信息
> title <- destination %>% html_nodes(".movie-name-text a") %>% html_text()
> title
[1] "肖申克的救赎" "控方证人" "霸王别姬" "美丽人生" "这个杀手不太冷"
[6] "阿甘正传" "辛德勒的名单" "十二怒汉" "泰坦尼克号 3D版" "十二怒汉"
[11] "控方证人" "盗梦空间" "灿烂人生" "茶馆" "背靠背,脸对脸"
[16] "巴黎圣母院" "千与千寻" "泰坦尼克号" "海上钢琴师" "忠犬八公的故事"
[21] "放牛班的春天" "教父" "乱世佳人" "熔炉" "鬼子来了"
[26] "小鞋子" "摩登时代" "七武士" "东京物语" "城市之光"
[31] "生活多美好" "洞" "切腹" "哀乐中年" "丛林赤子心"
[36] "三傻大闹宝莱坞" "星际穿越" "楚门的世界" "摔跤吧!爸爸" "触不可及"
[41] "天堂电影院" "指环王3:王者无敌" "两杆大烟枪" "活着" "窃听风暴"
[46] "辩护人" "饮食男女" "教父2" "素媛" "美国往事"
[51] "请以你的名字呼唤我" "地下" "熊的故事" "寻子遇仙记" "南海十三郎"
[56] "天堂回信" "鳄鱼波鞋走天涯" "剃头匠" "女人步上楼梯时" "情迷意乱"
[61] "少年派的奇幻漂流" "无间道" "搏击俱乐部" "蝙蝠侠:黑暗骑士" "飞越疯人院"
[66] "钢琴家" "狩猎" "完美的世界" "忠犬八公物语" "我爱你"
[71] "无人知晓" "爱·回家" "芙蓉镇" "攻壳机动队2:无罪" "沉静如海"
[76] "红鳉鱼" "从海底出击" "我的父亲,我的儿子" "卡比利亚之夜" "生之欲"
[81] "将军号" "我是" "士兵之歌" "流浪者之歌" "纽伦堡的审判"
[86] "木更津猫眼 世界系列" "海蒂" "怦然心动" "当幸福来敲门" "飞屋环游记"
[91] "罗马假日" "闻香识女人" "美丽心灵" "指环王1:魔戒再现" "被嫌弃的松子的一生"
[96] "狮子王" "死亡诗社" "指环王2:双塔奇兵" "拯救大兵瑞恩" "音乐之声"
[101] "玛丽和马克思" "末代皇帝" "上帝之城" "一一" "穿条纹睡衣的男孩"
[106] "小森林 夏秋篇" "小森林 冬春篇" "勇士" "与狼共舞" "伴我同行"
[111] "海蒂和爷爷" "偷自行车的人" "大独裁者" "听见天堂" "大路"
[116] "楢山节考" "光荣之路" "大都会" "永恒和一日" "乡愁"
[121] "神女" "镜子" "佛兰德斯的狗" "死者田园祭" "神探夏洛克:最后的誓言"
[126] "世上最快的印地安摩托" "安德烈·卢布廖夫" "婚姻生活" "夺命剑" "尤里西斯的凝视"
[131] "哭泣的草原" "可玛猫" "撒旦探戈" "我出生了,但……" "秦时明月之一舞倾城"
[136] "战争与和平" "无言的山丘" "V字仇杀队" "情书" "致命魔术"
[141] "低俗小说" "入殓师" "勇敢的心" "阳光姐妹淘" "春光乍泄"
[146] "第六感" "甜蜜蜜" "超脱" "侧耳倾听" "你看起来好像很好吃"
[151] "房间" "喜宴" "魂断蓝桥" "聚焦" "卢旺达饭店"
[156] "爱在午夜降临前" "我是山姆" "地球上的星星" "极速风流" "步履不停"
[161] "刺猬的优雅" "跳出我天地" "相助" "赛德克·巴莱(上):太阳旗" "坠入"
[166] "东京教父" "自闭历程" "悲情城市" "乱" "黑客帝国动画版"
[171] "城南旧事" "天佑鲍比" "永远的三丁目的夕阳" "女人四十" "追梦赤子心"
[176] "童年往事" "影子武士" "因父之名" "雾中风景" "我能说"
[181] "刺杀肯尼迪" "金色池塘" "独立时代" "用心棒" "爱情短片"
[186] "伴你高飞" "鲁冰花" "我的九月" "十二怒汉" "夜"
[191] "乌龟也会飞" "麦秋" "日出" "歌厅" "陆上行舟"
[196] "生命是个奇迹" "笼民" "蝴蝶的舌头" "相约星期二" "秋天里的春光"
[201] "天堂的孩子" "大地之歌" "泥之河" "旅行" "死期将至"
