OpenCV3.3中决策树(Decision Tree)接口简介及使用
2017-12-23 20:40
549 查看
OpenCV 3.3中给出了决策树Decision Tres算法的实现,即cv::ml::DTrees类,此类的声明在include/opencv2/ml.hpp文件中,实现在modules/ml/src/tree.cpp文件中。其中:
(1)、cv::ml::DTrees类:继承自cv::ml::StateModel,而cv::ml::StateModel又继承自cv::Algorithm;
(2)、create函数:为static,new一个DTreesImpl对象用来创建一个DTrees对象;
(3)、setMaxCategories/getMaxCategories函数:设置/获取最大的类别数,默认值为10;
(4)、setMaxDepth/getMaxDepth函数:设置/获取树的最大深度,默认值为INT_MAX;
(5)、setMinSampleCount/getMinSampleCount函数:设置/获取最小训练样本数,默认值为10;
(6)、setCVFolds/getCVFolds函数:设置/获取CVFolds(thenumber of cross-validation folds)值,默认值为10,如果此值大于1,用于修剪构建的决策树;
(7)、setUseSurrogates/getUseSurrogates函数:设置/获取是否使用surrogatesplits方法,默认值为false;
(8)、setUse1SERule/getUse1SERule函数:设置/获取是否使用1-SE规则,默认值为true;
(9)、setTruncatePrunedTree/getTruncatedTree函数:设置/获取是否进行剪枝后移除操作,默认值为true;
(10)、setRegressionAccuracy/getRegressionAccuracy函数:设置/获取回归时用于终止的标准,默认值为0.01;
(11)、setPriors/getPriors函数:设置/获取先验概率数值,用于调整决策树的偏好,默认值为空的Mat;
(12)、getRoots函数:获取根节点索引;
(13)、getNodes函数:获取所有节点索引;
(14)、getSplits函数:获取所有拆分索引;
(15)、getSubsets函数:获取分类拆分的所有bitsets;
(16)、load函数:load已序列化的model文件。
关于决策树算法的简介可以参考:http://blog.csdn.net/fengbingchun/article/details/78880934
以下是从数据集MNIST中提取的40幅图像,0,1,2,3四类各20张,每类的前10幅来自于训练样本,用于训练,后10幅来自测试样本,用于测试,如下图:

关于MNIST的介绍可以参考:http://blog.csdn.net/fengbingchun/article/details/49611549 测试代码如下:#include "opencv.hpp"
#include <string>
#include <vector>
#include <memory>
#include <algorithm>
#include <opencv2/opencv.hpp>
#include <opencv2/ml.hpp>
#include "common.hpp"
///////////////////////////////////// Decision Tree ////////////////////////////////////////
int test_opencv_decision_tree_train()
{
const std::string image_path{ "E:/GitCode/NN_Test/data/images/digit/handwriting_0_and_1/" };
cv::Mat tmp = cv::imread(image_path + "0_1.jpg", 0);
CHECK(tmp.data != nullptr);
const int train_samples_number{ 40 };
const int every_class_number{ 10 };
cv::Mat train_data(train_samples_number, tmp.rows * tmp.cols, CV_32FC1);
cv::Mat train_labels(train_samples_number, 1, CV_32FC1);
float* p = (float*)train_labels.data;
for (int i = 0; i < 4; ++i) {
std::for_each(p + i * every_class_number, p + (i + 1)*every_class_number, [i](float& v){v = (float)i; });
}
// train data
for (int i = 0; i < 4; ++i) {
static const std::vector<std::string> digit{ "0_", "1_", "2_", "3_" };
static const std::string suffix{ ".jpg" };
for (int j = 1; j <= every_class_number; ++j) {
std::string image_name = image_path + digit[i] + std::to_string(j) + suffix;
cv::Mat image = cv::imread(image_name, 0);
CHECK(!image.empty() && image.isContinuous());
image.convertTo(image, CV_32FC1);
image = image.reshape(0, 1);
tmp = train_data.rowRange(i * every_class_number + j - 1, i * every_class_number + j);
