Java小应用日志级别异常处理最佳实践
2017-12-22 17:00
1341 查看
编者按:做了很多年IT工作,突然又对日志级别有些迷茫,哈哈,为什么要有又字。是的,人们都在实践中不停的学习并增进自己。写了好久的字,盯住看3分钟,然后你会想,哦?写错了吧 ^_^
原文在: https://stackify.com/java-logging-best-practices/ 。是官方的内容,至于ELKB,也是类似的东西
注意:需要关注的是这里面的思想,以及架构、核心编码、编码人员应该注意什么?
后段关于软件的使用没仔细校对,直接走的翻译软件。注意思想和目标
Java小应用日志及异常处理最佳实践
日志我们应该做的更好了
是时候严肃对待日志了
开始记录所有的事情
Walk the Code
输出更多的诊断上下文详细信息
查找你的日志
发现Java 异常详情
监控
错误率
解决的错误和新的错误
日志监控
Java 日志最佳实践
你曾经脱离开发部门去查看过日志文件吗?如果你做过这些事情,你很快会意识到一些问题。
有大量的数据
你需要访问数据
分布在多个服务器
一个具体的操作可能是跨应用的,因此你需要查看多个日志
日志都是流水性的,很难查询。就算你要把数据放在SQL里面,你也需要对文本数据做全索引以便查询。
很难阅读。消息就像意大利面似的杂乱难以阅读
你通常没有任何用户的上下文等信息
你可能缺少一些有用的细节(你的意思是说“log.Info(‘In the method’)没用???)
你需要管理日志文件循环和保留
另外,你有你应用生成的大量数据,却不能有效的工作起来
在Stackify,我们构建了一个日志文化“culture of logging” ,来达到如下目标
1. 输出所有的事情。尽可能多的记录你所能记录的,总是有相关的上下文日志,这些日志并不会增加开销。
2. 要智能工作,不要死工作。在固定位置整合所有的日志(约定,比如d:/someapplogs/),这个位置对所有的开发人员都是透明的,并可以访问的。从日志里面发现异常有助于提升我们的产品。
本文我们将分享这些最佳实践,并分享我们是如何达到以上目标,其中大部分已经在Stackify’s 日志管理系统中实现了。如果你使用了 前缀式查看系统(Prefix to view your logs,),一定要去看看。
我给这个开发人员点赞,至少使用了try/catch来处理异常。异常里面会包含堆栈信息让我大概知道从那里来的这个异常,但没有记录更多的上下文信息。
有时,他们也做了一些前置的日志
但是,通常这样的语句并不能告诉你应用里面到底发生了什么。如果你负责生产应用的问题解决,那么这样的日志并不能给你什么指示,尤其还是像大海捞针似的找到这些日志。
就像之前提及的一样。当生产出现问题的时候,你不能查看物力服务器上的内容,日志是解决问题最常用的几个手段之一。你想要有大量的关联信息及上下文信息。下面我给出指导性原则。
按照下面工厂模式创建Foo对象,注意,我留了一个可能产生错误的地方,方法里面调用 value.doubleValue(),但没有检查null.
这是简单有用的场景。假设这是我应用的一个关键场景(不允许有任何失败),让我们尝试加一些日志信息。
现在我们创建两个foo对象,一个有效,一个无效。
日志看起来是这样的
现在我们知道了一些信息,当FooFactory.createFoo() 方法时候出错了,但没有上下文。默认的debug信息打印对象toString不可读,可以修改toString
修改后运行
好多了!现在我们可以看到[id=, value=]。另一个可选项是你可以通过java反射来获取对应的属性。最主要的好处就是当你增加修改成员的时候,你不要修改toString 方法了。下面是使用了Google’s Gson 库的输出
当你在Stackify’s回溯工具中用JSON来输出对象后,可以看到JSON格式化的对象。
图略,差不多就是移动到输出位置,可以更方便查看对象内容
最简单的增加上下文选项通常在servlet filter中。下面这个例子创建了一个servlet filter生成事务id并关联到MDC
现在我们可以看到如下类似日志
更多的上下文。现在,我们可以从单个请求中跟踪所有日志语句。
这就引出了下一个话题,那就是什么是硬工作,而不是更聪明(Work Harder, Not Smarter)。但在此之前,我将回答一个我肯定会在评论中听到的问题:“但是如果我记录了所有东西,那就产生更多的开销和巨大的日志文件了吗?我的回答有几个部分,首先使用日志冗余。你可以使用LOGGER.debug()输出任何你需要的信息,而在生产上你可以输出警告级别之上的信息。当你使用debug时,只需要修改属性文件而不需要重新部署代码。其次,日志输出应该异步非阻塞的,开销非常低,如果你担心日志文件空间,下节会介绍几个更聪明的方法去处理。
Work Smarter, Not Harder
既然我们已经记录了所有内容,它提供了更多的上下文数据,我们将会讨论下一部分内容。正如我所提到并演示了的,将所有这些输出到平面文件中仍然不能在很大的复杂的应用程序和环境中帮助您很多。在数千个请求中,跨越数天、数周或更长时间、跨多个服务器的文件,您必须考虑如何快速找到所需的数据。
我们真的需要提供一个解决方案:
- 在一个地方聚合所有的Log & Exception
- 这些日志对团队中所有成员可见、实时
- 在整个堆栈/基础结构中提供日志记录的时间线
- 是以结构化的格式并高度索引的存储,利于搜索
这是我告诉你们的关于stackfy Retrace的部分。当我们试图提高自己的能力以快速有效地处理我们的日志数据时,我们决定将它作为我们产品的核心部分(是的,我们使用Stackify来监视Stackify)并与我们的客户共享,因为我们认为这是应用程序故障排除的核心问题。
首先,我们认识到许多开发人员已经登录了,并且不打算花大量的时间来将代码取出并放入新的代码。这就是为什么我们为最常见的Java日志框架创建了日志应用程序。
log4j 1.2 (https://github.com/stackify/stackify-log-log4j12)
log4j 2.x (https://github.com/stackify/stackify-log-log4j2)
logback (https://github.com/stackify/stackify-log-logback)
继续使用log4j作为样例,设置非常简单,在pom文件中加入
当然,在 logging.properties 文件中需要加入
正如您所看到的,如果您已经使用了不同的appender,您可以将它放在适当的位置,并将它们放在一起。现在您已经将日志流到stackfy,我们可以查看一下日志记录板。(顺便说一下,如果我们的监控代理安装了,你也可以把Syslog项发送到stackfy !)
