manacher&&后缀数组
2017-12-22 21:37
148 查看
一、manacher:
1、主体思想:
用一个辅助数组P记录以每个字符为中心的最长回文半径。 P[i]最小为1, 此时回文串为Str[i] 本身。MaxId:之前所有求出的回文串所能到达的最右端点
id:能到达最右端点的那个字符串的中心位置
如果i的初始值没有到达MaxId这个边界,那么就说明这已经是他的极限了,下一个字符一定不匹配
如果到达了边界,那么就一定会推动MaxId向右走,而这个总量最多是O(N)的
2、代码实现:
int Init() {
int len = strlen(s);
s_new[0] = '$';
s_new[1] = '#';
int j = 2;
for (int i = 0; i < len; i++) {
s_new[j++] = s[i];
s_new[j++] = '#';
}
s_new[j] = '\0';
return j;
}
int Manacher() {
int len = Init();
int max_len = -1;
int id;
int mx = 0;
for (int i = 1; i < len; i++) {
if (i < mx)
p[i] = min(p[2 * id - i], mx - i);
else
p[i] = 1;
while (s_new[i - p[i]] == s_new[i + p[i]])
p[i]++;
if (mx < i + p[i]) {
id = i;
mx = i + p[i];
}
max_len = max(max_len, p[i] - 1);
}
return max_len;
}3、例题鉴赏:
bzoj 2565 最长双回文串最后的答案一定可以表示成左右两个回文串中的某个扩展到极限的情况
由于两个回文串对答案的贡献是同样的,所以我们不妨强制令右侧的回文串扩展至极限
枚举右侧的这个回文串中心点,我们需要在所有右端点能扩展到i-p[i]的中心点中选一个最靠左的
也就是说在manacher的过程中要对每个点维护一个“最早扩展到这个点的中心位置”
发现,以i+rl[i]结尾的回文串长度为rl[i]-1(不算中间的’‘),以i+rl[i]-2结尾的回文串长度自然就是rl[i]-1-2(再说一遍,不算中间的’‘)。然后我们只需要从左到右扫一遍,令ls[i]=max(ls[i],ls[i-2]-2)就行了
[Poi2010]Antisymmetry
我们判断能否向两边扩展的时候,把条件从s[i-p[i]]==s[i+p[i]]改成s[i-p[i]]+s[i+p[i]]==1这样的就好了
二、后缀数组:
后缀数组(suffix array):一维数组,他保存0…n-1的某个排列sa[0],sa1….sa[n-1],并且保证Suffix(sa[i])大于Suffix(sa[i+1]),0<=i大于n-1也就是将字符串S的n个后缀从小到大进行排序之后把排好序的后缀的开头位置顺次放入sa中名次数组:名次数组rank[i]表示的是Suffix(i)在所有后缀中从小到大的排名
height数组:定义height[i]=suffix(sa[i-1])和suffix(sa[i])的最长公共前缀,也就是排名相邻的两个后缀的最长公共前缀。
height数组有以下性质:height[rank[i]]≥height[rank[i-1]]-1
证明如下:当height[rank[i-1]]<=1时,原式显然成立
否则设suffix(k)是排在suffix(i-1)前一个的后缀,则根据定义他们的最长公共前缀为height[rank[i-1]],那么suffix(k+1)将排在suffix(i)前面,而这个公共前缀至少为height[rank[i-1]]-1
对于j和k,不妨设rank[j]
1、基数排序:
主要思想:将每个元素视为若干个关键字,然后按优先级从低到高依次排序
(例如我们可以将132视为拥有三个关键字的元素,其中1是第一关键字,3是第二关键字,2是第三关键字
而我们就是从第三关键字开始排序,然后排第二关键字,最后按照第一关键字排序)
而对于每次排序过程,我们依次把他们放入桶中再顺序拿出
复杂度:时间复杂度O(M*(N+X)),空间复杂度O(N+X)
2、HASH:
在字符串相关问题中我们可能会频繁的遇到要求判断两个字符串是否相同的操作一个一个字符比较显然太慢,那么我们可以用哈希算法来替代
对于一个长度为N的字符串,我们可以定义他的哈希值为:
(S1*base^(N-1)+S[2]*base^(N-2)+…+S[N-1]*base^1+S
*1)%mod
如果两个字符串hash值相同,我们可以姑且认为这两个字符串是相同的
Hash值的计算方式:i从1到N,H[i]=(H[i-1]*base+S[i])%mod
这样我们可以O(N)计算出长度为N的字符串的每一个子串的hash值
3、倍增算法:
倍增算法的主要思路是:用倍增的方法对每个字符开始的长度为2^k的子字符串进行排序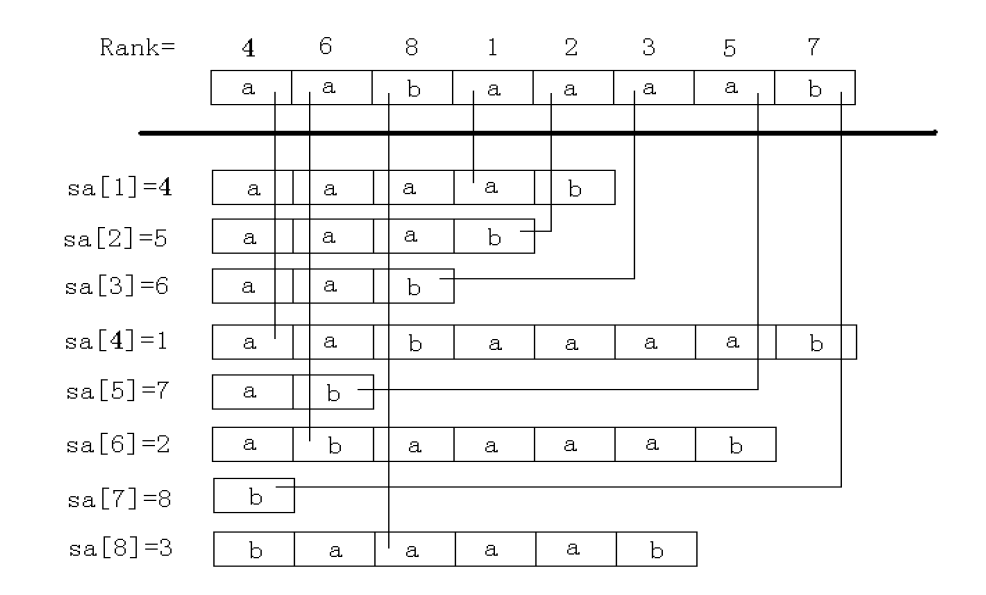
4、代码实现:
