天池大赛o2o优惠券第一名代码笔记之_extral_feature(1)
2017-12-19 16:47
771 查看
# -*- coding: utf-8 -*-
import pandas as pd
import numpy as np
from datetime import date
import warnings
warnings.filterwarnings("ignore")
"""
dataset split:
(date_received)
dateset3: 20160701~20160731 (113640),features3 from 20160315~20160630 (off_test)
dateset2: 20160515~20160615 (258446),features2 from 20160201~20160514
dateset1: 20160414~20160514 (138303),features1 from 20160101~20160413
1.merchant related:
sales_use_coupon. total_coupon
transfer_rate = sales_use_coupon/total_coupon.
merchant_avg_distance,merchant_min_distance,merchant_max_distance of those use coupon
total_sales. coupon_rate = sales_use_coupon/total_sales.
2.coupon related:
discount_rate. discount_man. discount_jian. is_man_jian
day_of_week,day_of_month. (date_received)
3.user related:
distance.
user_avg_distance, user_min_distance,user_max_distance.
buy_use_coupon. buy_total. coupon_received.
buy_use_coupon/coupon_received.
avg_diff_date_datereceived. min_diff_date_datereceived. max_diff_date_datereceived.
count_merchant.
4.user_merchant:
times_user_buy_merchant_before.
5. other feature:
this_month_user_receive_all_coupon_count
this_month_user_receive_same_coupon_count
this_month_user_receive_same_coupon_lastone
this_month_user_receive_same_coupon_firstone
this_day_user_receive_all_coupon_count
this_day_user_receive_same_coupon_count
day_gap_before, day_gap_after (receive the same coupon)
"""
#,header=0,表明第0行代表列名
#off_train = pd.read_csv('data/ccf_offline_stage1_train.csv',header=0)#如果都这样写下面省不少事
#1754884 record,1053282 with coupon_id,9738 coupon. date_received:20160101~20160615,date:20160101~20160630, 539438 users, 8415 merchants
off_train = pd.read_csv('data/ccf_offline_stage1_train.csv',header=None)
off_train.columns = ['user_id','merchant_id','coupon_id','discount_rate','distance','date_received','date']
#2050 coupon_id. date_received:20160701~20160731, 76309 users(76307 in trainset, 35965 in online_trainset), 1559 merchants(1558 in trainset)
off_test = pd.read_csv('data/ccf_offline_stage1_test_revised.csv',header=None)
off_test.columns = ['user_id','merchant_id','coupon_id','discount_rate','distance','date_received']
#11429826 record(872357 with coupon_id),762858 user(267448 in off_train)
on_train = pd.read_csv('data/ccf_online_stage1_train.csv',header=None)
on_train.columns = ['user_id','merchant_id','action','coupon_id','discount_rate','date_received','date']
dataset3 = off_test
feature3 = off_train[((off_train.date>='20160315')&(off_train.date<='20160630'))|((off_train.date=='null')&(off_train.date_received>='20160315')&(off_train.date_received<='20160630'))]
dataset2 = off_train[(off_train.date_received>='20160515')&(off_train.date_received<='20160615')]
feature2 = off_train[(off_train.date>='20160201')&(off_train.date<='20160514')|((off_train.date=='null')&(off_train.date_received>='20160201')&(off_train.date_received<='20160514'))]
dataset1 = off_train[(off_train.date_received>='20160414')&(off_train.date_received<='20160514')]