[206] "伯德小姐" "让子弹飞" "剪刀手爱德华" "七宗罪" "本杰明·巴顿奇事"
[211] "蝴蝶效应" "沉默的羔羊" "消失的爱人" "西西里的美丽传说" "告白"
[216] "重庆森林" "布达佩斯大饭店" "血战钢锯岭" "看不见的客人" "心灵捕手"
[221] "阳光灿烂的日子" "大鱼" "猫鼠游戏" "爱在黎明破晓前" "恐怖直播"
[226] "萤火虫之墓" "爱在日落黄昏时" "菊次郎的夏天" "7号房的礼物" "萤火之森"
[231] "燃情岁月" "纵横四海" "荒蛮故事" "浪潮" "一次别离"
[236] "教父3" "可可西里" "罗生门" "梦之安魂曲" "一个叫欧维的男人决定去死"
[241] "碧海蓝天" "牯岭街少年杀人事件" "绿里奇迹" "末路狂花" "赛德克·巴莱"
[246] "东邪西毒:终极版" "海洋之歌" "千钧一发" "中央车站" "盲井"
[251] "蓝白红三部曲之红" "再见列宁" "横道世之介" "魔术师" "沙漠之花"
[256] "赛德克·巴莱(下):彩虹桥" "四百击" "精英部队2:大敌当前" "奇爱博士" "迷墙"
[261] "斯隆女士" "交响情人梦 最终乐章 后篇" "铁拳男人" "战场上的快乐圣诞" "弗里达"
[266] "莫里斯" "骗中骗" "东京家族" "斯图尔特:倒带人生" "阿拉伯的劳伦斯"
[271] "野草莓" "奇迹" "日落大道" "秋刀鱼之味" "暴雨将至"
[276] "桃色公寓" "无间道(正序版)" "黄昏的清兵卫" "变脸" "总有一天"
[281] "恐怖分子" "伦敦一家人" "回归" "永远的三丁目的夕阳2" "邮差"
[286] "巴里·林登" "理查二世" "爱犬的奇迹" "虎豹小霸王" "晚春"
[291] "男孩与世界" "甜蜜的生活" "假面" "天堂的颜色" "椿三十郎"
[296] "呼喊与细语" "烈日灼人" "潜行者" "豹" "芬妮与亚历山大"
[301] "冬之蝉" "亨利五世" "古畑任三郎 VS SMAP" "罗密欧与朱丽叶" "阿玛柯德"
[306] "秋日奏鸣曲" "神迹" "摇滚芭比" "史密斯先生到华盛顿" "无声婚礼"
[311] "恐惧的代价" "巴比龙" "倒扣的王牌" "铁达尼号沉没记" "悲惨世界"
[316] "街角的商店" "牺牲" "一九零零" "浮草" "小偷"
[321] "莫娣" "圣女贞德蒙难记" "指环王" "楢山节考" "石榴的颜色"
[326] "鲸鱼马戏团" "凡尔杜先生" "生命的舞动" "多桑" "麻雀之歌"
[331] "最卑贱的人" "维莉蒂安娜" "莎乐美" "鹳鸟踟蹰" "舞台春秋"
[336] "天伦之旅" "禁闭岛" "致命ID" "断背山" "岁月神偷"
[341] "哈利·波特与死亡圣器(下)" "倩女幽魂" "东邪西毒" "爆裂鼓手" "幸福终点站"
[346] "杀人回忆" "雨人" "时空恋旅人" "人工智能" "穿越时空的少女"
[351] "撞车" "海边的曼彻斯特" "达拉斯买家俱乐部" "海盗电台" "心迷宫"
[356] "完美陌生人" "荒野生存" "卡萨布兰卡" "海街日记" "非常嫌疑犯"
[361] "叫我第一名" "燕尾蝶" "枪火" "廊桥遗梦" "蝴蝶"
[366] "大卫·戈尔的一生" "不一样的天空" "洛城机密" "小萝莉的猴神大叔" "我在伊朗长大"
[371] "至爱梵高·星空之谜" "我们俩" "莫扎特传" "天伦之旅" "费城故事"
[376] "布达佩斯之恋" "对她说" "比海更深" "南极大冒险" "老爷车"
[381] "我们天上见" "至暗时刻" "隐藏人物" "帝国的毁灭" "共同警备区"
[386] "热天午后" "两小无猜" "内布拉斯加" "面子" "蓝风筝"
[391] "德州巴黎" "想飞的钢琴少年" "青之炎" "东京塔" "西伯利亚的理发师"
[396] "小城之春" "梦" "甘地传" "宾虚" "焦土之城"
[401] "情枭的黎明" "狐狸与我" "十月的天空" "光辉岁月" "寂寞芳心"
[406] "音乐会" "查令十字街84号" "无主之地" "笑之大学" "史崔特先生的故事"
[411] "伊万的童年" "霍金传" "彗星美人" "小公主" "芭萨提的颜色"
