打通钉钉+WebHook:日志服务告警升级
2017-12-13 00:00
375 查看
摘要: 用一个最最常用的案例(Nginx日志分析)来说明当前使用场景,告警要解决的3个问题:是否有错误;是否有性能问题;是否有流量急跌或暴涨
阿里云日志服务是针对实时数据一站式服务,用户只需要将精力集中在分析上,过程中数据采集、对接各种存储计算、数据索引和查询等琐碎工作等都可以交给日志服务完成。
9月日志服务升级实时分析功能(LogSearch/Analytics),可以使用查询+SQL92语法对日志进行实时分析,并在结果分析可视化上,支持自带Dashboard、DataV、Grafana、Tableua(通过JDBC)、QuickBI等可视化方式。
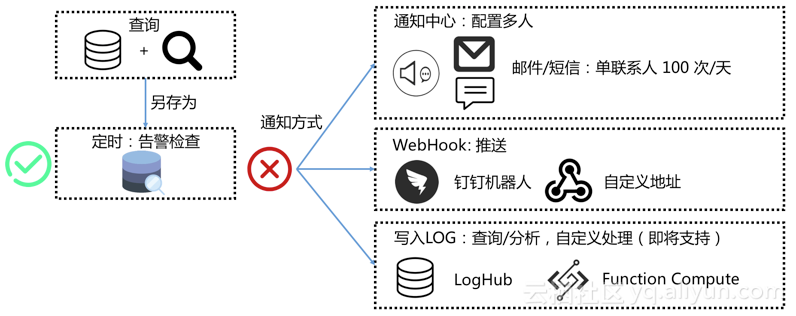
在监控场景中光有可视化是不够的,日志服务提供告警与通知功能如下:
将查询(SavedSearch)保存下来
对查询设置触发周期(间隔),并对执行结果设定判断条件并且告警
设置告警动作(如何通知),目前支持通知方式有3种:
通知中心:在阿里云通知中心可以设置多个联系人,通知会通过邮件和短信方式发送
WebHook:包括钉钉机器人,及自定义WebHook等
(即将支持)写回日志服务(logstore):可以通过流计算,函数服务进行事件订阅;也可以对告警生成视图和报表
告警功能配置与使用可以参见告警文档。
是否有错误
是否有性能问题
是否有流量急跌或暴涨
索引设置,详细步骤请参考索引设置与可视化或最佳实践网站日志分析案例。
对关键指标设置视图 + 告警。
(在做完1、2步骤后,在查询页面可以看到原始日志)
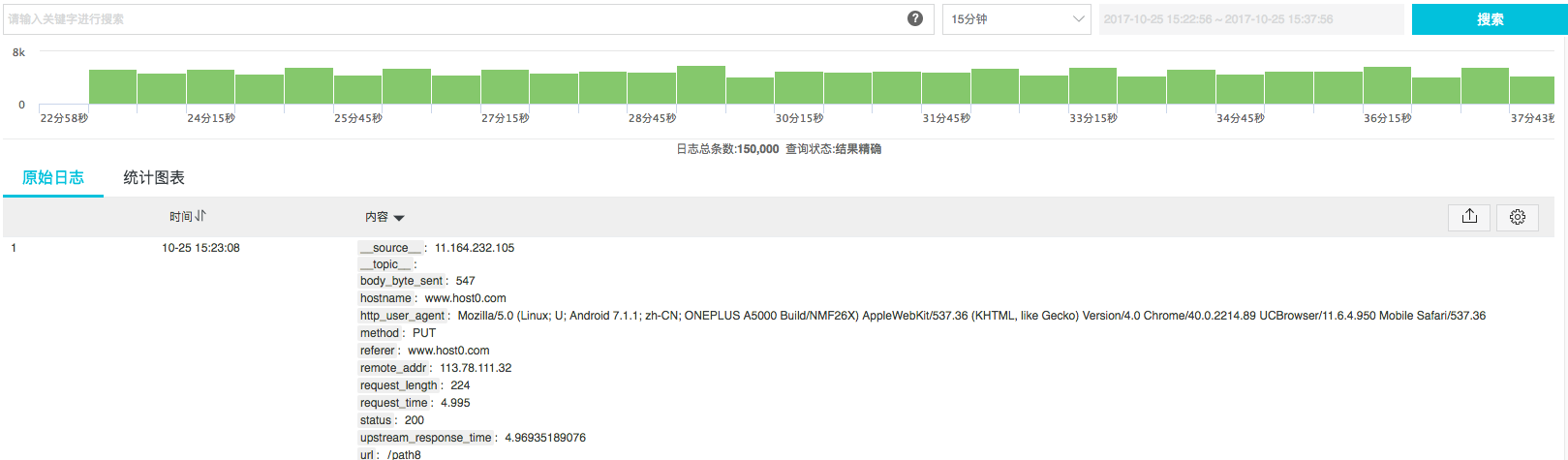
Sample视图(例子):
这种方式比较简单,但往往过于敏感,对于一些业务压力较大的服务而言有零星几个500是正常的。为了应对这种情况,我们可以在告警条件中设置触发次数为2次:只有连续2次检查都符合条件后再发告警。
例如我们可以通过以下方式计算某个接口(“/adduser")所有写请求(”Post“)延时。告警规则设置为 l > 300000 (当平均值超过300ms后告警)。
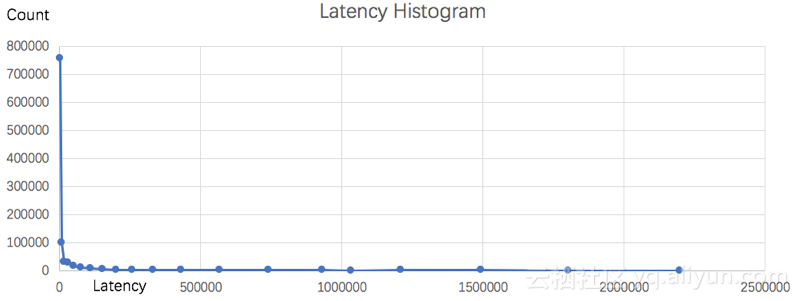
利用平均值来报警简单而直接,但这种方法往往会使得一些个体请求延时被平均掉,反馈不出问题。例如我们对该时间段的Latency可以计算一个数学上的分布(划分20个区间,计算每个区间内的数目),从分布图上可以看到大部分请求延时非常低(<20ms),但最高的延时有2.5S。
为应对这种情况,我们可以用数学上的百分数(99%最大延时)来作为报警条件,这样既可以排除偶发的延时高引起误报,也能对整体的演示更有代表性。以下的语句计算了99%分位的延时大小 approx_percentile(Latency, 0.99) ,同样我们也可以修改第二个参数进行其他分位的划分,例如中位数的请求延时 approx_percentile(Latency, 0.5)