feature1 = off_train[(off_train.date>='20160101')&(off_train.date<='20160413')|((off_train.date=='null')&(off_train.date_received>='20160101')&(off_train.date_received<='20160413'))]
############# other feature ##################3
"""
5. other feature:
this_month_user_receive_all_coupon_count
this_month_user_receive_same_coupon_count
this_month_user_receive_same_coupon_lastone
this_month_user_receive_same_coupon_firstone
this_day_user_receive_all_coupon_count
this_day_user_receive_same_coupon_count
day_gap_before, day_gap_after (receive the same coupon)
"""
#for dataset3
t = dataset3[['user_id']]
t['this_month_user_receive_all_coupon_count'] = 1
#将t按照用户id进行分组,然后统计所有用户收取的优惠券数目,并初始化一个索引值
t = t.groupby('user_id').agg('sum').reset_index()
t1 = dataset3[['user_id','coupon_id']]
#提取这个月用户收到的相同的优惠券的数量
t1['this_month_user_receive_same_coupon_count'] = 1
t1 = t1.groupby(['user_id','coupon_id']).agg('sum').reset_index()
t2 = dataset3[['user_id','coupon_id','date_received']]
#将数据转换为str类型
t2.date_received = t2.date_received.astype('str')
#如果出现相同的用户接收相同的优惠券在接收时间上用‘:’连接上第n次接受优惠券的时间 20160716:20160719
t2 = t2.groupby(['user_id','coupon_id'])['date_received'].agg(lambda x:':'.join(x)).reset_index()
#将接收时间的一组按着':'分开,这样就可以计算接受了优惠券的数量,apply是合并
t2['receive_number'] = t2.date_received.apply(lambda s:len(s.split(':')))
#保留领取优惠券大于1
t2 = t2[t
f538
2.receive_number>1]
t2['max_date_received'] = t2.date_received.apply(lambda s:max([int(d) for d in s.split(':')]))
t2['min_date_received'] = t2.date_received.apply(lambda s:min([int(d) for d in s.split(':')]))
#去除receive_number这列
#t2 = t2['user_id','coupon_id','max_date_received','min_date_received']不行
#等价#t2 = t2[['user_id','coupon_id','max_date_received','min_date_received']]
t2.drop(['receive_number','date_received'],axis=1,inplace=True)
#将两表融合只保留左表数据,这样得到的表,相当于保留了最近接收时间和最远接受时间
t3 = dataset3[['user_id','coupon_id','date_received']]
#======很高兴自己能把这段代码补上解决bug
t3=t3.drop([0])
t3 = t3[['user_id','coupon_id','date_received']]
#=========================================
t3 = pd.merge(t3,t2,on=['user_id','coupon_id'],how='left')
#这个优惠券最近接受时间这里报错了float与str#上面加二句#将数据转换为int类型
t3['this_month_user_receive_same_coupon_lastone'] = t3.max_date_received - t3.date_received.astype(int)
#这个优惠券最远接受时间
t3['this_month_user_receive_same_coupon_firstone'] = t3.date_received.astype(int) -t3.min_date_received
def is_firstlastone(x):
if x==0:
return 1
elif x>0:
return 0
else:
return -1 #those only receive once(nan-20160603)之前已经筛选maxmin的receive_number肯定是大于1
#这列应用这个函数处理
t3.this_month_user_receive_same_coupon_lastone = t3.this_month_user_receive_same_coupon_lastone.apply(is_firstlastone)
t3.this_month_user_receive_same_coupon_firstone = t3.this_month_user_receive_same_coupon_firstone.apply(is_firstlastone)
t3 = t3[['user_id','coupon_id','date_received','this_month_user_receive_same_coupon_lastone','this_month_user_receive_same_coupon_firstone']]
#将表格中接收优惠券日期中是否为最近和最远的日期时置为1其余为0,若只接受了一次优惠券为-1
#提取第四个特征,一个用户所接收到的所有优惠券的数量
t4 = dataset3[['user_id','date_received']]
