C++11:互斥锁对程序性能的影响
2017-12-12 10:26
281 查看
在多线程中,对数据的保护机制,我们用到了互斥量、临界区、读写锁、条件变量等方法。一直以来都有些担心锁会降低程序的性能,尽管它是必须的,但究竟它能降低多少呢?那只有靠数据说话,下面的代码是2个线程同时操作一个变量:class TestA
{
public:
explicit TestA() {}
explicit TestA(int n) : _cnt(n)
{
_count = 0;
_max = 0xFFFF;
_tBegin = GetTickCount();
}
~TestA() {}
void BeginThread()
{
_thrd1.SetLoopInterval(1);
_thrd1._funcRunLoop = [this](void* p) {
unique_lock<std::mutex> lck(_mt);
if (_cnt >= _max)
{
_tEnd = GetTickCount();
cout << endl << "耗时:" << _tEnd - _tBegin << endl;
cout << endl << "执行次数:" << _count << endl;
return false;
}
_cnt -= 1;
_count++;
cout << _cnt << "\t";
return true;
};
_thrd1.Start();
_thrd2.SetLoopInterval(1);
_thrd2._funcRunLoop = [this](void* p) {
unique_lock<std::mutex> lck(_mt);
if (_cnt >= _max)
{
_tEnd = GetTickCount();
cout << endl << "耗时:" << _tEnd - _tBegin << endl;
cout << endl << "执行次数:" << _count << endl;
return false;
}
_cnt += 2;
_count++;
cout << _cnt << "\t";
return true;
};
_thrd2.Start();
}
void StopThread()
{
_thrd1.Stop();
_thrd2.Stop();
}
private:
int _cnt, _max, _count;
DWORD _tBegin, _tEnd;
std::mutex _mt;
LoopThread<TestA> _thrd1;
LoopThread<TestA> _thrd2;
};
int main()
{
TestA ta(1);
ta.BeginThread();
getchar();
ta.StopThread();
return 0;
}
注释:LoopThread是我封装的一个C++11线程类执行上面的程序耗时65692毫秒,如下图所示:
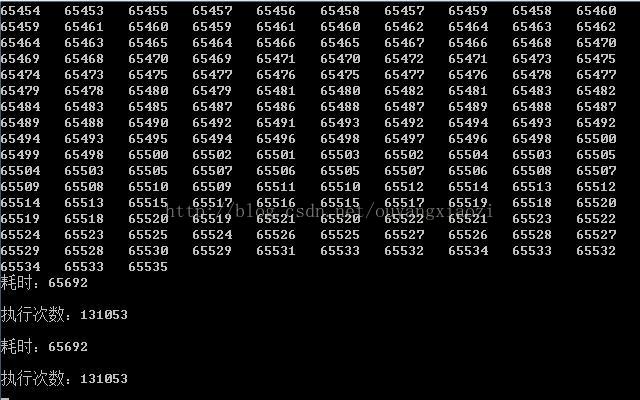
注意:每次执行耗费的时间都不大相同,但差别不是很大
将线程中锁去掉后(即这行代码:unique_lock<std::mutex> lck(_mt)),执行上述程序耗时65646毫秒,如下图所示:
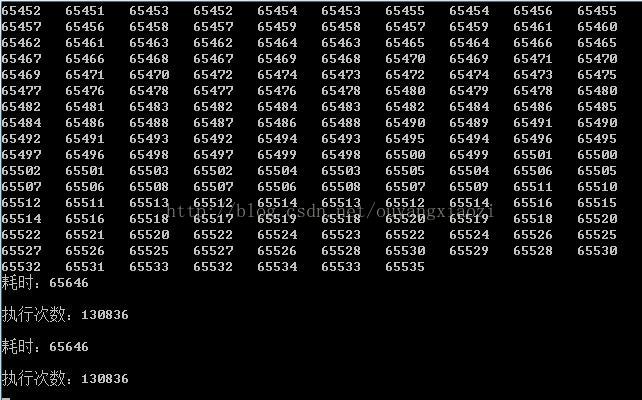
总结1:2个线程总共执行了大概130435~130836次,添加互斥锁耗时(65692毫秒)-没有互斥锁耗时(65646毫秒)= 46毫秒,也就是说执行1000次互斥锁大概耗时0.35毫秒,这差别微乎其微。
而且大家注意到没,没有加锁的情况下,线程执行的次数(130836次)要比加锁执行的次数(131053)要少,如果按照每次执行线程函数所耗时计算,添加互斥锁每次执行时间:65692 / 131053 = 0.5012628478554478(毫秒/次),没添加互斥锁每次执行时间:65646 / 130836 = 0.5017426396404659(毫秒/次),这样算来添加了互斥锁每次执行的时间反而较少(当然了,输出的数据每次都有微小的差别)。
总结2:从以上数据可以看出,C++11互斥锁机制的效率还是很高的,几乎不怎么占用时间,所以以后不用担心锁机制带来的效率降低的问题了。
{
public:
explicit TestA() {}
explicit TestA(int n) : _cnt(n)
{
_count = 0;
_max = 0xFFFF;
_tBegin = GetTickCount();
}
~TestA() {}
void BeginThread()
{
