人工智障学习笔记——机器学习(9)最大期望算法
2017-12-07 20:16
441 查看
一.概念
最大期望算法,也就是著名的em算法,他起源于一条dog

没错,就是这个

好吧不扯蛋了,em算法(Expectation Maximization Algorithm,又译期望最大化算法),是一种迭代算法,用于含有隐变量(latent variable)的概率参数模型的最大似然估计或极大后验概率估计。在机器学习中,最大期望(EM)算法用于在概率(probabilistic)模型中寻找参数最大似然估计或者最大后验估计的算法,其中概率模型依赖于无法观测的隐藏变量(Latent Variable)。
最大似然估计:
这个概念解释起来非常简单,就是你调皮捣蛋天天搞事,别人家孩子学习优秀各种听话。所以一旦说出个什么坏事家长们总是认为是你干的,因为你之前干坏事的概率比较大。这是一个比较通俗的栗子,更装逼的解释请参考百度百科。
二.算法
最大期望算法经过两个步骤交替进行计算:
第一步是计算期望(E),利用概率模型参数的现有估计值,计算隐藏变量的期望;
第二步是最大化(M),利用E 步上求得的隐藏变量的期望,对参数模型进行最大似然估计。
M 步上找到的参数估计值被用于下一个 E 步计算中,这个过程不断交替进行。
总体来说,EM的算法流程如下:
1.初始化分布参数
2.重复直到收敛:
E步骤:估计未知参数的期望值,给出当前的参数估计。
M步骤:重新估计分布参数,以使得数据的似然性最大,给出未知变量的期望估计。
通过交替使用这两个步骤,EM算法逐步改进模型的参数,使参数和训练样本的似然概率逐渐增大,最后终止于一个极大点。直观地理解EM算法,它也可被看作为一个逐次逼近算法:事先并不知道模型的参数,可以随机的选择一套参数或者事先粗略地给定某个初始参数λ0 ,确定出对应于这组参数的最可能的状态,计算每个训练样本的可能结果的概率,在当前的状态下再由样本对参数修正,重新估计参数λ,并在新的参数下重新确定模型的状态,这样,通过多次的迭代,循环直至某个收敛条件满足为止,就可以使得模型的参数逐渐逼近真实参数。
EM算法的主要目的是提供一个简单的迭代算法计算后验密度函数,它的最大优点是简单和稳定,但容易陷入局部最优。
三.实现
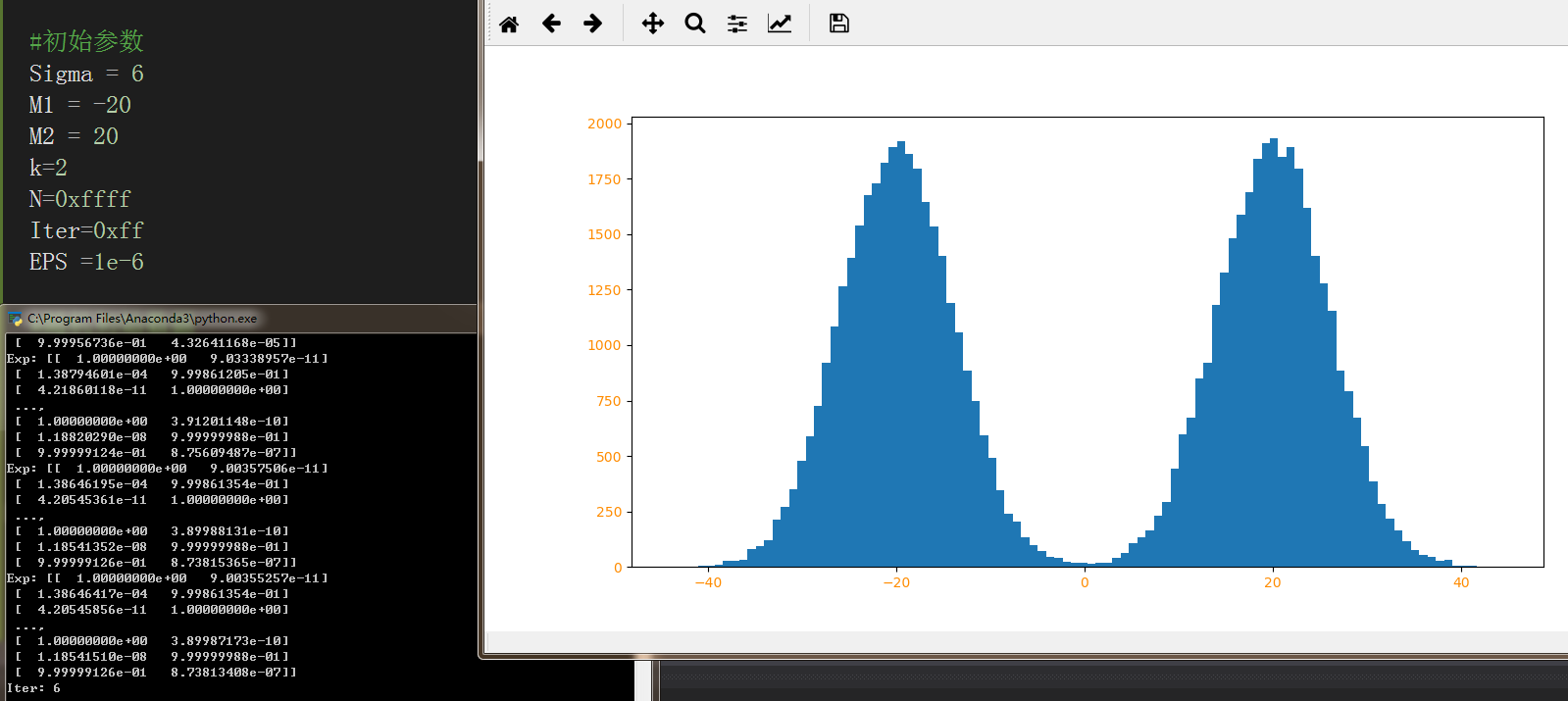
模拟2个正态分布的均值预计:
四.总结
EM算法思路非常简单,就是我们想估计A和B两个参数,在开始状态下二者都是未知的,但如果知道了A的信息就可以得到B的信息,反过来知道了B也就得到了A。可以考虑首先赋予A某种初值,以此得到B的估计值,然后从B的当前值出发,重新估计A的取值,这个过程一直持续到收敛为止。
EM算法和K均值算法有些类似,都是数据存在一个或多个聚集中心点,在这个点附近,样本数量明显较多。K均值算法目的是寻找聚点,EM算法的目的是估计样本的概率分布等统计参数或数据。但如果数据分散,没有明显的聚点,或者数据呈现方式比较奇葩,那么K均值和EM算法就很难派上用场了。
