Spark-sql 读hbase
2017-12-15 00:00
309 查看
SparkSQL是指整合了Hive的spark-sql cli, 本质上就是通过Hive访问HBase表,具体就是通过hive-hbase-handler
拷贝HBase的相关jar包到Spark节点上的$SPARK_HOME/lib目录下,清单如下:
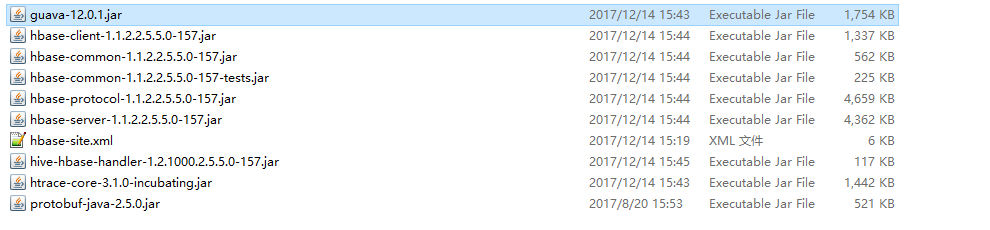
在 ambari 上配置Spark节点的$SPARK_HOME/conf/spark-env.sh,将上面的jar包添加到SPARK_CLASSPATH,如下图:
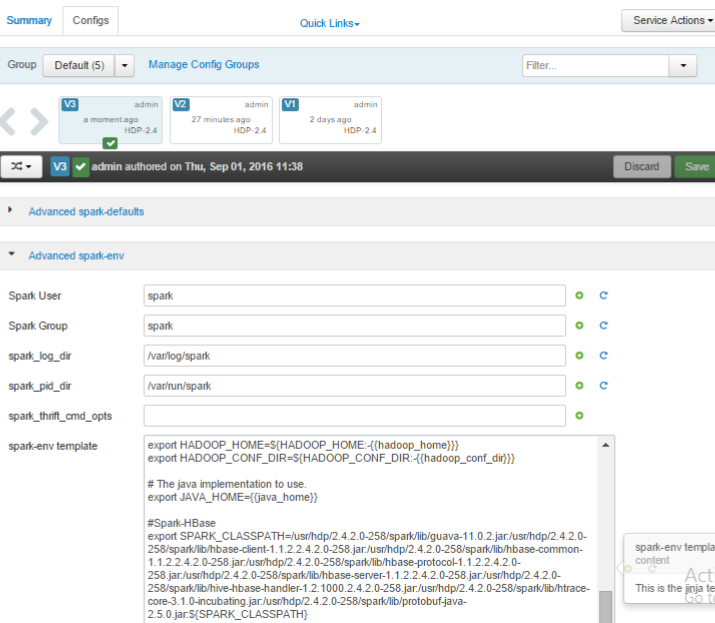
配置项清单如下:注意jar包之间不能有空格或回车符
export SPARK_CLASSPATH=/usr/hdp/2.5.5.0-157/spark/lib/guava-12.0.1.jar:/usr/hdp/2.5.5.0-157/spark/lib/hbase-client-1.1.2.2.5.5.0-157.jar:/usr/hdp/2.5.5.0-157/spark/lib/hbase-common-1.1.2.2.5.5.0-157.jar:/usr/hdp/2.5.5.0-157/spark/lib/hbase-protocol-1.1.2.2.5.5.0-157.jar:/usr/hdp/2.5.5.0-157/spark/lib/hbase-server-1.1.2.2.5.5.0-157.jar:/usr/hdp/2.5.5.0-157/spark/lib/hive-hbase-handler-1.2.1000.2.5.5.0-157.jar:/usr/hdp/2.5.5.0-157/spark/lib/htrace-core-3.1.0-incubating.jar:/usr/hdp/2.5.5.0-157/spark/lib/protobuf-java-2.5.0.jar:${SPARK_CLASSPATH}
将hbase-site.xml拷贝至${HADOOP_CONF_DIR},由于spark-env.sh中配置了Hadoop配置文件目录${HADOOP_CONF_DIR},因此会将hbase-site.xml加载。
在ambari 上重启修改配置后影响的组件服务
测试验证:
任一spark client节点验证:
命令: park-sql
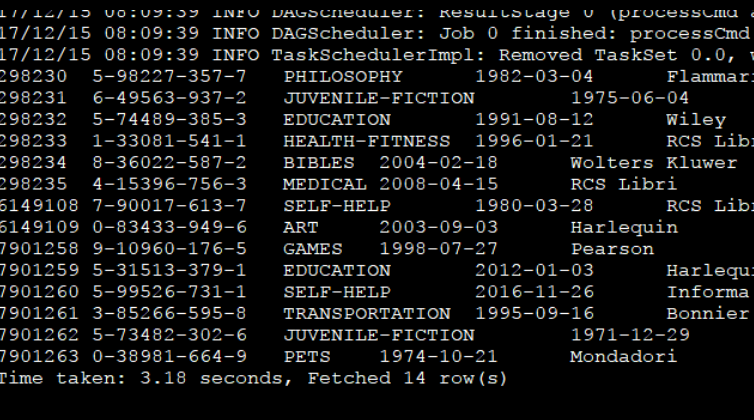
执行: select * from books_hive; (books_hive为与hbase关联的hive外部表)
结果如下则OK:
拷贝HBase的相关jar包到Spark节点上的$SPARK_HOME/lib目录下,清单如下:
在 ambari 上配置Spark节点的$SPARK_HOME/conf/spark-env.sh,将上面的jar包添加到SPARK_CLASSPATH,如下图:
配置项清单如下:注意jar包之间不能有空格或回车符