t4['this_day_user_receive_all_coupon_count'] = 1
t4 = t4.groupby(['user_id','date_received']).agg('sum').reset_index()
#提取第五个特征,一个用户不同时间所接收到不同优惠券的数量
t5 = dataset3[['user_id','coupon_id','date_received']]
t5['this_day_user_receive_same_coupon_count'] = 1
t5 = t5.groupby(['user_id','coupon_id','date_received']).agg('sum').reset_index()
#一个用户优惠券 的不同接受时间
t6 = dataset3[['user_id','coupon_id','date_received']]
t6.date_received = t6.date_received.astype('str')
t6 = t6.groupby(['user_id','coupon_id'])['date_received'].agg(lambda x:':'.join(x)).reset_index()
#重命名inplace代表深拷贝&自身
t6.rename(columns={'date_received':'dates'},inplace=True)
def get_day_gap_before(s):
date_received,dates = s.split('-')
dates = dates.split(':')
gaps = []
for d in dates:
#三个部分分别代表年月日 #将时间差转化为天数
this_gap = (date(int(date_received[0:4]),int(date_received[4:6]),int(date_received[6:8]))-date(int(d[0:4]),int(d[4:6]),int(d[6:8]))).days
if this_gap>0:
gaps.append(this_gap)
if len(gaps)==0:
return -1
else:
return min(gaps)
def get_day_gap_after(s):
date_received,dates = s.split('-')
dates = dates.split(':')
gaps = []
for d in dates:
this_gap = (date(int(d[0:4]),int(d[4:6]),int(d[6:8]))-date(int(date_received[0:4]),int(date_received[4:6]),int(date_received[6:8]))).days
if this_gap>0:
gaps.append(this_gap)
if len(gaps)==0:
return -1
else:
return min(gaps)
t7 = dataset3[['user_id','coupon_id','date_received']]
t7=t7.drop([0])
t7 = t7[['user_id','coupon_id','date_received']]
t7 = pd.merge(t7,t6,on=['user_id','coupon_id'],how='left')
#接在一起为了函数处理分开
t7['date_received_date'] = t7.date_received.astype('str') + '-' + t7.dates
t7['day_gap_before'] = t7.date_received_date.apply(get_day_gap_before)
t7['day_gap_after'] = t7.date_received_date.apply(get_day_gap_after)
t7 = t7[['user_id','coupon_id','date_received','day_gap_before','day_gap_after']]
#将所有特征融合在一张表中
other_feature3 = pd.merge(t1,t,on='user_id')
other_feature3 = pd.merge(other_feature3,t3,on=['user_id','coupon_id'])
other_feature3 = pd.merge(other_feature3,t4,on=['user_id','date_received'])
other_feature3 = pd.merge(other_feature3,t5,on=['user_id','coupon_id','date_received'])
other_feature3 = pd.merge(other_feature3,t7,on=['user_id','coupon_id','date_received'])
other_feature3.to_csv('data/other_feature3.csv',index=None)
print(other_feature3.shape)已经修改bug
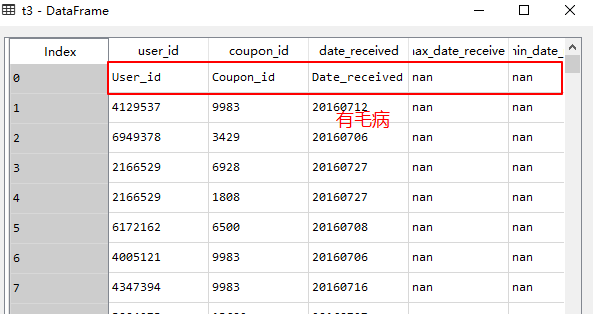
最后到wdir路径下找到other_feature3.csv

接着上面对data2和data1继续处理思想完全一样,不过不需要考虑上面的bug,因为data2和data1的第一行是正常数据
#for dataset2
t = dataset2[['user_id']]
t['this_month_user_receive_all_coupon_count'] = 1
t = t.groupby('user_id').agg('sum').reset_index()
t1 = dataset2[['user_id','coupon_id']]
t1['this_month_user_receive_same_coupon_count'] = 1
t1 = t1.groupby(['user_id','coupon_id']).agg('sum').reset_index()
t2 = dataset2[['user_id','coupon_id','date_received']]
t2.date_received = t2.date_received.astype('str')
t2 = t2.groupby(['user_id','coupon_id'])['date_received'].agg(lambda x:':'.join(x)).reset_index()
t2['receive_number'] = t2.date_received.apply(lambda s:len(s.split(':')))