image.copyTo(tmp);
}
}
cv::Ptr<cv::ml::DTrees> dtree = cv::ml::DTrees::create();
dtree->setMaxCategories(4);
dtree->setMaxDepth(10);
dtree->setMinSampleCount(10);
dtree->setCVFolds(0);
dtree->setUseSurrogates(false);
dtree->setUse1SERule(false);
dtree->setTruncatePrunedTree(false);
dtree->setRegressionAccuracy(0);
dtree->setPriors(cv::Mat());
dtree->train(train_data, cv::ml::ROW_SAMPLE, train_labels);
const std::string save_file{ "E:/GitCode/NN_Test/data/decision_tree_model.xml" }; // .xml, .yaml, .jsons
dtree->save(save_file);
return 0;
}
int test_opencv_decision_tree_predict()
{
const std::string image_path{ "E:/GitCode/NN_Test/data/images/digit/handwriting_0_and_1/" };
const std::string load_file{ "E:/GitCode/NN_Test/data/decision_tree_model.xml" }; // .xml, .yaml, .jsons
const int predict_samples_number{ 40 };
const int every_class_number{ 10 };
cv::Mat tmp = cv::imread(image_path + "0_1.jpg", 0);
CHECK(tmp.data != nullptr);
// predict datta
cv::Mat predict_data(predict_samples_number, tmp.rows * tmp.cols, CV_32FC1);
for (int i = 0; i < 4; ++i) {
static const std::vector<std::string> digit{ "0_", "1_", "2_", "3_" };
static const std::string suffix{ ".jpg" };
for (int j = 11; j <= every_class_number + 10; ++j) {
std::string image_name = image_path + digit[i] + std::to_string(j) + suffix;
cv::Mat image = cv::imread(image_name, 0);
CHECK(!image.empty() && image.isContinuous());
image.convertTo(image, CV_32FC1);
image = image.reshape(0, 1);
tmp = predict_data.rowRange(i * every_class_number + j - 10 - 1, i * every_class_number + j - 10);
image.copyTo(tmp);
}
}
cv::Mat result;
cv::Ptr<cv::ml::DTrees> dtrees = cv::ml::DTrees::load(load_file);
dtrees->predict(predict_data, result);
CHECK(result.rows == predict_samples_number);
cv::Mat predict_labels(predict_samples_number, 1, CV_32FC1);
float* p = (float*)predict_labels.data;
for (int i = 0; i < 4; ++i) {
std::for_each(p + i * every_class_number, p + (i + 1)*every_class_number, [i](float& v){v = (float)i; });
}
int count{ 0 };
for (int i = 0; i < predict_samples_number; ++i) {
float value1 = ((float*)predict_labels.data)[i];
float value2 = ((float*)result.data)[i];
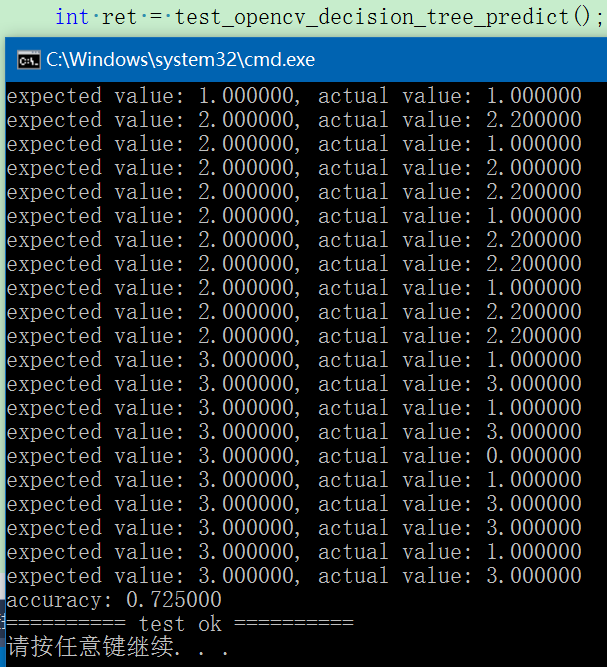
fprintf(stdout, "expected value: %f, actual value: %f\n", value1, value2);
if (int(value1) == int(value2)) ++count;
}
fprintf(stdout, "accuracy: %f\n", count * 1.f / predict_samples_number);
return 0;
} 执行结果如下:由于训练样本数量少,所以识别率只有72.5%,为了提高识别率,可以增加训练样本数。
GitHub: https://github.com/fengbingchun/NN_Test
(1)、cv::ml::DTrees类:继承自cv::ml::StateModel,而cv::ml::StateModel又继承自cv::Algorithm;
(2)、create函数:为static,new一个DTreesImpl对象用来创建一个DTrees对象;
(3)、setMaxCategories/getMaxCategories函数:设置/获取最大的类别数,默认值为10;