export SPARK_CLASSPATH=/usr/hdp/2.5.5.0-157/spark/lib/guava-12.0.1.jar:/usr/hdp/2.5.5.0-157/spark/lib/hbase-client-1.1.2.2.5.5.0-157.jar:/usr/hdp/2.5.5.0-157/spark/lib/hbase-common-1.1.2.2.5.5.0-157.jar:/usr/hdp/2.5.5.0-157/spark/lib/hbase-protocol-1.1.2.2.5.5.0-157.jar:/usr/hdp/2.5.5.0-157/spark/lib/hbase-server-1.1.2.2.5.5.0-157.jar:/usr/hdp/2.5.5.0-157/spark/lib/hive-hbase-handler-1.2.1000.2.5.5.0-157.jar:/usr/hdp/2.5.5.0-157/spark/lib/htrace-core-3.1.0-incubating.jar:/usr/hdp/2.5.5.0-157/spark/lib/protobuf-java-2.5.0.jar:${SPARK_CLASSPATH}
将hbase-site.xml拷贝至${HADOOP_CONF_DIR},由于spark-env.sh中配置了Hadoop配置文件目录${HADOOP_CONF_DIR},因此会将hbase-site.xml加载。
在ambari 上重启修改配置后影响的组件服务
测试验证:
任一spark client节点验证:
命令: park-sql
执行: select * from books_hive; (books_hive为与hbase关联的hive外部表)
结果如下则OK:

相关文章推荐
- 从HBase数据库表中读取数据动态转为DataFrame格式,方便后续用Spark SQL操作(scala实现)
- 通过自定义SparkSQL外部数据源实现SparkSQL读取HBase
- Spark(四): Spark-sql 读hbase
- 开源Astro(SparkSQL On HBase)
- spark-sql读取映射hbase数据的hive外部表
- spark学习-17-Java版SparkSQL程序读取Hbase表注册成表SQL查询
- 基于Hbase的Spark Sql示例 一
- spark-sql读取映射hbase数据的hive外部表
- SparkSQL+Hbase+HDFS实现SQL完全封装(一)
- Astro —— 华为开源的 SparkSQL on HBase
- spark sql读hbase
- Spark(四): Spark-sql 读hbase
- sqoop连接hbase以及spark sql使用
- SparkSQL读取HBase数据,通过自定义外部数据源(hbase的Hive外关联表)
- 大数据平台安装测试(1)centos7.1 docker mesos tachyon hadoop (myriad? yarn?)spark hbase speaksql 选型分析
- SparkSQL读HBase的数据
- Spark(四): Spark-sql 读hbase
- spark学习-SparkSQL--11-scala版写的SparkSQL程序读取Hbase表注册成表SQL查询
- spark hbase读写
- Spark SQL概念与组成概述