t2 = t2[t2.receive_number>1]
t2['max_date_received'] = t2.date_received.apply(lambda s:max([int(d) for d in s.split(':')]))
t2['min_date_received'] = t2.date_received.apply(lambda s:min([int(d) for d in s.split(':')]))
t2 = t2[['user_id','coupon_id','max_date_received','min_date_received']]
t3 = dataset2[['user_id','coupon_id','date_received']]
# =============================================================================
#和data3处理不一样不需要下面的操作,主要data1和data2第一行就是数据不是字符串
#t3=t3.drop([0])
# t3=t3[['user_id','coupon_id','date_received']]
# =============================================================================
t3 = pd.merge(t3,t2,on=['user_id','coupon_id'],how='left')
t3['this_month_user_receive_same_coupon_lastone'] = t3.max_date_received - t3.date_received.astype('int')
t3['this_month_user_receive_same_coupon_firstone'] = t3.date_received.astype('int') - t3.min_date_received
def is_firstlastone(x):
if x==0:
return 1
elif x>0:
return 0
else:
return -1 #those only receive once
t3.this_month_user_receive_same_coupon_lastone = t3.this_month_user_receive_same_coupon_lastone.apply(is_firstlastone)
t3.this_month_user_receive_same_coupon_firstone = t3.this_month_user_receive_same_coupon_firstone.apply(is_firstlastone)
t3 = t3[['user_id','coupon_id','date_received','this_month_user_receive_same_coupon_lastone','this_month_user_receive_same_coupon_firstone']]
t4 = dataset2[['user_id','date_received']]
t4['this_day_user_receive_all_coupon_count'] = 1
t4 = t4.groupby(['user_id','date_received']).agg('sum').reset_index()
t5 = dataset2[['user_id','coupon_id','date_received']]
t5['this_day_user_receive_same_coupon_count'] = 1
t5 = t5.groupby(['user_id','coupon_id','date_received']).agg('sum').reset_index()
t6 = dataset2[['user_id','coupon_id','date_received']]
t6.date_received = t6.date_received.astype('str')
t6 = t6.groupby(['user_id','coupon_id'])['date_received'].agg(lambda x:':'.join(x)).reset_index()
t6.rename(columns={'date_received':'dates'},inplace=True)
def get_day_gap_before(s):
date_received,dates = s.split('-')
dates = dates.split(':')
gaps = []
for d in dates:
this_gap = (date(int(date_received[0:4]),int(date_received[4:6]),int(date_received[6:8]))-date(int(d[0:4]),int(d[4:6]),int(d[6:8]))).days
if this_gap>0:
gaps.append(this_gap)
if len(gaps)==0:
return -1
else:
return min(gaps)
def get_day_gap_after(s):
date_received,dates = s.split('-')
dates = dates.split(':')
gaps = []
for d in dates:
this_gap = (date(int(d[0:4]),int(d[4:6]),int(d[6:8]))-date(int(date_received[0:4]),int(date_received[4:6]),int(date_received[6:8]))).days
if this_gap>0:
gaps.append(this_gap)
if len(gaps)==0:
return -1
else:
return min(gaps)
t7 = dataset2[['user_id','coupon_id','date_received']]
# =============================================================================
# t7=t7.drop([0])
# t7=t7[['user_id','coupon_id','date_received']]
# =============================================================================
t7 = pd.merge(t7,t6,on=['user_id','coupon_id'],how='left')