五.相关学习资源
http://m.blog.csdn.net/u010866505/article/details/77877345
https://www.cnblogs.com/slgkaifa/p/6731779.html
http://blog.csdn.net/zouxy09/article/details/8537620
最大期望算法,也就是著名的em算法,他起源于一条dog
没错,就是这个
好吧不扯蛋了,em算法(Expectation Maximization Algorithm,又译期望最大化算法),是一种迭代算法,用于含有隐变量(latent variable)的概率参数模型的最大似然估计或极大后验概率估计。在机器学习中,最大期望(EM)算法用于在概率(probabilistic)模型中寻找参数最大似然估计或者最大后验估计的算法,其中概率模型依赖于无法观测的隐藏变量(Latent Variable)。
最大似然估计:
这个概念解释起来非常简单,就是你调皮捣蛋天天搞事,别人家孩子学习优秀各种听话。所以一旦说出个什么坏事家长们总是认为是你干的,因为你之前干坏事的概率比较大。这是一个比较通俗的栗子,更装逼的解释请参考百度百科。
二.算法
最大期望算法经过两个步骤交替进行计算:
第一步是计算期望(E),利用概率模型参数的现有估计值,计算隐藏变量的期望;
第二步是最大化(M),利用E 步上求得的隐藏变量的期望,对参数模型进行最大似然估计。
M 步上找到的参数估计值被用于下一个 E 步计算中,这个过程不断交替进行。
总体来说,EM的算法流程如下:
1.初始化分布参数
2.重复直到收敛:
E步骤:估计未知参数的期望值,给出当前的参数估计。
M步骤:重新估计分布参数,以使得数据的似然性最大,给出未知变量的期望估计。
通过交替使用这两个步骤,EM算法逐步改进模型的参数,使参数和训练样本的似然概率逐渐增大,最后终止于一个极大点。直观地理解EM算法,它也可被看作为一个逐次逼近算法:事先并不知道模型的参数,可以随机的选择一套参数或者事先粗略地给定某个初始参数λ0 ,确定出对应于这组参数的最可能的状态,计算每个训练样本的可能结果的概率,在当前的状态下再由样本对参数修正,重新估计参数λ,并在新的参数下重新确定模型的状态,这样,通过多次的迭代,循环直至某个收敛条件满足为止,就可以使得模型的参数逐渐逼近真实参数。
EM算法的主要目的是提供一个简单的迭代算法计算后验密度函数,它的最大优点是简单和稳定,但容易陷入局部最优。
三.实现
模拟2个正态分布的均值预计:
import math
import copy
import numpy as np
import matplotlib.pyplot as plt