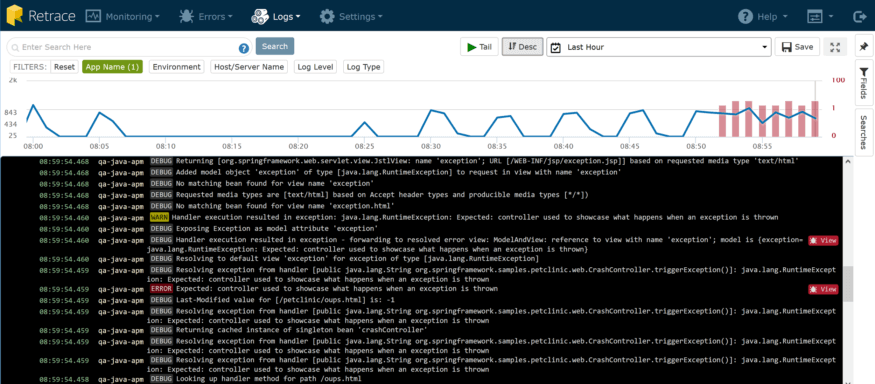
这个指示板显示了一个整合的日志数据流,来自您的所有服务器和应用程序,呈现在时间轴上。从这里,你可以快速的
- 查看基于时间范围的日志
- 对特定的服务器、应用程序或环境进行筛选
另外还有一些非常好的可用性。你会注意到的第一件事就是顶部的图表。这是快速“分流”你的应用程序的好方法。蓝色的线表示日志消息的速率,红色条表示记录的异常。
明显,几分钟前,我的web应用程序开始有了更稳定的活动,但更重要的是,在同一时间我们开始发现很多异常。异常不会开销CPU和内存,但会对用户的满意度产生直接影响,这就是钱啊。
过放大到这个时间段的图表,我可以快速地将我的日志细节过滤到那个时间范围,并查看那段时间的日志。
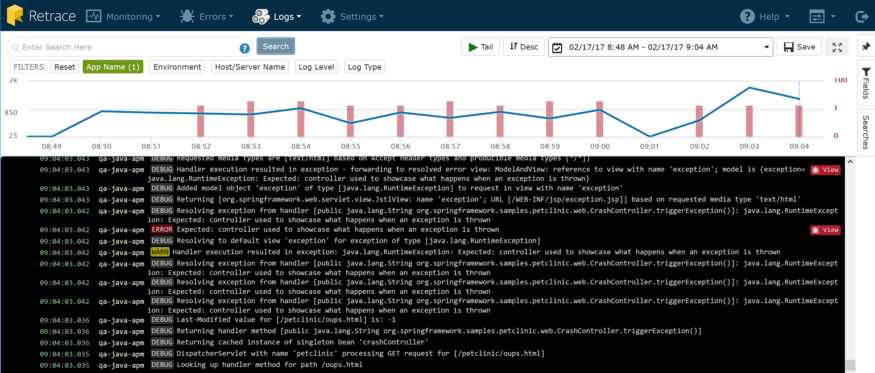
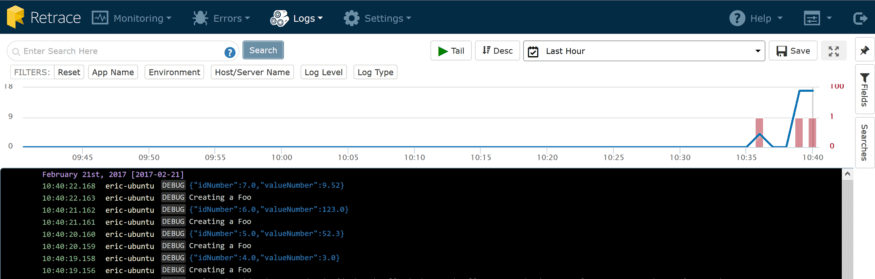
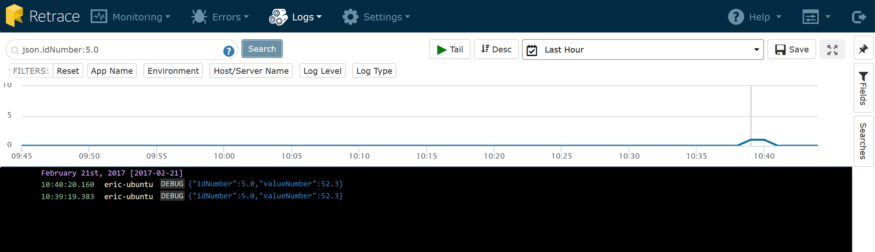
它是一个JSON对象。这是日志对象的结果,并在前面添加了上下文属性。它看起来比平面文件中的纯文本要好得多,不是吗?它变得更棒了。看到页面顶部的搜索框了吗?我可以输入任何我能想到的搜索字符串,它会查询我所有的日志,就像它是一个平面文件一样。但是,正如我们前面讨论的那样,这并不好,因为您最终可能会得到比您想要的更多的匹配。假设我要搜索所有带id为5的对象。幸运的是,我们的日志聚合器非常聪明,可以在这个位置上提供帮助
搜索结果如下
想知道你还能搜索什么?当鼠标悬停在日志记录上时,只需单击文档图标,就可以看到Stackify索引的所有字段。能够从日志中获得更多的价值,并在所有字段中搜索,称为结构化日志。

