通过scrapy,从模拟登录开始爬取知乎的问答数据
2017-12-23 17:42
501 查看
这篇文章将讲解如何爬取知乎上面的问答数据。
首先,我们需要知道,想要爬取知乎上面的数据,第一步肯定是登录,所以我们先介绍一下模拟登录:
先说一下我的思路:
1.首先我们需要控制登录的入口,重写start_requests方法。来控制到这个入口之后,使用callback回调函数来调用login函数.
2.在login函数中通过response.text获取到该页面的HTML代码,通过正则表达式提取到登录必需的xsrf值。
3.下面就是获取验证码了,这是一个难点,首先我们先观察在请求验证码时的url:

可以发现,在请求验证码时出现了一个r后面的随机数,所以我们需要生成一个随机数,并将该随机数作为参数传给请求验证码时的url;然后将该url交给scrapy下载器进行下载。
4.然后通过回调函数调用login_after_captcha ,在该函数中我们需要在请求验证码的url下载到验证码图片,让用户输入验证码并赋值给变量captcha。然后将xsrf、用户名、密码、验证码等参数存入postdata。我们就可以进行模拟登录了。
5.通过调用scrapy的FormRequest来进行模拟登录
6.模拟登录之后,调用check_login函数判断是否登录成功。
下面是模拟登录部分的源码:
需要注意的是,每次在请求一个页面时都需要带上headers。因为headers中有一个重要的参数 User-Agent,我们需要指明User-Agent。如果不加上headers的话,那么在运行时会出现500的服务器错误,这是因为默认的User-Agent是你运行的python2或python3的User-Agent,服务器并不认识。所以,在爬取知乎的时候,在请求一个页面时必须加上headers
在完成了登录之后,下面就开始我们的爬取逻辑:
爬取知乎的question需要的字段,设计数据表:
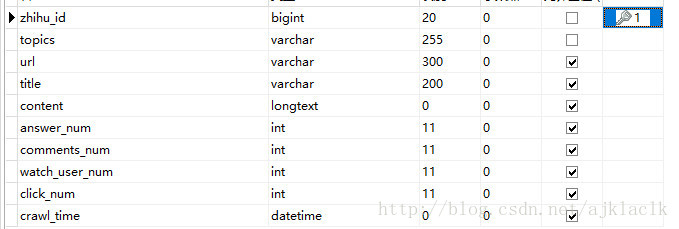
爬取知乎的question需要的字段,设计数据表:
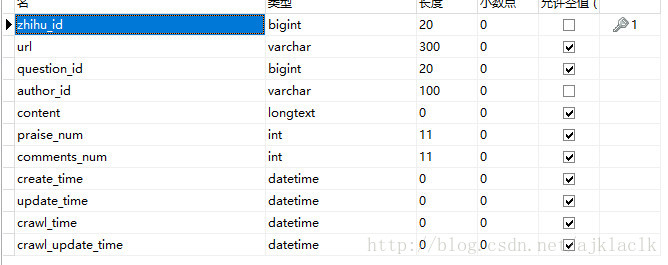
爬取的大致思路:
1.首先我们在parse方法中获取到登录之后的首页的所有url,然后过滤掉不是url的条目,然后再提取感兴趣的url。在这里可以进行一个判断,如果是我们感兴趣的url则执行回调函数parse_question,若不是感兴趣的url,那么就利用scrapy的深度优先遍历的特点进一步判断,如此重复。

2.在parse_question方法中则是对url页面中的数据解析。然后通过yield来调用回调函数解析该question对应的answer,并通过yield question_item传递给pipelines。

3.在pipelines中可以使用爬取到数据,比如存为json格式,存入数据库等等。
4.更多的解释会在源码中注解。
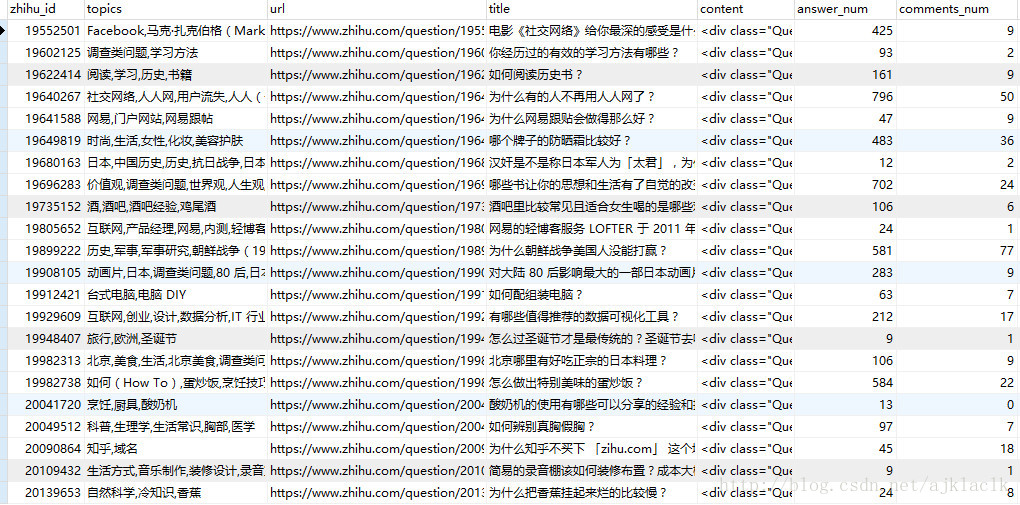
我们先看一下爬取的结果:
question表:
answer表:

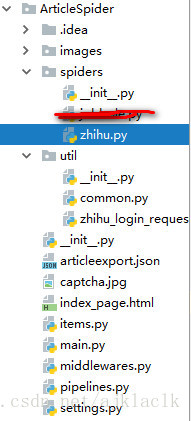
下面是整个项目的源码:
目录结构:
至此,通过scrapy从模拟登录到爬取问答数据的项目就完成了,模拟登录是在爬虫中非常重要的知识,在模拟登录成功之后,包括解析数据,将item 传入pipelines,数据表的创建,pipelines和items的配置,入库等也就变得很简单了;在这个项目中,在解析answer的数据时,我们采用的是json格式直接提取的,因为url直接给我们返回了json格式的文件,这样也就简化了我们解析数据的操作。
首先,我们需要知道,想要爬取知乎上面的数据,第一步肯定是登录,所以我们先介绍一下模拟登录:
先说一下我的思路:
1.首先我们需要控制登录的入口,重写start_requests方法。来控制到这个入口之后,使用callback回调函数来调用login函数.
2.在login函数中通过response.text获取到该页面的HTML代码,通过正则表达式提取到登录必需的xsrf值。
3.下面就是获取验证码了,这是一个难点,首先我们先观察在请求验证码时的url:
可以发现,在请求验证码时出现了一个r后面的随机数,所以我们需要生成一个随机数,并将该随机数作为参数传给请求验证码时的url;然后将该url交给scrapy下载器进行下载。
4.然后通过回调函数调用login_after_captcha ,在该函数中我们需要在请求验证码的url下载到验证码图片,让用户输入验证码并赋值给变量captcha。然后将xsrf、用户名、密码、验证码等参数存入postdata。我们就可以进行模拟登录了。
5.通过调用scrapy的FormRequest来进行模拟登录
6.模拟登录之后,调用check_login函数判断是否登录成功。
下面是模拟登录部分的源码:
def start_requests(self): #控制登录入口,实现知乎的登录
return [scrapy.Request('https://www.zhihu.com/#signin',headers=self.header,callback=self.login)]
def login(self,response):
response_text=response.text
xsrf_obj = re.match('.*name="_xsrf" value="(.*)".*', response_text,re.DOTALL)
xsrf=""