(4)、setMaxDepth/getMaxDepth函数:设置/获取树的最大深度,默认值为INT_MAX;
(5)、setMinSampleCount/getMinSampleCount函数:设置/获取最小训练样本数,默认值为10;
(6)、setCVFolds/getCVFolds函数:设置/获取CVFolds(thenumber of cross-validation folds)值,默认值为10,如果此值大于1,用于修剪构建的决策树;
(7)、setUseSurrogates/getUseSurrogates函数:设置/获取是否使用surrogatesplits方法,默认值为false;
(8)、setUse1SERule/getUse1SERule函数:设置/获取是否使用1-SE规则,默认值为true;
(9)、setTruncatePrunedTree/getTruncatedTree函数:设置/获取是否进行剪枝后移除操作,默认值为true;
(10)、setRegressionAccuracy/getRegressionAccuracy函数:设置/获取回归时用于终止的标准,默认值为0.01;
(11)、setPriors/getPriors函数:设置/获取先验概率数值,用于调整决策树的偏好,默认值为空的Mat;
(12)、getRoots函数:获取根节点索引;
(13)、getNodes函数:获取所有节点索引;
(14)、getSplits函数:获取所有拆分索引;
(15)、getSubsets函数:获取分类拆分的所有bitsets;
(16)、load函数:load已序列化的model文件。
关于决策树算法的简介可以参考:http://blog.csdn.net/fengbingchun/article/details/78880934
以下是从数据集MNIST中提取的40幅图像,0,1,2,3四类各20张,每类的前10幅来自于训练样本,用于训练,后10幅来自测试样本,用于测试,如下图:
关于MNIST的介绍可以参考:http://blog.csdn.net/fengbingchun/article/details/49611549 测试代码如下:#include "opencv.hpp"
#include <string>
#include <vector>
#include <memory>
#include <algorithm>
#include <opencv2/opencv.hpp>
#include <opencv2/ml.hpp>
#include "common.hpp"
///////////////////////////////////// Decision Tree ////////////////////////////////////////
int test_opencv_decision_tree_train()
{
const std::string image_path{ "E:/GitCode/NN_Test/data/images/digit/handwriting_0_and_1/" };
cv::Mat tmp = cv::imread(image_path + "0_1.jpg", 0);
CHECK(tmp.data != nullptr);
const int train_samples_number{ 40 };
const int every_class_number{ 10 };
cv::Mat train_data(train_samples_number, tmp.rows * tmp.cols, CV_32FC1);
cv::Mat train_labels(train_samples_number, 1, CV_32FC1);
float* p = (float*)train_labels.data;
for (int i = 0; i < 4; ++i) {
std::for_each(p + i * every_class_number, p + (i + 1)*every_class_number, [i](float& v){v = (float)i; });
}
// train data
for (int i = 0; i < 4; ++i) {
static const std::vector<std::string> digit{ "0_", "1_", "2_", "3_" };
static const std::string suffix{ ".jpg" };
for (int j = 1; j <= every_class_number; ++j) {
std::string image_name = image_path + digit[i] + std::to_string(j) + suffix;
cv::Mat image = cv::imread(image_name, 0);
CHECK(!image.empty() && image.isContinuous());
image.convertTo(image, CV_32FC1);
image = image.reshape(0, 1);
tmp = train_data.rowRange(i * every_class_number + j - 1, i * every_class_number + j);
image.copyTo(tmp);
}
}
cv::Ptr<cv::ml::DTrees> dtree = cv::ml::DTrees::create();
dtree->setMaxCategories(4);
dtree->setMaxDepth(10);
dtree->setMinSampleCount(10);
dtree->setCVFolds(0);
dtree->setUseSurrogates(false);
dtree->setUse1SERule(false);
dtree->setTruncatePrunedTree(false);
dtree->setRegressionAccuracy(0);
dtree->setPriors(cv::Mat());
dtree->train(train_data, cv::ml::ROW_SAMPLE, train_labels);