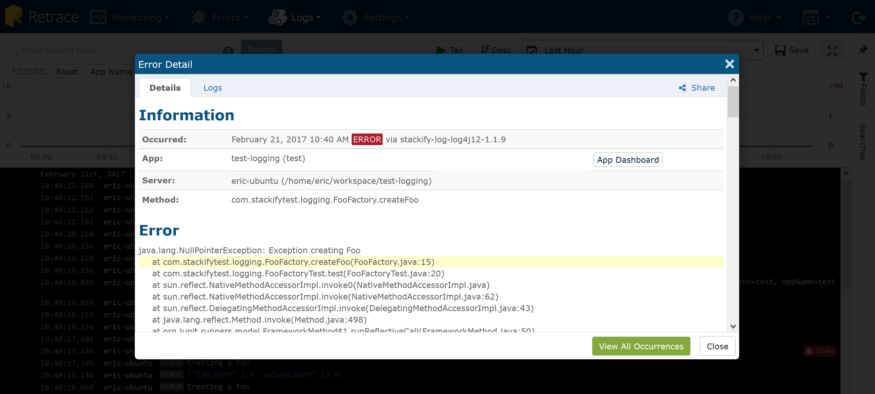
我们的库不仅可以获取完整的堆栈跟踪,还可以获取所有的web请求细节,包括header、查询字符串和服务器变量。在这个模式中,有一个“Logs”选项卡,它提供了一个预先过滤的从应用程序中记录日志的视图,在它发生的服务器上,在异常之前和之后的一个很窄的时间窗口中,为异常提供更多的上下文。想知道这个错误是多么常见或频繁,或者想查看其他事件的详细信息?点击“查看所有事件”按钮,瞧!
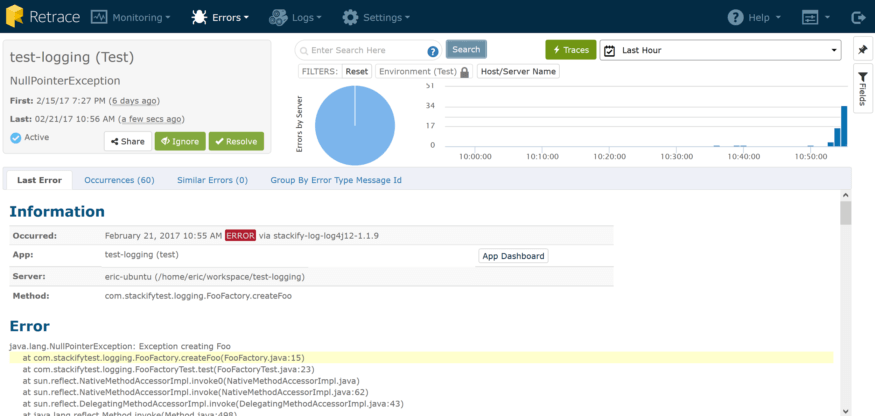
我可以很快看到这个错误在最后一个小时发生了60次。错误和日志是紧密相关的,在一个应用程序中可以发生大量的日志记录,异常有时会在噪声中丢失。这就是为什么我们也构建了一个错误指示板,给您同样的统一视图,但仅限于异常。
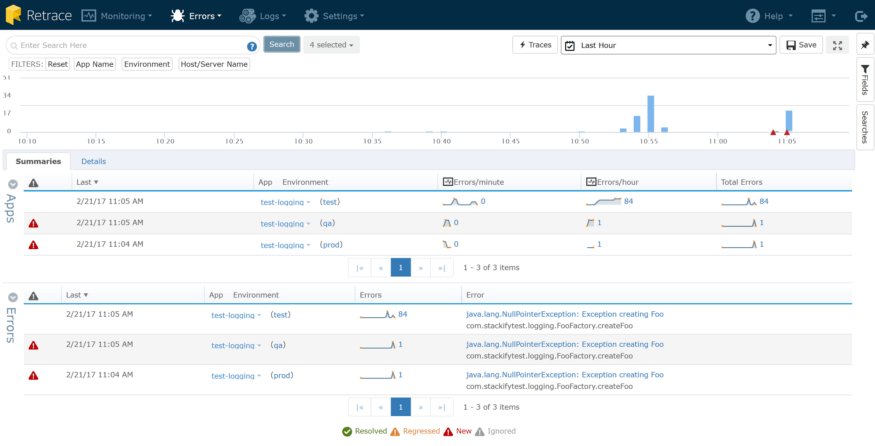
在这里,我可以看到一些很棒的数据
- 在过去的几分钟里,我的异常率有所上升。
- 我的大部分错误都来自于我的“测试”环境——大约每小时84次。
- 我有几个新的错误刚刚开始出现(如红色三角形所示)。
你是否曾经将你的应用程序发布到生产中,并想知道QA漏掉了什么?(不,我说的QA会错过一个错误……)错误指示板来救援。你可以实时看到一个趋势——大量的红色三角形,很多新的错误。图上的大峰值?也许你的使用增加了,所以以前已知的错误被更多地击中;可能有一些错误的代码(比如一个泄漏的SQL连接池),导致了比正常情况下更高的SQL超时错误率。
不难想象有很多不同的场景可以提供早期预警和检测。嗯。早期预警和检测。这引出了另一个伟大的话题。
- 特定应用程序或环境的错误率突然增加?