if xsrf_obj:
xsrf=xsrf_obj.group(1)
else:
return ""
if xsrf:
post_data = { # 传递的数据
"_xsrf": xsrf,
"phone_num": "你的账号",
"password": "你的密码",
"captcha":""
}
import time
t = str(int(time.time() * 1000))
captcha_url = "https://www.zhihu.com/captcha.gif?r={0}&type=login & lang=cn".format(t)
yield scrapy.Request(captcha_url, headers=self.header, meta={"post_data": post_data},
callback=self.login_after_captcha)
def login_after_captcha(self, response):
with open("captcha.jpg", "wb") as f: #下载验证码图片
f.write(response.body) #这里必须为body
f.close()
from PIL import Image
try:
im = Image.open('captcha.jpg')
im.show()
im.close()
except:
pass
captcha = input("输入验证码\n>")
post_data = response.meta.get("post_data", {})
post_url = "https://www.zhihu.com/login/phone_num"
post_data["captcha"] = captcha #将验证码的值传给post_data
return [scrapy.FormRequest(
url=post_url,
formdata=post_data,
headers=self.header,
callback=self.check_login #调用scrapy的FormRequest完成表单提交,,即模拟登录,登录之后调用check_login判断登录状态
)]
def check_login(self, response):
# 验证服务器的返回数据判断是否成功
text_json = json.loads(response.text) #response.text存放了登录成功或其他提示信息 的Unicode编码,
# 我们将其加载为json格式。json格式中的msg(message字段存放了中文字符的登录提示信息)
if "msg" in text_json and text_json["msg"] == "登录成功":
for url in self.start_urls:
yield scrapy.Request(url, dont_filter=True, headers=self.header)
#在执行完check_login方法之后,因为我们在最后没有加callback函数,所以默认会调用parse方法需要注意的是,每次在请求一个页面时都需要带上headers。因为headers中有一个重要的参数 User-Agent,我们需要指明User-Agent。如果不加上headers的话,那么在运行时会出现500的服务器错误,这是因为默认的User-Agent是你运行的python2或python3的User-Agent,服务器并不认识。所以,在爬取知乎的时候,在请求一个页面时必须加上headers
在完成了登录之后,下面就开始我们的爬取逻辑:
爬取知乎的question需要的字段,设计数据表:
爬取知乎的question需要的字段,设计数据表:
爬取的大致思路:
1.首先我们在parse方法中获取到登录之后的首页的所有url,然后过滤掉不是url的条目,然后再提取感兴趣的url。在这里可以进行一个判断,如果是我们感兴趣的url则执行回调函数parse_question,若不是感兴趣的url,那么就利用scrapy的深度优先遍历的特点进一步判断,如此重复。
2.在parse_question方法中则是对url页面中的数据解析。然后通过yield来调用回调函数解析该question对应的answer,并通过yield question_item传递给pipelines。
3.在pipelines中可以使用爬取到数据,比如存为json格式,存入数据库等等。
4.更多的解释会在源码中注解。
我们先看一下爬取的结果:
question表:
answer表:
下面是整个项目的源码:
目录结构:
zhihu.py
import scrapy
import re
import json
from scrapy.loader import ItemLoader
from ArticleSpider.items import ZhihuQuestionItem,Art
4000
icleItemLoader,ZhihuAnswerItem
import datetime
try:
import urlparse as parse
except:
from urllib import parse
class ZhihuSpider(scrapy.Spider):
name = 'zhihu'
allowed_domains = ['www.zhihu.com']
start_urls = ['http://www.zhihu.com/']
#question的第一页answer请求url