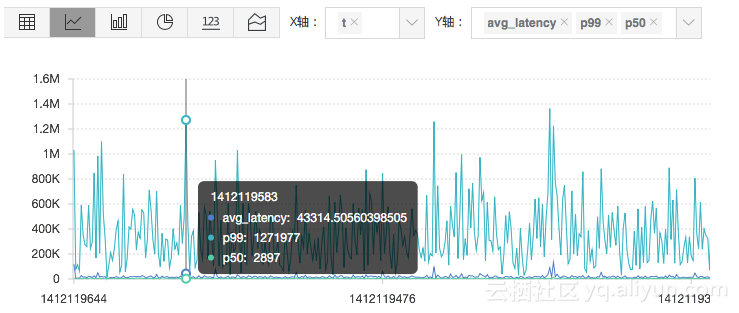
在监控的场景中,我们也可以在一个图上绘出平均延时,50%分位延时,以及90%分位延时。以下是按一天的窗口(1440分钟)统计各分钟内延时的图:
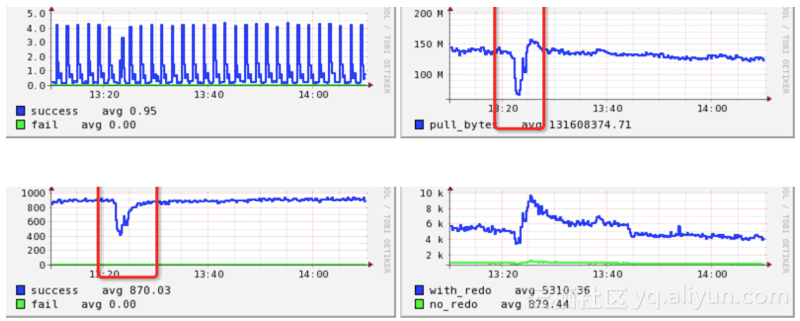
(例如下图的监控中,在2分钟时间内流量大小下跌30%以上,在2分钟内后又迅速恢复)
急跌和暴涨一般会有如下参考系:
上一个时间窗口:环比上一个时间段
上一天该时间段的窗口:环比昨天
上一周该时间段的窗口:环比上周
我们这里以第一种情况来作为case讨论,计算流量infow数据的变动率(也可以换成QPS等流量)。
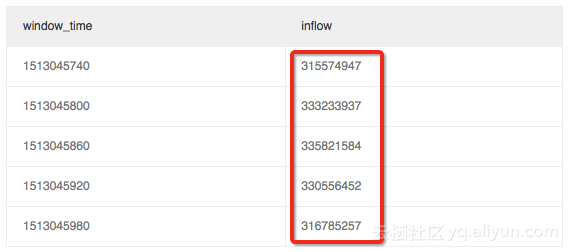
从结果分布上看,每个窗口内的平均流量 sum(inflow)/(max(__time__)-min(__time__)) 应该是均匀的:
注意:
这里的max_by函数计算结果为字符类型,我们需要强转成数字类型
如果要计算变化相对率,可以用(1.0-max_by(inflow, window_time)/1.0/avg(inflow)) as lastest_ratio 代替
阿里云日志服务是针对实时数据一站式服务,用户只需要将精力集中在分析上,过程中数据采集、对接各种存储计算、数据索引和查询等琐碎工作等都可以交给日志服务完成。
9月日志服务升级实时分析功能(LogSearch/Analytics),可以使用查询+SQL92语法对日志进行实时分析,并在结果分析可视化上,支持自带Dashboard、DataV、Grafana、Tableua(通过JDBC)、QuickBI等可视化方式。
在监控场景中光有可视化是不够的,日志服务提供告警与通知功能如下:
将查询(SavedSearch)保存下来
对查询设置触发周期(间隔),并对执行结果设定判断条件并且告警
设置告警动作(如何通知),目前支持通知方式有3种:
通知中心:在阿里云通知中心可以设置多个联系人,通知会通过邮件和短信方式发送
WebHook:包括钉钉机器人,及自定义WebHook等
(即将支持)写回日志服务(logstore):可以通过流计算,函数服务进行事件订阅;也可以对告警生成视图和报表
告警功能配置与使用可以参见告警文档。
告警设置案例(Nginx日志为例)
我们用一个最最常用的案例(Nginx日志分析)来说明当前使用场景,告警要解决的3个问题:是否有错误
是否有性能问题
是否有流量急跌或暴涨
准备工作(Nginx日志接入)
日志数据采集。详细步骤请参考5分钟快速入门 或 直接在Logstore页面 数据源接入向导 中设置。索引设置,详细步骤请参考索引设置与可视化或最佳实践网站日志分析案例。