t7['date_received_date'] = t7.date_received.astype('str') + '-' + t7.dates
t7['day_gap_before'] = t7.date_received_date.apply(get_day_gap_before)
t7['day_gap_after'] = t7.date_received_date.apply(get_day_gap_after)
t7 = t7[['user_id','coupon_id','date_received','day_gap_before','day_gap_after']]
other_feature2 = pd.merge(t1,t,on='user_id')
other_feature2 = pd.merge(other_feature2,t3,on=['user_id','coupon_id'])
other_feature2 = pd.merge(other_feature2,t4,on=['user_id','date_received'])
other_feature2 = pd.merge(other_feature2,t5,on=['user_id','coupon_id','date_received'])
other_feature2 = pd.merge(other_feature2,t7,on=['user_id','coupon_id','date_received'])
other_feature2.to_csv('data/other_feature2.csv',index=None)
print(other_feature2.shape)
#for dataset1
t = dataset1[['user_id']]
t['this_month_user_receive_all_coupon_count'] = 1
t = t.groupby('user_id').agg('sum').reset_index()
t1 = dataset1[['user_id','coupon_id']]
t1['this_month_user_receive_same_coupon_count'] = 1
t1 = t1.groupby(['user_id','coupon_id']).agg('sum').reset_index()
t2 = dataset1[['user_id','coupon_id','date_received']]
t2.date_received = t2.date_received.astype('str')
t2 = t2.groupby(['user_id','coupon_id'])['date_received'].agg(lambda x:':'.join(x)).reset_index()
t2['receive_number'] = t2.date_received.apply(lambda s:len(s.split(':')))
t2 = t2[t2.receive_number>1]
t2['max_date_received'] = t2.date_received.apply(lambda s:max([int(d) for d in s.split(':')]))
t2['min_date_received'] = t2.date_received.apply(lambda s:min([int(d) for d in s.split(':')]))
t2 = t2[['user_id','coupon_id','max_date_received','min_date_received']]
t3 = dataset1[['user_id','coupon_id','date_received']]
# =============================================================================
# t3=t3.drop([0])
# t3=t3[['user_id','coupon_id','date_received']]
# =============================================================================
t3 = pd.merge(t3,t2,on=['user_id','coupon_id'],how='left')
t3['this_month_user_receive_same_coupon_lastone'] = t3.max_date_received - t3.date_received.astype('int')
t3['this_month_user_receive_same_coupon_firstone'] = t3.date_received.astype('int') - t3.min_date_received
def is_firstlastone(x):
if x==0:
return 1
elif x>0:
return 0
else:
return -1 #those only receive once
t3.this_month_user_receive_same_coupon_lastone = t3.this_month_user_receive_same_coupon_lastone.apply(is_firstlastone)
t3.this_month_user_receive_same_coupon_firstone = t3.this_month_user_receive_same_coupon_firstone.apply(is_firstlastone)
t3 = t3[['user_id','coupon_id','date_received','this_month_user_receive_same_coupon_lastone','this_month_user_receive_same_coupon_firstone']]
t4 = dataset1[['user_id','date_received']]
t4['this_day_user_receive_all_coupon_count'] = 1
t4 = t4.groupby(['user_id','date_received']).agg('sum').reset_index()
t5 = dataset1[['user_id','coupon_id','date_received']]
t5['this_day_user_receive_same_coupon_count'] = 1
t5 = t5.groupby(['user_id','coupon_id','date_received']).agg('sum').reset_index()