start_answer_url="https://www.zhihu.com/api/v4/questions/{0}/answers?include=data[*].is_normal,admin_closed_comment,reward_info,is_collapsed,annotation_action,annotation_detail,collapse_reason,is_sticky,collapsed_by,suggest_edit,comment_count,can_comment,content,editable_content,voteup_count,reshipment_settings,comment_permission,created_time,updated_time,review_info,relevant_info,question,excerpt,relationship.is_authorized,is_author,voting,is_thanked,is_nothelp,upvoted_followees;data[*].mark_infos[*].url;data[*].author.follower_count,badge[?(type=best_answerer)].topics&offset={1}limit={2}&sort_by=default"
header = {
"Host": "www.zhihu.com",
"Referer": "https://www.zhihu.com",
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:57.0) Gecko/20100101 Firefox/57.0"
}
def parse(self, response): #该函数的response.text是传过来的登录成功之后的html代码
#提取出HTML页面中的所有url,并跟踪这些url进行进一步爬取(深度优先算法)
#如果提取的url中格式为/question/xxx 就下载之后直接进入解析函数
all_urls=response.css("a::attr(href)").extract() #提取所有的url
all_urls=[parse.urljoin(response.url,url) for url in all_urls] #拼接特殊的URL
all_urls=filter(lambda x:True if x.startswith("https") else False,all_urls) #使用匿名函数过滤掉不是url的条目
for url in all_urls:
match_obj=re.match("(.*zhihu.com/question/(\d+))($|/).*",url) #提取感兴趣URL(question/id)
if match_obj: #如果提取到question相关的页面
request_url=match_obj.group(1) #提取url
question_id=match_obj.group(2) #提取question id
yield scrapy.Request(request_url,headers=self.header,meta={"question_id":question_id},callback=self.parse_question)
else: #如果不是question相关的url,则进行深度优先算法的提取
yield scrapy.Request(url,headers=self.header,callback=self.parse)
pass
def parse_question(self,response):
#获取到question的URL之后 ,调用该方法进行处理
if "QuestionHeader-title" in response.text: #处理新版本
click_num=response.css(".NumberBoard-value::text").extract()[1]
question_id = response.meta.get("question_id", "") #获取question_id字典。
item_loader = ItemLoader(item=ZhihuQuestionItem(), response=response)
item_loader.add_css("title",".QuestionHeader-title::text") #标题
item_loader.add_css("content",".QuestionHeader-detail")
item_loader.add_value("url",response.url) #该页面的url
item_loader.add_value("zhihu_id",question_id)
item_loader.add_css("answer_num",".List-headerText span::text")#extract之后['10',' 个回答'] 回答数
item_loader.add_css("comments_num",".QuestionHeader-Comment button::text") #extract之后['1 条评论']
item_loader.add_css("watch_user_num",".NumberBoard-value::text")#这里会提取关注数和被浏览数两个