对关键指标设置视图 + 告警。
(在做完1、2步骤后,在查询页面可以看到原始日志)
Sample视图(例子):
1. 是否有错误
错误一般有这样几类:404(请求无法找到地址)/502/500(服务端错误),我们一般只需关心500(服务端错误),将这个query保存下来,统计单位时间内错误数c。告警可以设定一个规则c > 0 则产生告警:status:500 | select count(1) as c
这种方式比较简单,但往往过于敏感,对于一些业务压力较大的服务而言有零星几个500是正常的。为了应对这种情况,我们可以在告警条件中设置触发次数为2次:只有连续2次检查都符合条件后再发告警。
2. 是否有性能问题
服务器运行过程中虽然没有错误,但有可能会出现延迟(Latency)增大情况,因此我们可以针对延迟进行告警。例如我们可以通过以下方式计算某个接口(“/adduser")所有写请求(”Post“)延时。告警规则设置为 l > 300000 (当平均值超过300ms后告警)。
Method:Post and URL:"/adduser" | select avg(Latency) as l
利用平均值来报警简单而直接,但这种方法往往会使得一些个体请求延时被平均掉,反馈不出问题。例如我们对该时间段的Latency可以计算一个数学上的分布(划分20个区间,计算每个区间内的数目),从分布图上可以看到大部分请求延时非常低(<20ms),但最高的延时有2.5S。
Method:Post and URL:"/adduser" | select numeric_histogram(20, Latency)
为应对这种情况,我们可以用数学上的百分数(99%最大延时)来作为报警条件,这样既可以排除偶发的延时高引起误报,也能对整体的演示更有代表性。以下的语句计算了99%分位的延时大小 approx_percentile(Latency, 0.99) ,同样我们也可以修改第二个参数进行其他分位的划分,例如中位数的请求延时 approx_percentile(Latency, 0.5)
Method:Post and URL:"/adduser" | select approx_percentile(Latency, 0.99) as p99
在监控的场景中,我们也可以在一个图上绘出平均延时,50%分位延时,以及90%分位延时。以下是按一天的窗口(1440分钟)统计各分钟内延时的图:
* | select avg(Latency) as l, approx_percentile(Latency, 0.5) as p50, approx_percentile(Latency, 0.99) as p99, date_trunc('minute', time) as t group by t order by t desc limit 14403. 是否有流量急跌或暴涨?