- 一个特别解决的错误再次发生?
- 你记录的某个动作不够频繁,等等?
Stackify 可以做上面所有的事情,下面逐个看下
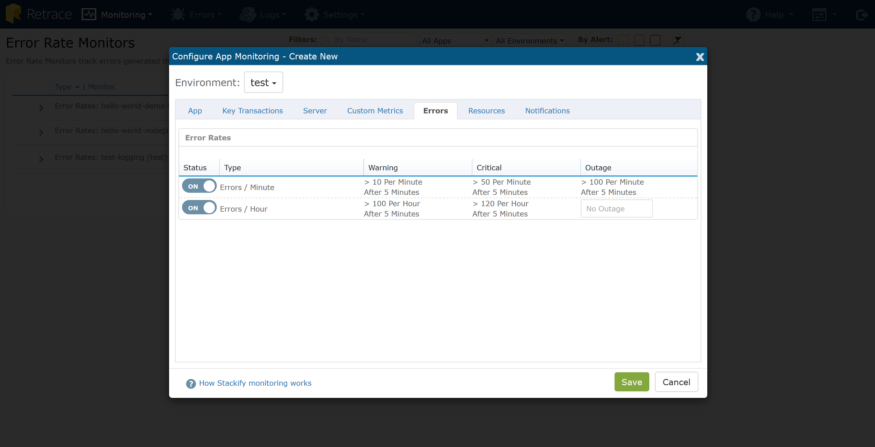
我可以为“错误/分钟”和“完全错误”配置监视器,然后选择“通知”选项卡来指定应该通知谁,以及如何通知。随后,如果使用Stackify监控,我还可以在这里配置其他警报:应用程序运行状态、内存使用、性能计数器、自定义度量、ping检查等等。
这是一个愚蠢的错误,但却是一个容易犯的错误。我将把这个标记为“解析”,让我做一些非常酷的事情:如果它回来了,请保持警惕。通知菜单将允许我检查我的配置,默认情况下,我将为所有的应用程序和环境同时接收新的和倒退的错误通知。

现在,如果同样的错误在将来再次发生,我将会收到关于回归的电子邮件它会显示在仪表盘上。当你“认为”你已经解决了这个问题并且想要确定的时候,这是一个很好的自动帮助。
这是检查系统健康的一个很简单的方法,如果一个日志文件是唯一的指示。
正如您所看到的,您在一瞥中得到了一些很好的上下文数据,这些错误和日志有助于:满意度和HTTP错误率。您可以看到,用户满意度很高,而且HTTP错误率也很低。您可以快速开始向下挖掘,以查看哪些页面可能表现不好,以及出现了哪些错误:
在这篇文章中有很多内容要讲,我觉得我只是触及了表面。如果你再挖深一点,甚至把手放在上面,你就可以!我希望这些Java日志记录最佳实践能够帮助您编写更好的日志,并节省时间故障排除。
我们所有的Java日志应用程序都可以在GitHub上使用,您可以注册一个免费试用,以开始今天的Stackify !
原文在: https://stackify.com/java-logging-best-practices/ 。是官方的内容,至于ELKB,也是类似的东西
注意:需要关注的是这里面的思想,以及架构、核心编码、编码人员应该注意什么?
后段关于软件的使用没仔细校对,直接走的翻译软件。注意思想和目标
Java小应用日志及异常处理最佳实践
日志我们应该做的更好了
是时候严肃对待日志了
开始记录所有的事情
Walk the Code
输出更多的诊断上下文详细信息
查找你的日志
发现Java 异常详情
监控
错误率
解决的错误和新的错误
日志监控
Java 日志最佳实践
Java小应用日志及异常处理最佳实践
日志:我们应该做的更好了
我在说什?现在有大量的Java日志框架和库,大多数开发人员每天都在使用。两个最常用的是log4j和logback。他们使用起来非常简单,并且表现很不错。基本的java 日志文件还不够,这里我们会给出一些Java最佳实践或者建议来帮助你去使用!你曾经脱离开发部门去查看过日志文件吗?如果你做过这些事情,你很快会意识到一些问题。
有大量的数据
你需要访问数据
分布在多个服务器
一个具体的操作可能是跨应用的,因此你需要查看多个日志
日志都是流水性的,很难查询。就算你要把数据放在SQL里面,你也需要对文本数据做全索引以便查询。
很难阅读。消息就像意大利面似的杂乱难以阅读
你通常没有任何用户的上下文等信息
你可能缺少一些有用的细节(你的意思是说“log.Info(‘In the method’)没用???)