item_loader.add_value("click_num",click_num) #这里会提取关注数和被浏览数两个
item_loader.add_css("topics",".QuestionHeader-topics .Popover div::text") #话题
question_item=item_loader.load_item()
else:
#处理老版本页面的item提取
question_id = response.meta.get("question_id", "")
item_loader = ItemLoader(item=ZhihuQuestionItem(), response=response)
item_loader.add_css("title", "#zh-question-title h2 a::text")
item_loader.add_css("content", "#zh-question-detail")
item_loader.add_value("url", response.url)
item_loader.add_value("zhihu_id", question_id)
item_loader.add_css("answer_num", "#zh-question-answer-num::text")
item_loader.add_css("comments_num", "#zh-question-meta-wrap a[name='addcomment']::text")
item_loader.add_css("topics", ".zm-tag-editor-labels a::text")
question_item = item_loader.load_item()
yield scrapy.Request(self.start_answer_url.format(question_id,0,20),headers=self.header,callback=self.parse_answer)
yield question_item
def parse_answer(self,response):
#由于返回的是json文件
answer_json=json.loads(response.text)
is_end=answer_json["paging"]["is_end"] #布尔类型
next_url=answer_json["paging"]["next"]
for answer in answer_json["data"]:
answer_item=ZhihuAnswerItem()
answer_item["zhihu_id"]=answer["id"]
answer_item["url"]=answer["url"]
answer_item["question_id"]=answer["question"]["id"]
answer_item["author_id"]=answer["author"]["id"] if "id" in answer["author"] else None
answer_item["content"]=answer["content"] if "content" in answer else None
answer_item["praise_num"]=answer["voteup_count"]
answer_item["comments_num"]=answer["comment_count"]
answer_item["create_time"]=answer["created_time"] #该网页返回给我们的int类型
answer_item["update_time"]=answer["updated_time"]# 该网页返回给我们的int类型
answer_item["crawl_time"]=datetime.datetime.now() # 2017-12-22 22:30:47.061460
yield answer_item
if not is_end: #如果不是最后一个回答url
yield scrapy.Request(next_url,headers=self.header,callback=self.parse_answer)
def start_requests(self): #控制登录入口,实现知乎的登录
return [scrapy.Request('https://www.zhihu.com/#signin',headers=self.header,callback=self.login)]
#在重写start_requests方法之后,scrapy首先会执行该方法,请求的页面是登录界面,请求头为上面我们定义的,然后因为
#scrapy是异步处理的缘故,所以在执行完该方法之后,我们需要加一个callback回调函数,来调用登录方法,如果不加上callback
#指明回调函数,那么scrapy默认会直接调用parse方法。
def login(self,response):
response_text=response.text
xsrf_obj = re.match('.*name="_xsrf" value="(.*)".*', response_text,re.DOTALL)
xsrf=""
if xsrf_obj:
xsrf=xsrf_obj.group(1)
else:
return ""
if xsrf:
post_data = { # 传递的数据
"_xsrf": xsrf,
"phone_num": "你的用户名",