服务器端自然流量一般符合概率上的分布,会有一个缓慢上涨或下降过程。流量急跌或暴涨(短时间内变化非常大)一般都是不正常的现象,需要留意。(例如下图的监控中,在2分钟时间内流量大小下跌30%以上,在2分钟内后又迅速恢复)
急跌和暴涨一般会有如下参考系:
上一个时间窗口:环比上一个时间段
上一天该时间段的窗口:环比昨天
上一周该时间段的窗口:环比上周
我们这里以第一种情况来作为case讨论,计算流量infow数据的变动率(也可以换成QPS等流量)。
3.1 首先定义一个计算窗口
例如我们定一个1分钟的窗口,统计该分钟内的流量大小,以下是一个5分钟区间统计:* | select sum(inflow)/(max(__time__)-min(__time__)) as inflow , __time__-__time__%60 as window_time from log group by window_time order by window_time limit 15
从结果分布上看,每个窗口内的平均流量 sum(inflow)/(max(__time__)-min(__time__)) 应该是均匀的:
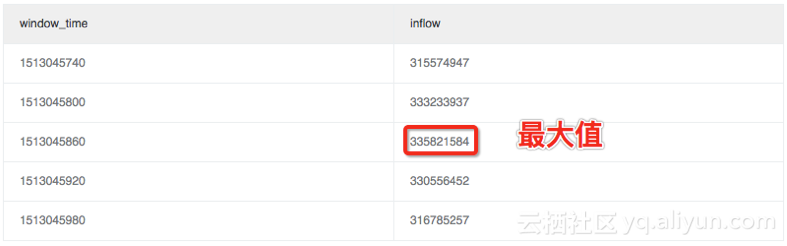
3.2 计算窗口内的差异值(最大值变化率)
这里我们会用到子查询,我们写一个查询,从上述结果中计算最大值 或 最小值 与平均值的变化率(这里的max_ratio),例如如下计算结果max_ratio 为 1.02。我们可以定义一个告警规则,如果max_ratio > 1.5 (变化率超过50%)就告警。* | select max(inflow)/avg(inflow) as max_ratio from (select sum(inflow)/(max(__time__)-min(__time__)) as inflow , __time__-__time__%60 as window_time from log group by window_time order by window_time limit 15)
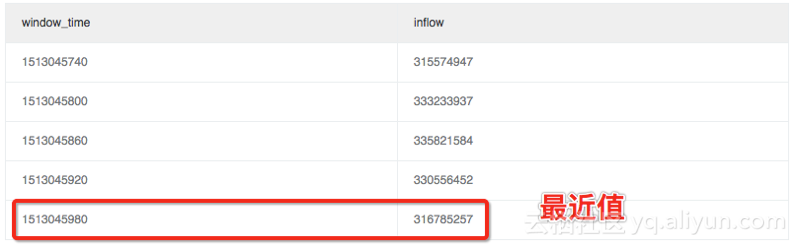
3.3 计算窗口内的差异值(最近值变化率)
在一些场景中我们更关注最新的数值是否有波动(是否已经恢复),那可以通过max_by方法获取最大windows_time中的流量来进行判断,这里计算的最近值为lastest_ratio=0.97。注意:
这里的max_by函数计算结果为字符类型,我们需要强转成数字类型
如果要计算变化相对率,可以用(1.0-max_by(inflow, window_time)/1.0/avg(inflow)) as lastest_ratio 代替
* | select max_by(inflow, window_time)/1.0/avg(inflow) as lastest_ratio from (select sum(inflow)/(max(__time__)-min(__time__)) as inflow , __time__-__time__%60 as window_time from log group by window_time order by window_time limit 15)
总结
日志服务查询分析能力是完整SQL92,支持各种数理统计与计算等,只要会用SQL都能进行快速分析,欢迎尝试!
相关文章推荐
- 打通钉钉+WebHook:日志服务告警升级
- RHEL4- WEB服务(八)Web服务的日志分析
- RHEL5.4 部署web日志分析服务之awstats+jawstats
- 通过 Github-Webhook 实现的轻量级自动化构建Nodejs微服务
- Web文件批量上传控件升级日志-Xproer.HttpUploader
- API信息全掌控,方便你的日志管理——阿里云推出API网关打通日志服务
- Web大文件上传断点续传控件4升级日志-Xproer.HttpUploader4
- Web图片上传控件(x64)升级日志-Xproer.ImageUploader64
- 导入文件的三种方式及分析web服务日志计算元素字节大小案例
- hdfs web_ui深入讲解、服务启动日志分析、NN SNN关系
- Web截屏插件专业版升级日志-Xproer.ScreenCapturePro
- API信息全掌控,方便你的日志管理——阿里云推出API网关打通日志服务
- API信息全掌控,方便你的日志管理——阿里云推出API网关打通日志服务
- web日志服务
- web服务监控邮件告警python程序
- Web图片上传控件(Chrome)升级日志-Xproer.ImageUploader
- Web断点续传控件5升级日志-Xproer.HttpUploader5
- 提高WEB服务响应时间by优化日志打印
- Web截屏插件标准版升级日志.Xproer.ScreenCapture
- Web图片编辑控件升级日志-Xproer.ImageEditor