int wa[maxn],wb[maxn],wv[maxn],ws[maxn];
int cmp(int *r , int a, int b, int l){
return r[a] == r && r[a+l] == r[b+l];
}
void da (int *r , int *sa , int n, int m){
int i, j, p, *x = wa, *y = wb , *t;
for(i = 0; i < m; i++) ws[i] = 0;
for(i = 0; i < n; i++) ws[x[i] = r[i]]++;
for(i = 1; i < m; i++) ws[i] += ws[i-1];
for(i = n-1; i >= 0; i--) sa[--ws[x[i]]] = i;
for(j = 1,p = 1; p < n ; j <<= 1,m = p){
for(p = 0, i = n - j; i < n; i++) y[p++]=i;
for(i = 0; i < n; i++)if(sa[i] >= j)y[p++] = sa[i] - j;
for(i = 0; i < n; i++) wv[i] = x[y[i]];
for(i = 0; i < m; i++) ws[i] = 0;
for(i = 0; i < n; i++) ws[wv[i]]++;
for(i = 1; i < m; i++) ws[i] += ws[i-1];
for(i = n-1; i >= 0; i--) sa[--ws[wv[i]]] = y[i];
for(t = x,x=y,y=t,p=1,x[sa[0]]=0,i=1; i<n;i++)
x[sa[i]]=cmp(y,sa[i-1],sa[i],j)?p-1:p++;
}
}[b]5、例题鉴赏:
可重叠最长重复子串:给定一个字符串,求最长重复出现的子串,这两个子串可以重叠实际上求的就是height数组最大值
[JSOI2007]字符加密Cipher
把这个字符串拼接到自身的后方,然后求出后缀数组
最后我们只需要知道新串中前半部分的相对顺序就可以了
即求出rank[0]~rank[n-1]的相对顺序
[Ahoi2013]差异
化简式子之后除了常数实际上就剩下求所有的lcp(i,j)的和
我们考虑lcp(i,j)实际上就是rank[i]+1到rank[j]的height值取min
所以我们可以先求出height数组,然后问题就转化为了在这个数组中任取i,j,然后对区间最小值求和
这就是一个经典的单调栈问题了
正反各扫一遍求出以每个数为最小值的左端点和右端点,从而求出区间个数
然后用n*(n+1)/2*(n-1)减去这个答案就好了
[Tjoi2013]单词
我们在单词中加入分隔符来防止匹配错位的发生,并记录每个单词的起始位置,然后求出后缀数组
对于每个单词x,设他的起始位置为i,长度为l,他出现的次数等于从sa[i]向两边一直扩展,并保证height[j]>=l的最大范围
这一步我们可以用RMQ+二分来做
总时间复杂度O(字符串总长度logn)
[2010Beijing Wc]外星联络
先求出后缀数组,然后按照字典序顺序在后缀数组里扫每个子串
扫的同时顺便求一下他出现了几次

相关文章推荐
- manacher 后缀数组 AC自动机 回文自动机 知识点讲解 课件
- 【BZOJ】1692 & 1640: [Usaco2007 Dec]队列变换(后缀数组+贪心)
- 后缀数组模板-boj477.新来的小妹妹 & boj477. 田田背课文
- 数据库应用-后缀树及后缀数组(Suffix-Bäume&Suffix-Arraz)-1
- HDU 4080 Stammering Aliens && 后缀数组
- HiHocoder1415 : 后缀数组三·重复旋律3 & Poj2774:Long Long Message
- Lightoj-1428 Melody Comparison(kmp&&后缀数组)
- cf244D. Match & Catch 字符串hash (模板)或 后缀数组。。。
- Manacher算法,回文串及后缀数组问题
- 后缀数组 Poj---1743 : Musical Theme
- 数据库应用-后缀树及后缀数组(Suffix-Bäume&Suffix-Arraz)-2
- HDU 5030 Rabbit's String 后缀数组 二分 构造
- Manacher算法,回文串及后缀数组问题
- URAL 1297 Palindrome 后缀数组 或 Manacher 求最长回文子串
- Manacher算法,回文串及后缀数组问题
- POJ3617:Best Cow Line (贪心&&后缀数组)
- 【转载&总结】后缀数组及广泛应用
- CSU - 1551 Longest Increasing Subsequence Again —— 线段树/树状数组 + 前缀和&后缀和
- CF #244 (Div. 2) D Match & Catch (后缀数组 仅出现一次最短公共子串)
- cf244D. Match & Catch 字符串hash (模板)或 后缀数组。。。