_thrd1.SetLoopInterval(1);
_thrd1._funcRunLoop = [this](void* p) {
unique_lock<std::mutex> lck(_mt);
if (_cnt >= _max)
{
_tEnd = GetTickCount();
cout << endl << "耗时:" << _tEnd - _tBegin << endl;
cout << endl << "执行次数:" << _count << endl;
return false;
}
_cnt -= 1;
_count++;
cout << _cnt << "\t";
return true;
};
_thrd1.Start();
_thrd2.SetLoopInterval(1);
_thrd2._funcRunLoop = [this](void* p) {
unique_lock<std::mutex> lck(_mt);
if (_cnt >= _max)
{
_tEnd = GetTickCount();
cout << endl << "耗时:" << _tEnd - _tBegin << endl;
cout << endl << "执行次数:" << _count << endl;
return false;
}
_cnt += 2;
_count++;
cout << _cnt << "\t";
return true;
};
_thrd2.Start();
}
void StopThread()
{
_thrd1.Stop();
_thrd2.Stop();
}
private:
int _cnt, _max, _count;
DWORD _tBegin, _tEnd;
std::mutex _mt;
LoopThread<TestA> _thrd1;
LoopThread<TestA> _thrd2;
};
int main()
{
TestA ta(1);
ta.BeginThread();
getchar();
ta.StopThread();
return 0;
}
注释:LoopThread是我封装的一个C++11线程类执行上面的程序耗时65692毫秒,如下图所示:
注意:每次执行耗费的时间都不大相同,但差别不是很大
将线程中锁去掉后(即这行代码:unique_lock<std::mutex> lck(_mt)),执行上述程序耗时65646毫秒,如下图所示:
总结1:2个线程总共执行了大概130435~130836次,添加互斥锁耗时(65692毫秒)-没有互斥锁耗时(65646毫秒)= 46毫秒,也就是说执行1000次互斥锁大概耗时0.35毫秒,这差别微乎其微。
而且大家注意到没,没有加锁的情况下,线程执行的次数(130836次)要比加锁执行的次数(131053)要少,如果按照每次执行线程函数所耗时计算,添加互斥锁每次执行时间:65692 / 131053 = 0.5012628478554478(毫秒/次),没添加互斥锁每次执行时间:65646 / 130836 = 0.5017426396404659(毫秒/次),这样算来添加了互斥锁每次执行的时间反而较少(当然了,输出的数据每次都有微小的差别)。
总结2:从以上数据可以看出,C++11互斥锁机制的效率还是很高的,几乎不怎么占用时间,所以以后不用担心锁机制带来的效率降低的问题了。

相关文章推荐
- 关于import中使用*号是否会影响程序性能
- 论数据库连接的创建与关闭对程序性能的影响数量级
- cache line 对程序性能的影响
- 处理器对程序性能的影响
- C++11改进程序性能 move forward
- 程序中使用now()函数对性能的影响
- C# 程序性能提升篇-2、类型(字段类型、class和struct)的错误定义所影响性能浅析
- C#中使用try...catch...是否会影响程序性能
- 选择排序法 当数据量较小的时候,使用基本排序方案并不会显著影响程序性能。 选择排序是十分常用的基本排序方案之一。
- NSLog对程序性能的影响
- Try-Catch真的会影响程序性能吗
- Java中一个方法字节码的长度会影响程序并发下的性能?
- Try-Catch真的会影响程序性能吗
- 程序性能优化之 内存分配影响
- 五个瓶颈影响你的Asp.Net程序(网站)性能
- SQL对程序性能的影响
- 高速缓存对程序性能的影响
- 使用jvisualvm监控JAVA程序,注意对程序性能的影响
- 选择排序法 当数据量较小的时候,使用基本排序方案并不会显著影响程序性能。 选择排序是十分常用的基本排序方案之一。
- 页面输出太多会严重影响web程序的性能