[416] "午宴之歌" "王子与公主" "人狼" "敲开天堂的门" "何处是我朋友的家"
[421] "喜马拉雅" "再见,孩子们" "西线无战事" "亨利四世:第一部分" "这里的黎明静悄悄"
[426] "母亲" "记我的母亲" "天堂陌影" "曼联重生" "生活艰难但是快乐"
[431] "望乡" "樱花盛开" "亨利四世:第二部分" "热泪伤痕" "一级谋杀"
[436] "艾美的世界" "浮云" "爵士春秋" "生活艰难所以快乐" "皱纹"
[441] "党同伐异" "碧血金沙" "我这一辈子" "布朗克斯的故事" "魂断蓝桥"
[446] "其后" "蜂巢幽灵" "乌鸦与麻雀" "另一个故乡" "悲伤的贝拉多娜"
[451] "爸爸去出差" "割草叔叔" "自由的幻影" "二十四只眼睛" "生生长流"
[456] "木更津猫眼 日本篇" "母亲的城堡" "征服者佩尔" "铁扇公主" "被遗忘的孩子"
[461] "卡斯帕尔·豪泽尔之谜" "爱丽丝城市漫游记" "你的名字。" "黑天鹅" "贫民窟的百万富翁"
[466] "喜剧之王" "真爱至上" "蝙蝠侠:黑暗骑士崛起" "恋恋笔记本" "记忆碎片"
[471] "朗读者" "敦刻尔克" "被解救的姜戈" "模仿游戏" "猜火车"
[476] "花样年华" "悲惨世界" "新龙门客栈" "阿飞正传" "这个男人来自地球"
[481] "战争之王" "E.T. 外星人" "月球" "少年时代" "荒岛余生"
[486] "血钻" "开心家族" "麦兜故事" "遗愿清单" "银翼杀手2049"
[491] "百万美元宝贝" "千年女优" "哪啊哪啊神去村" "万箭穿心" "时时刻刻"
[496] "新世界" "天水围的日与夜" "登堂入室" "茜茜公主" "少年斯派维的奇异旅行"
[501] "岁月的童话" "单身男子" "土拨鼠之日" "美国X档案" "狼的孩子雨和雪"
[506] "阿郎的故事" "全金属外壳" "春夏秋冬又一春" "K星异客" "走出非洲"
[511] "嘉年华" "相爱相亲" "爱" "机器管家" "公民凯恩"
[516] "启示" "安妮·霍尔" "编舟记" "克莱默夫妇" "和声"
[521] "花火" "恋恋风尘" "金色梦乡" "关于我母亲的一切" "地雷区"
[526] "杀死一只知更鸟" "迫在眉梢" "交响情人梦 最终乐章 前篇" "回家的路" "12怒汉:大审判"
[531] "洛奇" "水牛城66" "柏林苍穹下" "光荣之路" "麻将"
[536] "十分钟年华老去:小号篇" "昨天" "朝圣之路" "西部往事" "死亡医生"
[541] "迷恋荷尔蒙" "虎兄虎弟" "邦尼和琼" "伊豆的舞女" "天狗"
[546] "花落花开" "肖申克的救赎" "肖申克的救赎" "控方证人" "控方证人"
[551] "霸王别姬" "霸王别姬" "美丽人生" "美丽人生" "这个杀手不太冷"
[556] "这个杀手不太冷" "阿甘正传" "阿甘正传" "辛德勒的名单" "辛德勒的名单"
[561] "十二怒汉" "十二怒汉" "泰坦尼克号 3D版" "泰坦尼克号 3D版" "十二怒汉"
[566] "十二怒汉" "控方证人" "控方证人" "盗梦空间" "盗梦空间"
[571] "灿烂人生" "灿烂人生" "茶馆" "茶馆" "背靠背,脸对脸"
[576] "背靠背,脸对脸" "巴黎圣母院" "巴黎圣母院" "千与千寻" "千与千寻"
[581] "泰坦尼克号" "泰坦尼克号" "海上钢琴师" "海上钢琴师" "忠犬八公的故事"
[586] "忠犬八公的故事" "放牛班的春天" "放牛班的春天" "教父" "教父"
[591] "乱世佳人" "乱世佳人" "熔炉" "熔炉" "鬼子来了"
[596] "鬼子来了" "小鞋子" "小鞋子" "摩登时代" "摩登时代"
[601] "七武士" "七武士" "东京物语" "东京物语" "城市之光"
[606] "城市之光" "生活多美好" "生活多美好" "洞" "洞"
# 后面结果省略,共1638条(正好是546*3,每部电影出现3次)# 蚂蜂窝用户界面,提取酒店名称,无重复信息
> library(RSelenium)
> library(rvest)