你需要管理日志文件循环和保留
另外,你有你应用生成的大量数据,却不能有效的工作起来
是时候严肃对待日志了
一旦你的应用不是运行在你的桌面系统,那么当你的应用不能正确运行的时候,日志(包括错误信息)就是你的救命稻草。当然,AMP(性能管理平台)工具会对内存溢出、性能阀值出现问题的时候发出警告信息,但这些信息确并不能帮你解决问题,例如为什么这个用户不能登录,或者为什么这条记录没有处理在Stackify,我们构建了一个日志文化“culture of logging” ,来达到如下目标
1. 输出所有的事情。尽可能多的记录你所能记录的,总是有相关的上下文日志,这些日志并不会增加开销。
2. 要智能工作,不要死工作。在固定位置整合所有的日志(约定,比如d:/someapplogs/),这个位置对所有的开发人员都是透明的,并可以访问的。从日志里面发现异常有助于提升我们的产品。
本文我们将分享这些最佳实践,并分享我们是如何达到以上目标,其中大部分已经在Stackify’s 日志管理系统中实现了。如果你使用了 前缀式查看系统(Prefix to view your logs,),一定要去看看。
开始记录所有的事情
我在很多商店工作过,那里的信息是这样的} catcha(Exception e){
LOGGER.error(e.getMessage(),e);
}我给这个开发人员点赞,至少使用了try/catch来处理异常。异常里面会包含堆栈信息让我大概知道从那里来的这个异常,但没有记录更多的上下文信息。
有时,他们也做了一些前置的日志
public void processResultes(final List<Double> results){
LOGGER.debug("Processing resultes");
}但是,通常这样的语句并不能告诉你应用里面到底发生了什么。如果你负责生产应用的问题解决,那么这样的日志并不能给你什么指示,尤其还是像大海捞针似的找到这些日志。
就像之前提及的一样。当生产出现问题的时候,你不能查看物力服务器上的内容,日志是解决问题最常用的几个手段之一。你想要有大量的关联信息及上下文信息。下面我给出指导性原则。
Walk the Code
让我们假设你有个想要处理的try/catch的地方,但是之前并没有告诉你关于请求的更多信息,样例代码是这样的public class Foo {
private int id;
private double value;
public Foo(int id, double value) {
this.id = id;
this.value = value;
}
public int getId() {
return id;
}
public double getValue() {
return value;
}
}按照下面工厂模式创建Foo对象,注意,我留了一个可能产生错误的地方,方法里面调用 value.doubleValue(),但没有检查null.
public class FooFactory {
public static Foo createFoo(int id, Double value) {
return new Foo(id, value.doubleValue());
}
}这是简单有用的场景。假设这是我应用的一个关键场景(不允许有任何失败),让我们尝试加一些日志信息。
public class FooFactory {
private static Logger LOGGER = LoggerFactory.getLogger(FooFactory.class);
public static Foo createFoo(int id, Double value) {
LOGGER.debug("Creating a Foo");
try {
Foo foo = new Foo(id, value.doubleValue());
LOGGER.debug("{}", foo);
return foo;
} catch (Exception e) {
LOGGER.error(e.getMessage(), e);
}
return null;
}
}现在我们创建两个foo对象,一个有效,一个无效。
FooFactory.createFoo(1, Double.valueOf(33.0)); FooFactory.createFoo(2, null);
日志看起来是这样的
2017-02-15 17:01:04,842 [main] DEBUG com.stackifytest.logging.FooFactory: Creating a Foo 2017-02-15 17:01:04,848 [main] DEBUG com.stackifytest.logging.FooFactory: com.stackifytest.logging.Foo@5d22bbb7 2017-02-15 17:01:04,849 [main] DEBUG com.stackifytest.logging.FooFactory: Creating a Foo 2017-02-15 17:01:04,851 [main] ERROR com.stackifytest.logging.FooFactory: java.lang.NullPointerException at com.stackifytest.logging.FooFactory.createFoo(FooFactory.java:15) at com.stackifytest.logging.FooFactoryTest.test(FooFactoryTest.java:11)
现在我们知道了一些信息,当FooFactory.createFoo() 方法时候出错了,但没有上下文。默认的debug信息打印对象toString不可读,可以修改toString
@Override
public String toString() {
return "Foo [id=" + id + ", value=" + value + "]";
}修改后运行
2017-02-15 17:13:06,032 [main] DEBUG com.stackifytest.logging.FooFactory: Creating a Foo 2017-02-15 17:13:06,041 [main] DEBUG com.stackifytest.logging.FooFactory: Foo [id=1, value=33.0] 2017-02-15 17:13:06,041 [main] DEBUG com.stackifytest.logging.FooFactory: Creating a Foo 2017-02-15 17:13:06,043 [main] ERROR com.stackifytest.logging.FooFactory: java.lang.NullPointerException at com.stackifytest.logging.FooFactory.createFoo(FooFactory.java:15) at com.stackifytest.logging.FooFactoryTest.test(FooFactoryTest.java:11)
好多了!现在我们可以看到[id=, value=]。另一个可选项是你可以通过java反射来获取对应的属性。最主要的好处就是当你增加修改成员的时候,你不要修改toString 方法了。下面是使用了Google’s Gson 库的输出