t6 = dataset1[['user_id','coupon_id','date_received']]
t6.date_received = t6.date_received.astype('str')
t6 = t6.groupby(['user_id','coupon_id'])['date_received'].agg(lambda x:':'.join(x)).reset_index()
t6.rename(columns={'date_received':'dates'},inplace=True)
def get_day_gap_before(s):
date_received,dates = s.split('-')
dates = dates.split(':')
gaps = []
for d in dates:
this_gap = (date(int(date_received[0:4]),int(date_received[4:6]),int(date_received[6:8]))-date(int(d[0:4]),int(d[4:6]),int(d[6:8]))).days
if this_gap>0:
gaps.append(this_gap)
if len(gaps)==0:
return -1
else:
return min(gaps)
def get_day_gap_after(s):
date_received,dates = s.split('-')
dates = dates.split(':')
gaps = []
for d in dates:
this_gap = (date(int(d[0:4]),int(d[4:6]),int(d[6:8]))-date(int(date_received[0:4]),int(date_received[4:6]),int(date_received[6:8]))).days
if this_gap>0:
gaps.append(this_gap)
if len(gaps)==0:
return -1
else:
return min(gaps)
t7 = dataset1[['user_id','coupon_id','date_received']]
# =============================================================================
# t7=t7.drop([0])
# t7=t7[['user_id','coupon_id','date_received']]
# =============================================================================
t7 = pd.merge(t7,t6,on=['user_id','coupon_id'],how='left')
t7['date_received_date'] = t7.date_received.astype('str') + '-' + t7.dates
t7['day_gap_before'] = t7.date_received_date.apply(get_day_gap_before)
t7['day_gap_after'] = t7.date_received_date.apply(get_day_gap_after)
t7 = t7[['user_id','coupon_id','date_received','day_gap_before','day_gap_after']]
other_feature1 = pd.merge(t1,t,on='user_id')
other_feature1 = pd.merge(other_feature1,t3,on=['user_id','coupon_id'])
other_feature1 = pd.merge(other_feature1,t4,on=['user_id','date_received'])
other_feature1 = pd.merge(other_feature1,t5,on=['user_id','coupon_id','date_received'])
other_feature1 = pd.merge(other_feature1,t7,on=['user_id','coupon_id','date_received'])
other_feature1.to_csv('data/other_feature1.csv',index=None)
print( other_feature1.shape)############# coupon related feature #############
"""
2.coupon related:
discount_rate. discount_man. discount_jian. is_man_jian
day_of_week,day_of_month. (date_received)
"""
def calc_discount_rate(s):
s =str(s)
s = s.split(':')
if len(s)==1:
return float(s[0])
else:
return 1.0-float(s[1])/float(s[0])
def get_discount_man(s):
s =str(s)
s = s.split(':')
if len(s)==1:
return 'null'
else:
return int(s[0])
def get_discount_jian(s):
s =str(s)
s = s.split(':')
if len(s)==1:
return 'null'
else:
return int(s[1])
def is_man_jian(s):
s =str(s)
s = s.split(':')
if len(s)==1:
return 0
else:
return 1
#dataset3
#20171220本月的第3周
dataset3=dataset3.drop([0])
dataset3=dataset3[['user_id','merchant_id','coupon_id','discount_rate','distance','date_received']]
dataset3['day_of_week'] = dataset3.date_received.astype('str').apply(lambda x:date(int(x[0:4]),int(x[4:6]),int(x[6:8])).weekday()+1)
#20171220本月的第20天
dataset3['day_of_month'] = dataset3.date_received.astype('str').apply(lambda x:int(x[6:8]))