"password": "你的密码",
"captcha":""
}
import time
t = str(int(time.time() * 1000))
captcha_url = "https://www.zhihu.com/captcha.gif?r={0}&type=login & lang=cn".format(t)
yield scrapy.Request(captcha_url, headers=self.header, meta={"post_data": post_data},
callback=self.login_after_captcha) #meta表示字典,里面存放了post_data。这里保证了是同一个session中的cookie
def login_after_captcha(self, response):
with open("captcha.jpg", "wb") as f: #下载验证码图片
f.write(response.body) #这里必须为body
f.close()
from PIL import Image
try:
im = Image.open('captcha.jpg')
im.show()
im.close()
except:
pass
captcha = input("输入验证码\n>")
post_data = response.meta.get("post_data", {})
post_url = "https://www.zhihu.com/login/phone_num"
post_data["captcha"] = captcha #将验证码的值传给post_data
return [scrapy.FormRequest(
url=post_url,
formdata=post_data,
headers=self.header,
callback=self.check_login #调用scrapy的FormRequest完成表单提交,,即模拟登录,登录之后调用check_login判断登录状态
)]
def check_login(self, response):
# 验证服务器的返回数据判断是否成功
text_json = json.loads(response.text) #response.text存放了登录成功或其他提示信息 的Unicode编码,
# 我们将其加载为json格式。json格式中的msg(message字段存放了中文字符的登录提示信息)
if "msg" in text_json and text_json["msg"] == "登录成功":
for url in self.start_urls:
yield scrapy.Request(url, dont_filter=True, headers=self.header)
#在执行完check_login方法之后,因为我们在最后没有加callback函数,所以默认会调用parse方法common.py
import hashlib import re def get_purenum(text): str_re = ".*?(\d+).*" # 提取整数部分并返回int类型 text = re.match(str_re, text) if text: return int(text.group(1)) else: return 0
items.py
import scrapy
from scrapy.loader.processors import MapCompose,TakeFirst,Join
from scrapy.loader import ItemLoader
import re
from ArticleSpider.util.common import get_purenum
import datetime
from ArticleSpider.settings import SQL_DATETIME_FORMAT,SQL_DATE_FORMAT
class ZhihuQuestionItem(scrapy.Item):
#入库前处理
#知乎question实体类
zhihu_id=scrapy.Field(
)
topics=scrapy.Field(
)
url=scrapy.Field()
title=scrapy.Field()
content=scrapy.Field()
create_time=scrapy.Field()
update_time=scrapy.Field()
answer_num=scrapy.Field()
comments_num=scrapy.Field()
watch_user_num=scrapy.Field()
click_num=scrapy.Field()
crawl_time=scrapy.Field() #爬虫爬取的时间
def get_insertsql(self):
insert_sql = "insert into zhihu_question(zhihu_id,topics,url,title,content," \
"answer_num,comments_num,watch_user_num,click_num,crawl_time) VALUES(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s) ON DUPLICATE KEY UPDATE topics=VALUES(topics),content=VALUES(content),answer_num=values(answer_num), " \