2017-02-15 17:22:55,584 [main] DEBUG com.stackifytest.logging.FooFactory: Creating a Foo
2017-02-15 17:22:55,751 [main] DEBUG com.stackifytest.logging.FooFactory: {"id":1,"value":33.0}
2017-02-15 17:22:55,754 [main] DEBUG com.stackifytest.logging.FooFactory: Creating a Foo
2017-02-15 17:22:55,760 [main] ERROR com.stackifytest.logging.FooFactory:
java.lang.NullPointerException
at com.stackifytest.logging.FooFactory.createFoo(FooFactory.java:15)
at com.stackifytest.logging.FooFactoryTest.test(FooFactoryTest.java:11)当你在Stackify’s回溯工具中用JSON来输出对象后,可以看到JSON格式化的对象。
图略,差不多就是移动到输出位置,可以更方便查看对象内容
{
variable : value,
variable : value
}输出更多的诊断上下文详细信息
这就给我们带来了关于记录更多细节的最后一点:诊断上下文日志。在调试生产问题时,您可能在日志中有上千次“创建一个Foo”消息,但是不知道是谁创建的。知道用户是谁是一种非常珍贵的上下文,能够快速解决问题。考虑其他的细节可能是有用的——例如,HttpWebRequest细节。但是谁想要记住每次都记录下来呢?如何映射诊断上下文信息可以参考SLF4J’s MDC https://logback.qos.ch/manual/mdc.html。最简单的增加上下文选项通常在servlet filter中。下面这个例子创建了一个servlet filter生成事务id并关联到MDC
public class LogContextFilter implements Filter {
public void init(FilterConfig config) {
}
public void destroy() {
}
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws ServletException, IOException {
String transactionId = UUID.randomUUID().toString();
MDC.put("TRANS_ID", transactionId);现在我们可以看到如下类似日志
19:49:36.350 eric-ubuntu DEBUG Create a Foo {"TRANS_ID":"d91lxxxxx2ffjjlslf03jf9j;a;j8g3g"}
19:49:36.406 eric-ubuntu DEBUG {"id":1,"value":33.0}{"TRANS_ID":"d91lxxxxx2ffjjlslf03jf9j;a;j8g3g"}更多的上下文。现在,我们可以从单个请求中跟踪所有日志语句。
这就引出了下一个话题,那就是什么是硬工作,而不是更聪明(Work Harder, Not Smarter)。但在此之前,我将回答一个我肯定会在评论中听到的问题:“但是如果我记录了所有东西,那就产生更多的开销和巨大的日志文件了吗?我的回答有几个部分,首先使用日志冗余。你可以使用LOGGER.debug()输出任何你需要的信息,而在生产上你可以输出警告级别之上的信息。当你使用debug时,只需要修改属性文件而不需要重新部署代码。其次,日志输出应该异步非阻塞的,开销非常低,如果你担心日志文件空间,下节会介绍几个更聪明的方法去处理。
Work Smarter, Not Harder
既然我们已经记录了所有内容,它提供了更多的上下文数据,我们将会讨论下一部分内容。正如我所提到并演示了的,将所有这些输出到平面文件中仍然不能在很大的复杂的应用程序和环境中帮助您很多。在数千个请求中,跨越数天、数周或更长时间、跨多个服务器的文件,您必须考虑如何快速找到所需的数据。
我们真的需要提供一个解决方案:
- 在一个地方聚合所有的Log & Exception
- 这些日志对团队中所有成员可见、实时
- 在整个堆栈/基础结构中提供日志记录的时间线
- 是以结构化的格式并高度索引的存储,利于搜索
这是我告诉你们的关于stackfy Retrace的部分。当我们试图提高自己的能力以快速有效地处理我们的日志数据时,我们决定将它作为我们产品的核心部分(是的,我们使用Stackify来监视Stackify)并与我们的客户共享,因为我们认为这是应用程序故障排除的核心问题。
首先,我们认识到许多开发人员已经登录了,并且不打算花大量的时间来将代码取出并放入新的代码。这就是为什么我们为最常见的Java日志框架创建了日志应用程序。
log4j 1.2 (https://github.com/stackify/stackify-log-log4j12)
log4j 2.x (https://github.com/stackify/stackify-log-log4j2)
logback (https://github.com/stackify/stackify-log-logback)
继续使用log4j作为样例,设置非常简单,在pom文件中加入
<dependency> <groupId>com.stackify</groupId> <artifactId>stackify-log-log4j12</artifactId> <version>1.1.9</version> <scope>runtime</scope> </dependency>
当然,在 logging.properties 文件中需要加入
log4j.rootLogger=DEBUG, CONSOLE, STACKIFY log4j.appender.CONSOLE=org.apache.log4j.ConsoleAppender log4j.appender.CONSOLE.layout=org.apache.log4j.PatternLayout log4j.appender.CONSOLE.layout.ConversionPattern=%d [%t] %-5p %c: %m%n log4j.appender.STACKIFY=com.stackify.log.log4j12.StackifyLogAppender log4j.appender.STACKIFY.apiKey=[HIDDEN] log4j.appender.STACKIFY.application=test-logging log4j.appender.STACKIFY.environment=test
正如您所看到的,如果您已经使用了不同的appender,您可以将它放在适当的位置,并将它们放在一起。现在您已经将日志流到stackfy,我们可以查看一下日志记录板。(顺便说一下,如果我们的监控代理安装了,你也可以把Syslog项发送到stackfy !)