isdebug = True
# 指定k个高斯分布參数。这里指定k=2。注意2个高斯分布具有同样均方差Sigma,分别为M1,M2。
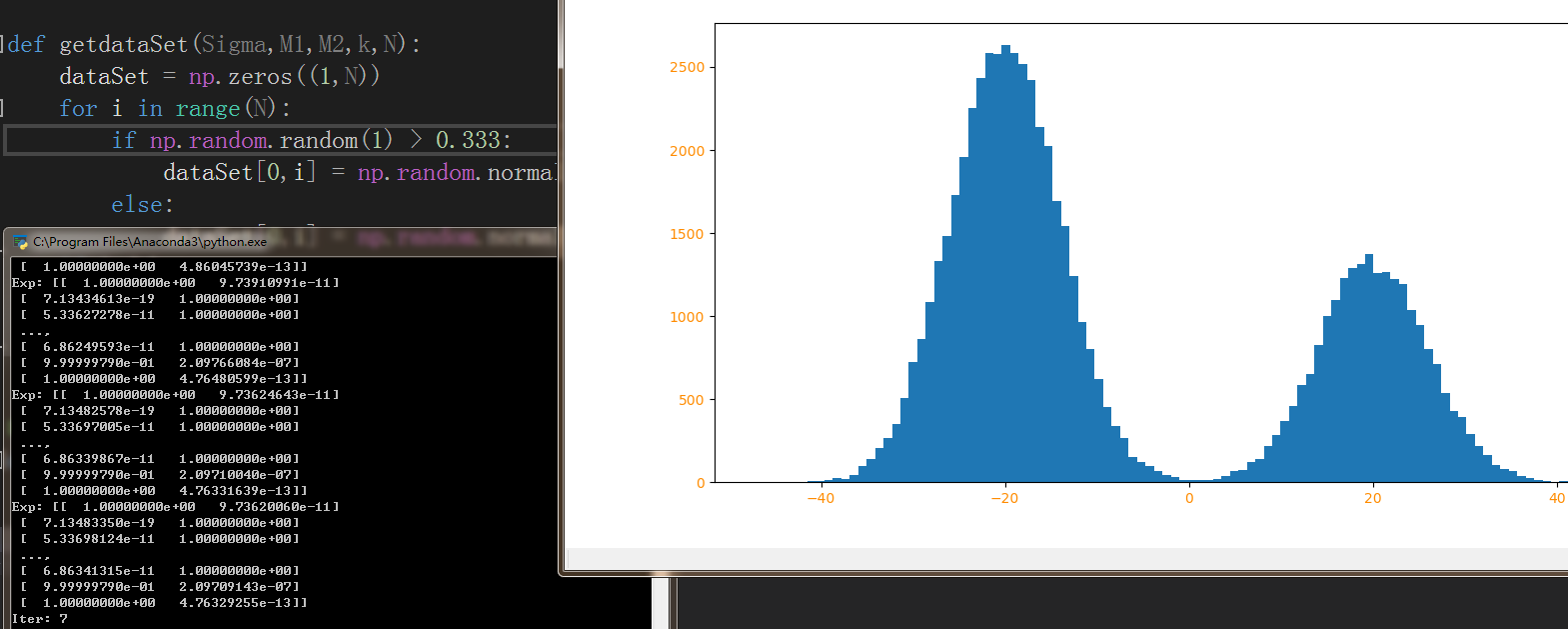
def getdataSet(Sigma,M1,M2,k,N):
dataSet = np.zeros((1,N))
for i in range(N):
if np.random.random(1) > 0.333:
dataSet[0,i] = np.random.normal()*Sigma + M1
else:
dataSet[0,i] = np.random.normal()*Sigma + M2
if isdebug:
print ("dataSet:",dataSet)
return dataSet
# E算法:计算期望E[zij]
def E(Sigma,dataSet,Miu,k,N):
Exp = np.zeros((N,k))
Num = np.zeros(k)
for i in range(N):
Sum = 0
for j in range(k):
Num[j] = math.exp((-1/(2*(float(Sigma**2))))*(float(dataSet[0,i]-Miu[j]))**2)
Sum += Num[j]
for j in range(k):
Exp[i,j] = Num[j] / Sum
if isdebug:
print ("Exp:",Exp)
return Exp
# M算法:最大化E[zij]的參数Miu
def M(Exp,dataSet,k,N):
Miu = np.random.random(2)
for j in range(k):
Num = 0
Sum = 0
for i in range(N):
Num += Exp[i,j]*dataSet[0,i]
Sum += Exp[i,j]
Miu[j] = Num / Sum
return Miu
#初始参数
Sigma = 6
M1 = -20
M2 = 20
k=2
N=0xffff
Iter=0xff
EPS =1e-6
#随机初始数据
dataSet=getdataSet(Sigma,M1,M2,k,N)
#初始先假设一个E[zij]
Miu = np.random.random(2)
# 算法迭代
for i in range(Iter):
oldMiu = copy.deepcopy(Miu)
#E
Exp = E(Sigma,dataSet,Miu,k,N)
#M
Miu = M(Exp,dataSet,k,N)
#如果达到精度Epsilon停止迭代
if sum(abs(Miu-oldM
c3ec
iu)) < EPS:
if isdebug:
print ("Iter:",i)