"comments_num=values(comments_num),watch_user_num=values(watch_user_num),click_num=values(click_num)"
zhihu_id = int("".join(self["zhihu_id"]))
topics = ",".join(self["topics"])
url = self["url"][0]
title = "".join(self["title"]) # ItemLoader是list类型,在这里进行处理转为str类型或者int类型
content = "".join(self["content"])
answer_num = get_purenum("".join(self["answer_num"]))
comments_num = get_purenum(self["comments_num"][0])
watch_user_num = int(self["watch_user_num"][0])
click_num = int(self["click_num"][0])
crawl_time = datetime.datetime.now().strftime(SQL_DATETIME_FORMAT) #将时间格式化为我们在setting中指定的格式
params = (zhihu_id, topics, url, title, content, answer_num, comments_num,
watch_user_num, click_num, crawl_time)
return insert_sql,params
class ZhihuAnswerItem(scrapy.Item):
#知乎回答item
zhihu_id=scrapy.Field()
url=scrapy.Field()
question_id=scrapy.Field()
author_id=scrapy.Field()
content=scrapy.Field()
praise_num=scrapy.Field()
comments_num=scrapy.Field()
create_time=scrapy.Field()
update_time=scrapy.Field()
crawl_time=scrapy.Field()
def get_insertsql(self):
insert_sql = "insert into zhihu_answer(zhihu_id,url,question_id,author_id,content," \
"praise_num,comments_num,create_time,update_time,crawl_time) VALUES(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s) ON DUPLICATE KEY UPDATE " \
"content=VALUES(content),praise_num=VALUES(praise_num),comments_num=VALUES(comments_num),update_time=VALUES(update_time)"
# 调用datetime fromtimestamp方法将int 转为datetime类型(年月日时分秒都有),然后再格式化为指定格式
create_time = datetime.datetime.fromtimestamp(self["create_time"]).strftime(SQL_DATETIME_FORMAT)
update_time = datetime.datetime.fromtimestamp(self["update_time"]).strftime(SQL_DATETIME_FORMAT)
params=(self["zhihu_id"],self["url"],self["question_id"],self["author_id"],self["content"]
,self["praise_num"],self["comments_num"],create_time,update_time,self["crawl_time"].strftime(SQL_DATETIME_FORMAT))
return insert_sql,paramspipelines.py
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exporters import JsonItemExporter
import MySQLdb
from twisted.enterprise import adbapi
import MySQLdb.cursors
class ArticlespiderPipeline(object):
def process_item(self, item, spider): #item中的values存放了tiems的所有属性
return item
class JsonExporterPipeline(object):
#调用scrapy提供的JsonExporter导出json文件
def __init__(self):
self.file=open('articleexport.json','wb')#打开文件.wb表示以二进制的方式
self.exporter=JsonItemExporter(self.file,encoding="utf-8",ensure_ascii=False) #传递参数