> shell("java -jar D:/R/library/Rwebdriver/selenium-server-standalone-3.7.1.jar",
+ wait = FALSE, invisible = FALSE)
> url <- "http://www.mafengwo.cn/u/606971/review.html"
> remDr <- remoteDriver(browserName = "chrome")
> remDr$open()
> remDr$navigate(url)
> last_height = 0
> repeat {
+ remDr$executeScript("window.scrollTo(0,document.body.scrollHeight);",
+ list(remDr$findElement("css", "body")))
+ Sys.sleep(2)
+ new_height = remDr$executeScript("return document.body.scrollHeight",
+ list(remDr$findElement("css", "body")))
+ if(unlist(last_height) == unlist(new_height)) {
+ break
+ } else {
+ last_height = new_height
+ }
+ }
> destination <- remDr$getPageSource()[[1]] %>% read_html()
> title <- destination %>% html_nodes("h3.title a") %>% html_text()
> title
[1] "洪家楼天主教堂"
[2] "山东大学"
[3] "南岳忠烈祠"
[4] "衡山国家重点风景名胜区"
[5] "石鼓公园"
[6] "石鼓书院"
[7] "衡阳抗战纪念城"
[8] "南天门"
[9] "南岳衡山"
[10] "祝融峰"
[11] "南岳大庙"
[12] "岳屏公园"
[13] "张家界专家村宾馆Zhuanjiacun Hotel"
[14] "溪布街"
[15] "麦当劳(天子山贺龙公园店)"
[16] "西天取经"
[17] "劈山救母"
[18] "神鹰护鞭"
[19] "千里相会"
[20] "水绕四门"
[21] "三姐妹峰"
[22] "采药老人"
[23] "张家界十里画廊"
[24] "天子山"
[25] "张家界武陵源景区门票站"
[26] "御笔峰"
[27] "贺龙公园"
[28] "袁家界"
[29] "天下第一桥"
[30] "一线天"
[31] "乌龙寨"
[32] "金鸡报晓"
[33] "乾坤柱"
[34] "连心桥"
[35] "仙人桥"
[36] "神兵聚会"
[37] "百龙天梯"
[38] "大庸府城"
[39] "凌霄台"
[40] "通天大道"
[41] "天门山寺"
[42] "老王三下锅"
[43] "7天连锁酒店张家界回龙路步行街店7Days Inn Zhangjiajie Huilong Road Pedestrian Street"
[44] "张家界香紫溪客栈"
[45] "鬼谷天坠"
[46] "鬼谷栈道"
[47] "天门山玻璃栈道"
[48] "天门洞"
[49] "张家界天门山景区"
[50] "天沐江西明月山温泉度假区"
[51] "美食"
[52] "东荟城Citygate Outlets"
[53] "香港中环中银大厦Bank of China Tower, Hong Kong(BOC Tower)"
[54] "许留山(豉油街店)Hui Lau Shan"
[55] "油麻地Yau Ma Tei"
[56] "添好运点心专门店(奥海城店)"
[57] "维多利亚港"
[58] "香港海洋公园Hong Kong Ocean Park"
[59] "香港太平山顶"
[60] "旺角Mong Kok"
[61] "庙街"
[62] "中环Central"
[63] "尖沙咀Tsim Sha Tsui"
[64] "翠华餐厅(加拿芬道店)Tsui Wah Restaurant"
[65] "香港国际机场Hong Kong International Airport"
[66] "太平山山顶缆车"