break
plt.figure('emmmmm',figsize=(12, 6))
plt.hist(dataSet[0,:],100)
plt.xticks(fontsize=10, color="darkorange")
plt.yticks(fontsize=10, color="darkorange")
plt.show()四.总结
EM算法思路非常简单,就是我们想估计A和B两个参数,在开始状态下二者都是未知的,但如果知道了A的信息就可以得到B的信息,反过来知道了B也就得到了A。可以考虑首先赋予A某种初值,以此得到B的估计值,然后从B的当前值出发,重新估计A的取值,这个过程一直持续到收敛为止。
EM算法和K均值算法有些类似,都是数据存在一个或多个聚集中心点,在这个点附近,样本数量明显较多。K均值算法目的是寻找聚点,EM算法的目的是估计样本的概率分布等统计参数或数据。但如果数据分散,没有明显的聚点,或者数据呈现方式比较奇葩,那么K均值和EM算法就很难派上用场了。
五.相关学习资源
http://m.blog.csdn.net/u010866505/article/details/77877345
https://www.cnblogs.com/slgkaifa/p/6731779.html
http://blog.csdn.net/zouxy09/article/details/8537620

相关文章推荐
- 人工智障学习笔记——机器学习(8)K均值聚类
- 人工智障学习笔记——机器学习(11)PCA降维
- 人工智障学习笔记——机器学习(2)线性模型
- 人工智障学习笔记——机器学习(12)LDA降维
- 人工智障学习笔记——机器学习(15)t-SNE降维
- 人工智障学习笔记——机器学习(16)降维小结
- 人工智障学习笔记——机器学习(1)特征工程
- 人工智障学习笔记——机器学习(3)决策树
- 人工智障学习笔记——机器学习(7)FM/FFM
- 人工智障学习笔记——机器学习(14)mds&isomap降维
- 人工智障学习笔记——强化学习(1)马尔科夫决策过程
- 人工智障学习笔记——强化学习(2)基于模型的DP方法
- 【机器学习-斯坦福】学习笔记14 主成分分析(Principal components analysis)-最大方差解释
- 人工智障学习笔记——强化学习(5)DRL与DQN
- Tom Mitchell 机器学习 — 学习笔记(1)
- 机器学习校招笔记3:集成学习之Adaboost
- [iphone 开发学习笔记]Object-C和C语言最大的区别也是最大的扩展-----消息(即如何调用一个对象中的函数)
- Coursera 机器学习(by Andrew Ng)课程学习笔记 Week 8(二)——降维
- 机器学习深度学习基础笔记(1)——基础理论
- 学习笔记---机器学习技法