初识Hadoop
2017-12-23 16:50
190 查看
1,Hadoop的组成
两个核心组成
HDFS: 分布式文件系统,存储海量的数据
MapReduce: 并行处理框架,实现任务分解和调度
2,HDFS
HDFS中的文件被分成块进行存储,默认的块大小为64MB, 块是文件存储处理的逻辑单元
HDFS中有两类节点 NameNode和DataNode
2.1,NameNode是管理节点,存放文件元数据
文件与数据块的映射表
数据块与数据节点的映射表
2.2,DataNode是HDFS的工作节点,存放数据块
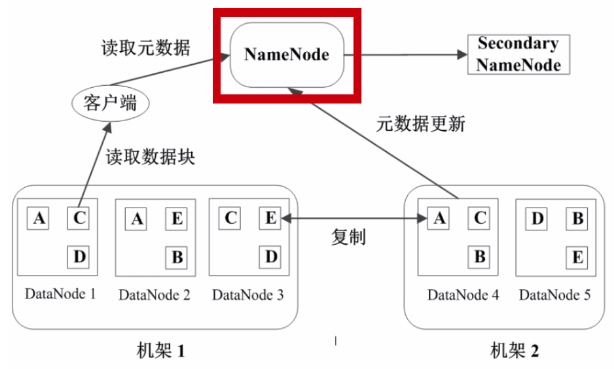
2.3,HDFS中的数据管理与容错
每个数据块3个副本,分布在两个机架内的三个节点
DataNode定期向NameNode发送心跳消息
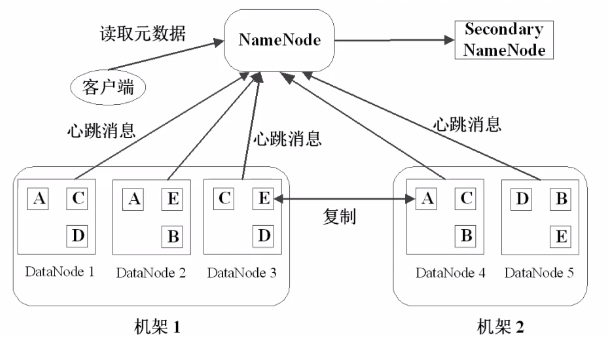
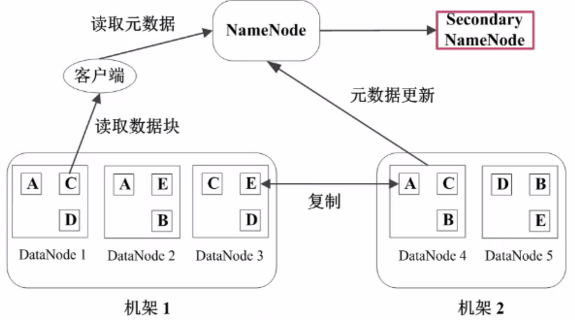
二级NameNode定期同步元数据映像文件和修改日志,当NameNode发生故障时,备胎转正
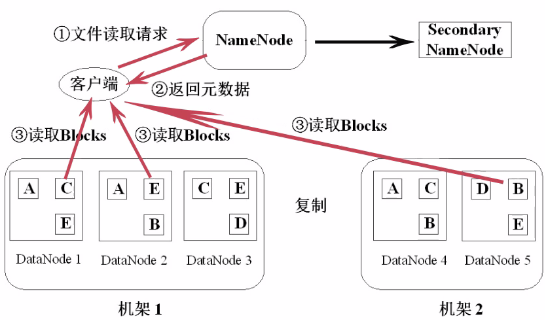
HDFS读取文件的流程
HDFS写入文件的流程

3,MapReduce原理
分而治之,一个大任务分成多个小的子任务(map) 并行执行后,合并结果(reduce)

3.1,MapReduce中的基本概念
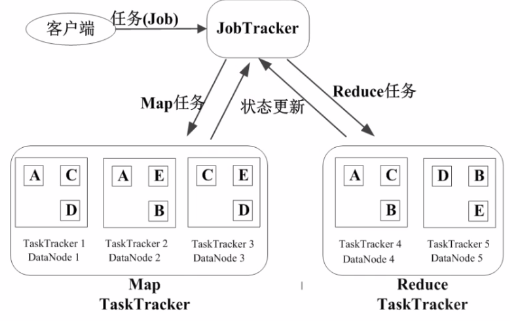
JobTracker的角色
作业调度
分配任务,监控任务执行进度
监控TaskTracker的状态
TaskTracker的角色
执行任务
汇报任务状态

3.2,MapReduce的容错机制
重复执行(最多重复4次)
推测执行
两个核心组成
HDFS: 分布式文件系统,存储海量的数据
MapReduce: 并行处理框架,实现任务分解和调度
2,HDFS
HDFS中的文件被分成块进行存储,默认的块大小为64MB, 块是文件存储处理的逻辑单元
HDFS中有两类节点 NameNode和DataNode
2.1,NameNode是管理节点,存放文件元数据
文件与数据块的映射表
数据块与数据节点的映射表
2.2,DataNode是HDFS的工作节点,存放数据块
2.3,HDFS中的数据管理与容错
每个数据块3个副本,分布在两个机架内的三个节点
DataNode定期向NameNode发送心跳消息
二级NameNode定期同步元数据映像文件和修改日志,当NameNode发生故障时,备胎转正
HDFS读取文件的流程
HDFS写入文件的流程
3,MapReduce原理
分而治之,一个大任务分成多个小的子任务(map) 并行执行后,合并结果(reduce)
3.1,MapReduce中的基本概念
JobTracker的角色
作业调度
分配任务,监控任务执行进度
监控TaskTracker的状态
TaskTracker的角色
执行任务
汇报任务状态
3.2,MapReduce的容错机制
重复执行(最多重复4次)
推测执行

相关文章推荐
- easyhadoop初识以及各种问题
- 第一章之初识Hadoop笔记
- 初识Hadoop
- 《Hadoop基础教程》之初识Hadoop
- Hadoop学习1(初识hadoop)
- Hadoop学习之路(十三)MapReduce的初识
- 初识Hadoop学习记录
- 初识Hadoop学习记录
- Hadoop学习笔记—1.初识hadoop
- 初识Hadoop入门介绍
- hadoop初识之五:hadoop启动方式、机器上必须的配置、本地native库配置、及hadoop编译
- 初识Hadoop(1)
- 第1章 初识hadoop
- 《Hadoop基础教程》之初识Hadoop
- hadoop学习笔记--6.MapReduce的初识
- 《Hadoop基础教程》之初识Hadoop
- 初识Hadoop
- 初识Hadoop
- 《Hadoop基础教程》之初识Hadoop
- Hadoop学习(一) — 初识Hadoop