这个指示板显示了一个整合的日志数据流,来自您的所有服务器和应用程序,呈现在时间轴上。从这里,你可以快速的
- 查看基于时间范围的日志
- 对特定的服务器、应用程序或环境进行筛选
另外还有一些非常好的可用性。你会注意到的第一件事就是顶部的图表。这是快速“分流”你的应用程序的好方法。蓝色的线表示日志消息的速率,红色条表示记录的异常。
明显,几分钟前,我的web应用程序开始有了更稳定的活动,但更重要的是,在同一时间我们开始发现很多异常。异常不会开销CPU和内存,但会对用户的满意度产生直接影响,这就是钱啊。
过放大到这个时间段的图表,我可以快速地将我的日志细节过滤到那个时间范围,并查看那段时间的日志。
查找你的日志
您是否看到下面的蓝色文本看起来像一个JSON对象?它是一个JSON对象。这是日志对象的结果,并在前面添加了上下文属性。它看起来比平面文件中的纯文本要好得多,不是吗?它变得更棒了。看到页面顶部的搜索框了吗?我可以输入任何我能想到的搜索字符串,它会查询我所有的日志,就像它是一个平面文件一样。但是,正如我们前面讨论的那样,这并不好,因为您最终可能会得到比您想要的更多的匹配。假设我要搜索所有带id为5的对象。幸运的是,我们的日志聚合器非常聪明,可以在这个位置上提供帮助
json.idNumber:5.0
搜索结果如下
想知道你还能搜索什么?当鼠标悬停在日志记录上时,只需单击文档图标,就可以看到Stackify索引的所有字段。能够从日志中获得更多的价值,并在所有字段中搜索,称为结构化日志。
发现Java 异常详情
您可能也注意到了这个红色的bug图标(bug)。这是因为我们通过自动显示更多的上下文来区别对待异常。点击它,我们会给出一个更深刻的观点。我们的库不仅可以获取完整的堆栈跟踪,还可以获取所有的web请求细节,包括header、查询字符串和服务器变量。在这个模式中,有一个“Logs”选项卡,它提供了一个预先过滤的从应用程序中记录日志的视图,在它发生的服务器上,在异常之前和之后的一个很窄的时间窗口中,为异常提供更多的上下文。想知道这个错误是多么常见或频繁,或者想查看其他事件的详细信息?点击“查看所有事件”按钮,瞧!
我可以很快看到这个错误在最后一个小时发生了60次。错误和日志是紧密相关的,在一个应用程序中可以发生大量的日志记录,异常有时会在噪声中丢失。这就是为什么我们也构建了一个错误指示板,给您同样的统一视图,但仅限于异常。
在这里,我可以看到一些很棒的数据
- 在过去的几分钟里,我的异常率有所上升。
- 我的大部分错误都来自于我的“测试”环境——大约每小时84次。
- 我有几个新的错误刚刚开始出现(如红色三角形所示)。
你是否曾经将你的应用程序发布到生产中,并想知道QA漏掉了什么?(不,我说的QA会错过一个错误……)错误指示板来救援。你可以实时看到一个趋势——大量的红色三角形,很多新的错误。图上的大峰值?也许你的使用增加了,所以以前已知的错误被更多地击中;可能有一些错误的代码(比如一个泄漏的SQL连接池),导致了比正常情况下更高的SQL超时错误率。
不难想象有很多不同的场景可以提供早期预警和检测。嗯。早期预警和检测。这引出了另一个伟大的话题。
监控
如果能在某些时候得到提醒不是很好吗- 特定应用程序或环境的错误率突然增加?
- 一个特别解决的错误再次发生?
- 你记录的某个动作不够频繁,等等?
Stackify 可以做上面所有的事情,下面逐个看下
错误率