self.exporter.start_exporting() #开始导出
def close_spider(self,spider):
self.exporter.finish_exporting() #停止导出
self.file.close() #关闭文件
def process_item(self, item, spider):
self.exporter.export_item(item)
return item
class MysqlTwistedPipeline(object):
#若每一个网站写一个Pipeline,那么需要大数量的mysql的连接,显然是不合理的,所以
#在实际开发中,往往是插入不同的数据库使用不同的pipeline
# 通过Twisted框架提供的异步容器,将数据通过异步的方式存储到mysql中
def __init__(self,dbpool):
self.dbpool=dbpool
@classmethod
def from_settings(cls,settings):
dbparams=dict(
host=settings["MYSQL_HOST"],
db=settings["MYSQL_DBNAME"],
user=settings["MYSQL_USER"],
passwd=settings["MYSQL_PASSWORD"],
charset="utf8",
cursorclass=MySQLdb.cursors.DictCursor,
use_unicode=True
)
dbpool=adbapi.ConnectionPool("MySQLdb",**dbparams) #连接池
return cls(dbpool) #返回MysqlTwistedPipeline类的一个实例化对象
def process_item(self, item, spider):
query=self.dbpool.runInteraction(self.do_insert,item) #异步的插入操作
query.addErrback(self.handle_error,item,spider) #处理异步插入的异常
def handle_error(self,failure,item,spider):
print(failure) #发生异常时直接输出异常信息
def do_insert(self,cursor,item):
insert_sql,params=item.get_insertsql() #调用对应的item的get_insertsql方法,获取到不同的sql语句,和params元组
cursor.execute(insert_sql,params)setting.py
ITEM_PIPELINES = {
'ArticleSpider.pipelines.ArticlespiderPipeline': 300,
'ArticleSpider.pipelines.JsonExporterPipeline': 2 , #保存为Json文件
# 'ArticleSpider.pipelines.MysqlPipeline': 3 #将数据同步存储到数据库
'ArticleSpider.pipelines.MysqlTwistedPipeline':3 #将数据异步插入到数据库
}
MYSQL_HOST="localhost"
MYSQL_DBNAME="article_spider"
MYSQL_USER="root"
MYSQL_PASSWORD="751324"
SQL_DATETIME_FORMAT="%Y-%m-%d %H:%M:%S" #详细时间类型
SQL_DATE_FORMAT="%Y-%m-%d" #日期类型至此,通过scrapy从模拟登录到爬取问答数据的项目就完成了,模拟登录是在爬虫中非常重要的知识,在模拟登录成功之后,包括解析数据,将item 传入pipelines,数据表的创建,pipelines和items的配置,入库等也就变得很简单了;在这个项目中,在解析answer的数据时,我们采用的是json格式直接提取的,因为url直接给我们返回了json格式的文件,这样也就简化了我们解析数据的操作。

相关文章推荐
- php小代码----curl模拟登录及登录后并通过多线程进行重复post数据提交
- 【python爬虫03】使用Scrapy框架模拟登录知乎
- 用scrapy 模拟知乎的登录过程
- scrapy 通过FormRequest模拟登录再继续
- session或scrapy实现模拟登录知乎
- Scrapy模拟登录抓数据基本应用
- 使用requests和scrapy模拟知乎登录
- Scrapy 通过登录的方式爬取豆瓣影评数据
- Scrapy模拟登录知乎
- PHP通过CURL模拟登录并获取数据
- PHP curl 模拟登录并获取数据
- HttpClient4.4.1模拟登录知乎
- Android(Java) 模拟登录知乎并抓取用户信息
- AspCms 模拟limit执行从第N个开始调用数据
- 【python】模拟用户登录爬取数据带cookie情况处理
- python爬虫框架scrapy实现模拟登录操作示例
- 使用Scrapy实现模拟登录的方法
- web全栈应用【爬取(scrapy)数据 -> 通过restful接口存入数据库 -> websocket推送展示到前台】
- thinkphp 通过获取用户登录时的session_id来获取session里面的数据传到前台默认显示
- douban 模拟自动登录爬去数据