dataset3['days_distance'] = dataset3.date_received.astype('str').apply(lambda x:(date(int(x[0:4]),int(x[4:6]),int(x[6:8]))-date(2016,6,30)).days)
#显示满了多少钱后开始减
dataset3['discount_man'] = dataset3.discount_rate.apply(get_discount_man)
#显示满减的减少的钱
dataset3['discount_jian'] = dataset3.discount_rate.apply(get_discount_jian)
#显示是否满减
dataset3['is_man_jian'] = dataset3.discount_rate.apply(is_man_jian)
dataset3['discount_rate'] = dataset3.discount_rate.apply(calc_discount_rate)
d = dataset3[['coupon_id']]
d['coupon_count'] = 1
d = d.groupby('coupon_id').agg('sum').reset_index()
dataset3 = pd.merge(dataset3,d,on='coupon_id',how='left')
dataset3.to_csv('data/coupon3_feature.csv',index=None)
#dataset2
dataset2['day_of_week'] = dataset2.date_received.astype('str').apply(lambda x:date(int(x[0:4]),int(x[4:6]),int(x[6:8])).weekday()+1)
dataset2['day_of_month'] = dataset2.date_received.astype('str').apply(lambda x:int(x[6:8]))
dataset2['days_distance'] = dataset2.date_received.astype('str').apply(lambda x:(date(int(x[0:4]),int(x[4:6]),int(x[6:8]))-date(2016,5,14)).days)
dataset2['discount_man'] = dataset2.discount_rate.apply(get_discount_man)
dataset2['discount_jian'] = dataset2.discount_rate.apply(get_discount_jian)
dataset2['is_man_jian'] = dataset2.discount_rate.apply(is_man_jian)
dataset2['discount_rate'] = dataset2.discount_rate.apply(calc_discount_rate)
d = dataset2[['coupon_id']]
d['coupon_count'] = 1
d = d.groupby('coupon_id').agg('sum').reset_index()
dataset2 = pd.merge(dataset2,d,on='coupon_id',how='left')
dataset2.to_csv('data/coupon2_feature.csv',index=None)
#dataset1
dataset1['day_of_week'] = dataset1.date_received.astype('str').apply(lambda x:date(int(x[0:4]),int(x[4:6]),int(x[6:8])).weekday()+1)
dataset1['day_of_month'] = dataset1.date_received.astype('str').apply(lambda x:int(x[6:8]))
dataset1['days_distance'] = dataset1.date_received.astype('str').apply(lambda x:(date(int(x[0:4]),int(x[4:6]),int(x[6:8]))-date(2016,4,13)).days)
dataset1['discount_man'] = dataset1.discount_rate.apply(get_discount_man)
dataset1['discount_jian'] = dataset1.discount_rate.apply(get_discount_jian)
dataset1['is_man_jian'] = dataset1.discount_rate.apply(is_man_jian)
dataset1['discount_rate'] = dataset1.discount_rate.apply(calc_discount_rate)
d = dataset1[['coupon_id']]
d['coupon_count'] = 1
d = d.groupby('coupon_id').agg('sum').reset_index()
dataset1 = pd.merge(dataset1,d,on='coupon_id',how='left')
dataset1.to_csv('data/coupon1_feature.csv',index=None)感谢第一名的代码
机器学习实践-O2O优惠券预测-思路总结/

相关文章推荐
- 天池大赛o2o优惠券第一名代码笔记之_extral_feature(2)
- 天池大赛o2o优惠券第一名代码笔记之_xgb
- 天池大赛o2o优惠券第一名代码解读(4)
- 天池大赛o2o优惠券第一名代码解读(2)
- 天池大赛o2o优惠券第一名代码解读(4)
- 2016天池-O2O优惠券使用预测竞赛总结
- 这是世界编程大赛第一名编写的程序,有谁能看懂这段代码 DOS下执行Debug<a.txt
- 天池大赛o2o优惠券第一名代码解读(1)
- 『 天池竞赛』O2O优惠券使用预测思路总结
- 天池新人实战赛o2o优惠券使用预测二
- 这是世界编程大赛第一名编写的程序,有谁能看懂这段代码
- 天池比赛:o2o优惠券使用预测
- 天池新人实战赛o2o优惠券结果记录(随时更新)
- 天池新人实战赛o2o优惠券使用预测三
- [天池竞赛系列]O2O优惠券使用预测复赛第三名思路
- 《天池》大数据机器学习竞赛-O2O优惠券使用预测
- 25行AS3代码编程大赛的第一名!25行代码构造的AS3游戏
- bootstrap 学习笔记 - 2 (排版+代码 样式)
- java学习笔记之代码块
- 第一行代码学习笔记---过时的通知写法