当我们查看错误指示板时,我注意到我的“测试”环境每小时有大量的错误。从错误指示板中,单击“出错率”,然后选择您希望为其配置警报的应用程序/环境我可以为“错误/分钟”和“完全错误”配置监视器,然后选择“通知”选项卡来指定应该通知谁,以及如何通知。随后,如果使用Stackify监控,我还可以在这里配置其他警报:应用程序运行状态、内存使用、性能计数器、自定义度量、ping检查等等。
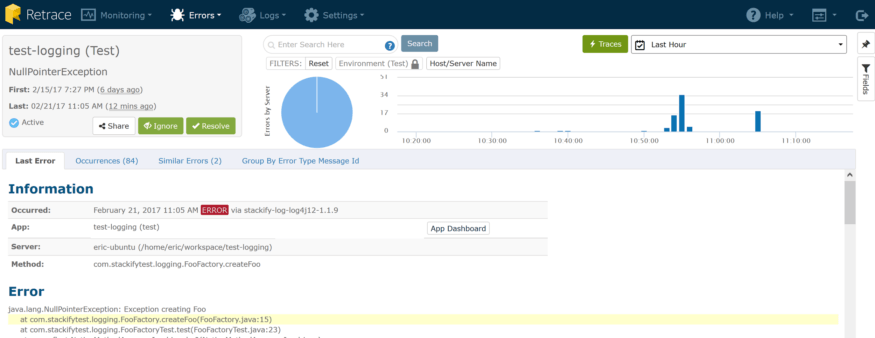
解决的错误和新的错误
早些时候,我在创建Foo对象时不检查null值,从而引入了一个新的错误。我已经修正了这个错误,并通过观察那个特定错误的细节来确认它。你们可以看到,上次发生在12分钟前:这是一个愚蠢的错误,但却是一个容易犯的错误。我将把这个标记为“解析”,让我做一些非常酷的事情:如果它回来了,请保持警惕。通知菜单将允许我检查我的配置,默认情况下,我将为所有的应用程序和环境同时接收新的和倒退的错误通知。
现在,如果同样的错误在将来再次发生,我将会收到关于回归的电子邮件它会显示在仪表盘上。当你“认为”你已经解决了这个问题并且想要确定的时候,这是一个很好的自动帮助。
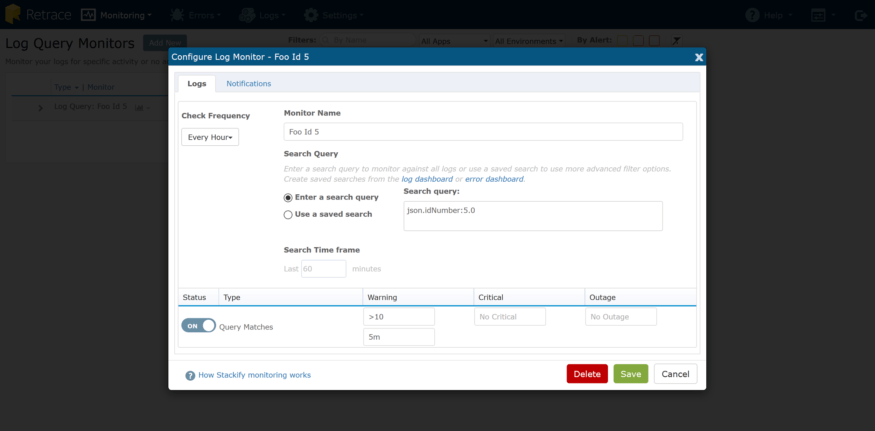
日志监控
有些东西不太容易监测。也许您有一个异步运行的关键流程,它成功(或失败)的惟一记录是日志记录。在这篇文章的前面,我展示了针对您的结构化日志数据进行深度查询的能力,任何查询都可以被保存和监视。这里有一个非常简单的场景:我的查询每分钟执行一次,我们可以监视我们有多少匹配的记录。这是检查系统健康的一个很简单的方法,如果一个日志文件是唯一的指示。
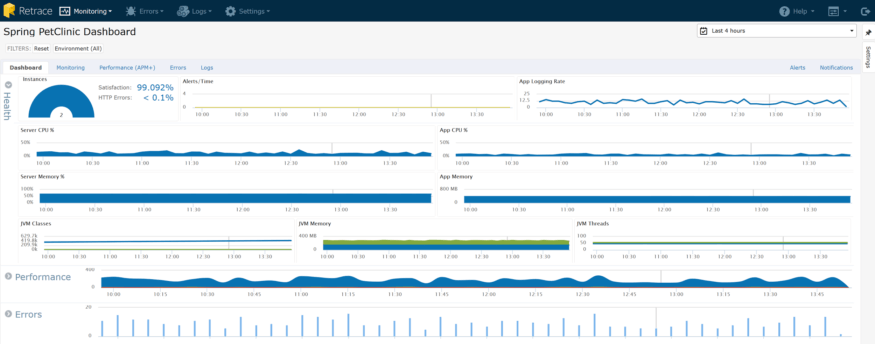
Java 日志最佳实践
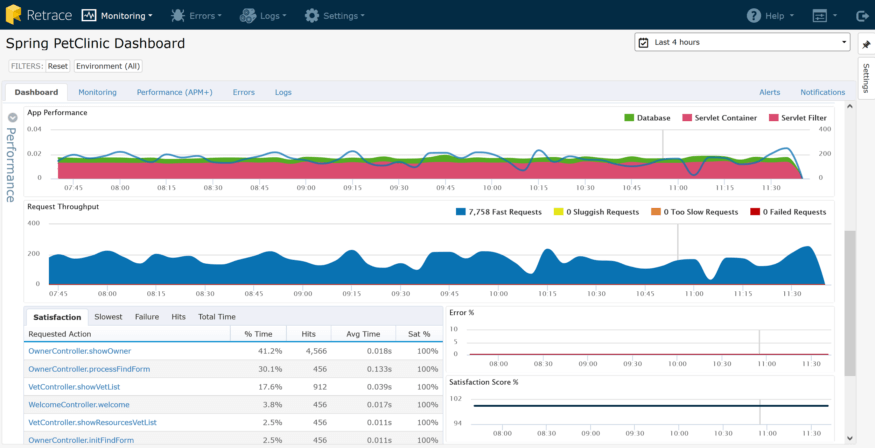
所有这些错误和日志数据都是无价之宝,特别是当你退一步看一幅更大的图片时。下面是一个Java web应用程序的应用程序指示板,它包含所有的监视:正如您所看到的,您在一瞥中得到了一些很好的上下文数据,这些错误和日志有助于:满意度和HTTP错误率。您可以看到,用户满意度很高,而且HTTP错误率也很低。您可以快速开始向下挖掘,以查看哪些页面可能表现不好,以及出现了哪些错误:
在这篇文章中有很多内容要讲,我觉得我只是触及了表面。如果你再挖深一点,甚至把手放在上面,你就可以!我希望这些Java日志记录最佳实践能够帮助您编写更好的日志,并节省时间故障排除。
我们所有的Java日志应用程序都可以在GitHub上使用,您可以注册一个免费试用,以开始今天的Stackify !

相关文章推荐
- 避免Java应用中空指针异常的技巧和最佳实践
- Java 编程中关于异常处理的 10 个最佳实践
- Java 编程中关于异常处理的 10 个最佳实践
- Java异常处理的10个最佳实践
- Java 编程中关于异常处理的 10 个最佳实践
- Java 编程中异常处理的最佳实践
- Java 编程中异常处理的最佳实践
- 《转载》Java异常处理的10个最佳实践
- Atitit.异常的设计原理与 策略处理 java 最佳实践 p93
- Java异常处理的最佳实践
- Java异常处理的10个最佳实践
- Java 编程中关于异常处理的 10 个最佳实践
- Java 编程中关于异常处理的 10 个最佳实践
- [转载]11条Java异常处理的最佳实践
- Java 编程中关于异常处理的 10 个最佳实践
- Java中关于异常处理的十个最佳实践
- Java中处理异常的9个最佳实践
- Java中关于异常处理的10个最佳实践
- Java异常处理机制与最佳实践
- Java 编程中关于异常处理的 10 个最佳实践