const std::string save_file{ "E:/GitCode/NN_Test/data/decision_tree_model.xml" }; // .xml, .yaml, .jsons
dtree->save(save_file);
return 0;
}
int test_opencv_decision_tree_predict()
{
const std::string image_path{ "E:/GitCode/NN_Test/data/images/digit/handwriting_0_and_1/" };
const std::string load_file{ "E:/GitCode/NN_Test/data/decision_tree_model.xml" }; // .xml, .yaml, .jsons
const int predict_samples_number{ 40 };
const int every_class_number{ 10 };
cv::Mat tmp = cv::imread(image_path + "0_1.jpg", 0);
CHECK(tmp.data != nullptr);
// predict datta
cv::Mat predict_data(predict_samples_number, tmp.rows * tmp.cols, CV_32FC1);
for (int i = 0; i < 4; ++i) {
static const std::vector<std::string> digit{ "0_", "1_", "2_", "3_" };
static const std::string suffix{ ".jpg" };
for (int j = 11; j <= every_class_number + 10; ++j) {
std::string image_name = image_path + digit[i] + std::to_string(j) + suffix;
cv::Mat image = cv::imread(image_name, 0);
CHECK(!image.empty() && image.isContinuous());
image.convertTo(image, CV_32FC1);
image = image.reshape(0, 1);
tmp = predict_data.rowRange(i * every_class_number + j - 10 - 1, i * every_class_number + j - 10);
image.copyTo(tmp);
}
}
cv::Mat result;
cv::Ptr<cv::ml::DTrees> dtrees = cv::ml::DTrees::load(load_file);
dtrees->predict(predict_data, result);
CHECK(result.rows == predict_samples_number);
cv::Mat predict_labels(predict_samples_number, 1, CV_32FC1);
float* p = (float*)predict_labels.data;
for (int i = 0; i < 4; ++i) {
std::for_each(p + i * every_class_number, p + (i + 1)*every_class_number, [i](float& v){v = (float)i; });
}
int count{ 0 };
for (int i = 0; i < predict_samples_number; ++i) {
float value1 = ((float*)predict_labels.data)[i];
float value2 = ((float*)result.data)[i];
fprintf(stdout, "expected value: %f, actual value: %f\n", value1, value2);
if (int(value1) == int(value2)) ++count;
}
fprintf(stdout, "accuracy: %f\n", count * 1.f / predict_samples_number);
return 0;
} 执行结果如下:由于训练样本数量少,所以识别率只有72.5%,为了提高识别率,可以增加训练样本数。
GitHub: https://github.com/fengbingchun/NN_Test

相关文章推荐
- OpenCV3.3中K-Means聚类接口简介及使用
- OpenCV3.3中 K-最近邻法(KNN)接口简介及使用
- CGI简介(Peercast使用的动态网页编程接口)
- PHP接口简介及使用
- Android SDK 百度地图通过poi城市内检索简介接口的使用
- 使用ID3算法构造决策树 - 简介、概念及实例
- OpenCV3.3中主成分分析(Principal Components Analysis, PCA)接口简介及使用
- Jsoncpp编程接口及使用方法简介
- 决策树(decision tree)简介
- OpenCV3.3中支持向量机(Support Vector Machines, SVM)实现简介及使用
- 决策树(Decision Tree)简介
- soapUI工具使用方法、简介、接口测试
- Postman Postman接口测试工具使用简介
- 大数据技术学习笔记之hive框架基础2-hive中常用DML和UDF和连接接口使用
- 第一次使用支付接口(银联接口)
- ApplicationContextAware接口的使用
- 使用python调用淘宝的ip地址库查询接口结合zabbix判断dnspod域名解析是否正确
- 抽象类和接口在C#中的区别和使用
- 抽象类与接口使用的MSDN建议
- 学习effective java-14类和接口之在公有类中使用可访问的方法,而不是使用公有域