[67] "铜锣湾地带Causeway Bay"
[68] "星光大道Avenue of Stars"
[69] "天星小轮Star Ferry"
[70] "天星码头"
[71] "四望亭"
[72] "谢馥春(东关街店)"
[73] "个园"
[74] "京杭大运河(扬州段)"
[75] "东门遗址"
[76] "东关古渡"
[77] "扬州大学(瘦西湖校区)"
[78] "澳门渔人码头Macau Fisherman's Wharf"
[79] "仁慈堂大楼"
[80] "金莲花广场Golden Lotus Square"
[81] "议事亭前地Largo do Senado"
[82] "新葡京娱乐场Grand Lisboa Casino"
[83] "玫瑰圣母广场St. Dominic's Square"
[84] "威尼斯贡多拉游船"
[85] "汨罗汨江宾馆"
[86] "张谷英古村"
[87] "平江起义纪念馆"
[88] "石牛寨国家地质公园Shi Niu Zhai National geological park"
[89] "石牛寨国家地质公园Shi Niu Zhai National geological park"
[90] "蜈支洲岛码头餐厅"
[91] "河西友谊路下岗职工海鲜加工广场"
[92] "三亚免税店"
[93] "三亚海棠湾9号度假酒店Haitang Bay Gloria Resort Sanya"
[94] "三亚市鹿回头广场"
[95] "海棠广场"
[96] "三亚南山海上观音"
[97] "三亚湾"
[98] "海棠湾"
[99] "鹿回头风景区"
[100] "南山文化旅游区"
[101] "KB大桥"
[102] "红树林"
[103] "帕劳群岛The Republic of Palau"
[104] "日军沉船遗址"
[105] "长沙滩Long Beach"
[106] "帕劳国家博物馆Palau National Museum"
[107] "罗曼·莫图国际机场Palau International Airport"
[108] "小北京Little Beijing"
[109] "WCTC 购物中心WCTC shopping center"
[110] "男人会馆Abai House"
[111] "德国水道German Waterways"
[112] "鲸鱼岛"
[113] "百悦大酒店Sea Passion Hotel"
[114] "牛奶湖Milky Way"
[115] "海底大断层Big Drop Off"
[116] "捞刀河苏家托精品农家乐(捞刀河店)"
[117] "长沙规划展示馆"
[118] "南郊公园卡通乐园"
[119] "长沙柏乐园"
[120] "昱龙大盆牛蛙馆"
[121] "民间沙水面粉馆"
[122] "正哥肉串"
[123] "郭福娭小钵子甜酒"
[124] "老长沙油炸社(太平街店)"
[125] "帅哥烧饼(湖大店)"
[126] "长沙王陵公园"
[127] "长沙生态动物园"
[128] "湖南师范大学"
[129] "花明楼"
[130] "长沙坡子街"
[131] "长沙普瑞酒店(原普瑞温泉酒店)"
[132] "湖南森林植物园"
[133] "书堂山"
[134] "黑麋峰森林公园"
[135] "橘子洲音乐焰火晚会"
[136] "爱晚亭"
[137] "湘江风光带"
[138] "橘子洲"
[139] "火宫殿(坡子街总店)"
[140] "湖南省博物馆"
[141] "岳麓山风景名胜区"
[142] "烈士公园"
[143] "太平街"
[144] "开福寺"
[145] "靖港古镇"
[146] "宜春明月山维景国际温泉度假酒店Yichun Grand Metropark Resort"
[147] "温汤镇"
[148] "明月山顺天维景国际温泉度假村"
[149] "兜率岛"
[150] "兜率岩"
[151] "板梁古村"
[152] "东江湖风景旅游区"
[153] "雾漫小东江"
[154] "水母湖Jellyfish Lake"
[155] "济南泉城广场"
[156] "天波府"
[157] "金鞭溪"
[158] "大炮台"
[159] "大三巴牌坊"
[160] "香港大学The University of Hong Kong"
# 结果无省略,共160条另外还有一些关于RSelenium的页面操作,一并记录如下:
# 方法二实现“一拉到底”的(循环)滚动过程,以下是一次性/单次操作:
library(RSelenium)
shell("java -jar D:/R/library/Rwebdriver/selenium-server-standalone-3.7.1.jar",
wait = FALSE, invisible = FALSE)
url <- "http://www.mafengwo.cn/u/606971/review.html"
remDr <- remoteDriver(browserName = "chrome")
remDr$open()
remDr$setWindowSize(width = 500, height = 500)
# 打开浏览器窗口后,设置窗口大小
remDr$navigate(url)
remDr$goBack()
# 返回上一页
remDr$refresh()
# 刷新页面
webElem <- remDr$findElement("css", "body")
# 找到网页的body标签,待提取的字段通常都包含在<body>...</body>中
webElem$sendKeysToElement(list(key = "down_arrow"))
# 滚动条向下拉一小截,emmmm...真的就只有一小截
webElem$sendKeysToElement(list(key = "end"))
# 滚动条拉到当前可见的最底部,注意是当前,只加载一轮信息
remDr$executeScript("window.scrollTo(0,document.body.scrollHeight);", list(webElem))
# 使用函数executeScript执行一个JavaScript片段,是循环拉取的其中一轮操作
webElem$sendKeysToElement(list(key = "home"))
# 不论页面已经加载多少轮,返回最顶部
webElem$screenshot(display = TRUE)
# 将当前的加载位置的截图呈现在R控制台参考资料:
Streaming Data IO in R
Scrapy爬虫框架教程(四)– 抓取AJAX异步加载网页
Scrolling page in RSelenium(单次下拉:用key值)
RSelenium: Scroll down to load web content(单次下拉:嵌入js代码)
Check if it’s possible to scroll down with RSelenium(循环滚动下拉至底部)
RSelenium: Scraping a dynamically loaded page that loads slowly(下拉加载时有loading字样的处理方法)

相关文章推荐
- 编写Python爬虫抓取豆瓣电影TOP100及用户头像的方法
- 抓取豆瓣电影
- python抓取豆瓣电影
- 豆瓣电影Top250基本信息抓取
- Python学习笔记 第二部分 - 正则表达式 与 爬虫小实例(抓取豆瓣电影中评分大于等于8分的影片)
- 初试Scrapy(二)---抓取豆瓣电影排行TOP250实验
- xpath方法抓取豆瓣电影top250
- Scrapy爬虫入门系列4抓取豆瓣Top250电影数据
- Scrapy爬虫入门系列4抓取豆瓣Top250电影数据
- 使用python抓取豆瓣电影信息
- 实践Python的爬虫框架Scrapy来抓取豆瓣电影TOP250
- python selenium,PhantomJS运用 抓取滚动条滚动加载的页面, js动作操作,模拟登陆
- 分布式视频信息爬虫,抓取豆瓣,bilibili等中的电视剧、电影、动漫演员等信息
- [Python]抓取豆瓣电影列表的标题
- 爬虫小试之一(抓取豆瓣电影)
- Scrapy抓取豆瓣电影
- 用python+selenium抓取豆瓣电影中的正在热映前12部电影并按评分排序
- Python爬虫,用于抓取豆瓣电影Top前100的电影的名称
- 豆瓣电影Top250基本信息抓取
- java jsoup 网络爬虫 学习例子(二) 只抓取豆瓣电影5星(力荐)电影名称